 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPCANet++: Deep Interpretable Robust PCA for Sparse Object Segmentation
Aug 06, 2025
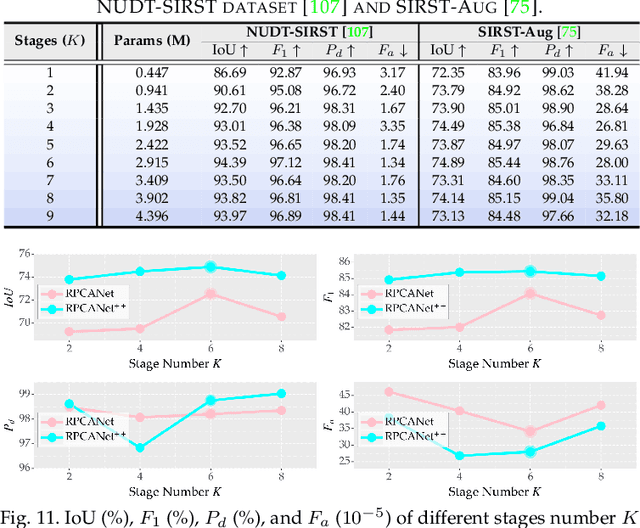

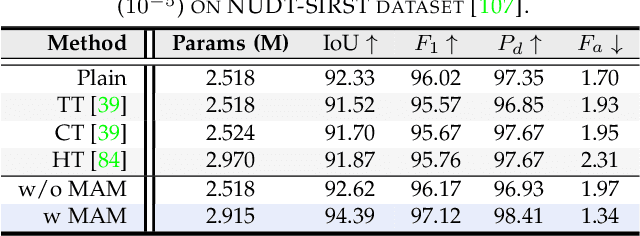
Robust principal component analysis (RPCA) decomposes an observation matrix into low-rank background and sparse object components. This capability has enabled its application in tasks ranging from image restoration to segmentation. However, traditional RPCA models suffer from computational burdens caused by matrix operations, reliance on finely tuned hyperparameters, and rigid priors that limit adaptability in dynamic scenarios. To solve these limitations, we propose RPCANet++, a sparse object segmentation framework that fuses the interpretability of RPCA with efficient deep architectures. Our approach unfolds a relaxed RPCA model into a structured network comprising a Background Approximation Module (BAM), an Object Extraction Module (OEM), and an Image Restoration Module (IRM). To mitigate inter-stage transmission loss in the BAM, we introduce a Memory-Augmented Module (MAM) to enhance background feature preservation, while a Deep Contrast Prior Module (DCPM) leverages saliency cues to expedite object extraction. Extensive experiments on diverse datasets demonstrate that RPCANet++ achieves state-of-the-art performance under various imaging scenarios. We further improve interpretability via visual and numerical low-rankness and sparsity measurements. By combining the theoretical strengths of RPCA with the efficiency of deep networks, our approach sets a new baseline for reliable and interpretable sparse object segmentation. Codes are available at our Project Webpage https://fengyiwu98.github.io/rpcanetx.
Bayesian Optimization for Controlled Image Editing via LLMs
Feb 26, 2025



In the rapidly evolving field of image generation, achieving precise control over generated content and maintaining semantic consistency remain significant limitations, particularly concerning grounding techniques and the necessity for model fine-tuning. To address these challenges, we propose BayesGenie, an off-the-shelf approach that integrates Large Language Models (LLMs) with Bayesian Optimization to facilitate precise and user-friendly image editing. Our method enables users to modify images through natural language descriptions without manual area marking, while preserving the original image's semantic integrity. Unlike existing techniques that require extensive pre-training or fine-tuning, our approach demonstrates remarkable adaptability across various LLMs through its model-agnostic design. BayesGenie employs an adapted Bayesian optimization strategy to automatically refine the inference process parameters, achieving high-precision image editing with minimal user intervention. Through extensive experiments across diverse scenarios, we demonstrate that our framework significantly outperforms existing methods in both editing accuracy and semantic preservation, as validated using different LLMs including Claude3 and GPT-4.
Human Motion Instruction Tuning
Nov 25, 2024



This paper presents LLaMo (Large Language and Human Motion Assistant), a multimodal framework for human motion instruction tuning. In contrast to conventional instruction-tuning approaches that convert non-linguistic inputs, such as video or motion sequences, into language tokens, LLaMo retains motion in its native form for instruction tuning. This method preserves motion-specific details that are often diminished in tokenization, thereby improving the model's ability to interpret complex human behaviors. By processing both video and motion data alongside textual inputs, LLaMo enables a flexible, human-centric analysis. Experimental evaluations across high-complexity domains, including human behaviors and professional activities, indicate that LLaMo effectively captures domain-specific knowledge, enhancing comprehension and prediction in motion-intensive scenarios. We hope LLaMo offers a foundation for future multimodal AI systems with broad applications, from sports analytics to behavioral prediction. Our code and models are available on the project website: https://github.com/ILGLJ/LLaMo.
The Role of Deductive and Inductive Reasoning in Large Language Models
Oct 03, 2024



Large Language Models (LLMs) have achieved substantial progress in artificial intelligence, particularly in reasoning tasks. However, their reliance on static prompt structures, coupled with limited dynamic reasoning capabilities, often constrains their adaptability to complex and evolving problem spaces. In this paper, we propose the Deductive and InDuctive(DID) method, which enhances LLM reasoning by dynamically integrating both deductive and inductive reasoning within the prompt construction process. Drawing inspiration from cognitive science, the DID approach mirrors human adaptive reasoning mechanisms, offering a flexible framework that allows the model to adjust its reasoning pathways based on task context and performance. We empirically validate the efficacy of DID on established datasets such as AIW and MR-GSM8K, as well as on our custom dataset, Holiday Puzzle, which presents tasks about different holiday date calculating challenges. By leveraging DID's hybrid prompt strategy, we demonstrate significant improvements in both solution accuracy and reasoning quality, achieved without imposing substantial computational overhead. Our findings suggest that DID provides a more robust and cognitively aligned framework for reasoning in LLMs, contributing to the development of advanced LLM-driven problem-solving strategies informed by cognitive science models.
CAS-ViT: Convolutional Additive Self-attention Vision Transformers for Efficient Mobile Applications
Aug 07, 2024



Vision Transformers (ViTs) mark a revolutionary advance in neural networks with their token mixer's powerful global context capability. However, the pairwise token affinity and complex matrix operations limit its deployment on resource-constrained scenarios and real-time applications, such as mobile devices, although considerable efforts have been made in previous works. In this paper, we introduce CAS-ViT: Convolutional Additive Self-attention Vision Transformers, to achieve a balance between efficiency and performance in mobile applications. Firstly, we argue that the capability of token mixers to obtain global contextual information hinges on multiple information interactions, such as spatial and channel domains. Subsequently, we construct a novel additive similarity function following this paradigm and present an efficient implementation named Convolutional Additive Token Mixer (CATM). This simplification leads to a significant reduction in computational overhead. We evaluate CAS-ViT across a variety of vision tasks, including image classification, object detection, instance segmentation, and semantic segmentation. Our experiments, conducted on GPUs, ONNX, and iPhones, demonstrate that CAS-ViT achieves a competitive performance when compared to other state-of-the-art backbones, establishing it as a viable option for efficient mobile vision applications. Our code and model are available at: \url{https://github.com/Tianfang-Zhang/CAS-ViT}
ScalingGaussian: Enhancing 3D Content Creation with Generative Gaussian Splatting
Jul 26, 2024



The creation of high-quality 3D assets is paramount for applications in digital heritage preservation, entertainment, and robotics. Traditionally, this process necessitates skilled professionals and specialized software for the modeling, texturing, and rendering of 3D objects. However, the rising demand for 3D assets in gaming and virtual reality (VR) has led to the creation of accessible image-to-3D technologies, allowing non-professionals to produce 3D content and decreasing dependence on expert input. Existing methods for 3D content generation struggle to simultaneously achieve detailed textures and strong geometric consistency. We introduce a novel 3D content creation framework, ScalingGaussian, which combines 3D and 2D diffusion models to achieve detailed textures and geometric consistency in generated 3D assets. Initially, a 3D diffusion model generates point clouds, which are then densified through a process of selecting local regions, introducing Gaussian noise, followed by using local density-weighted selection. To refine the 3D gaussians, we utilize a 2D diffusion model with Score Distillation Sampling (SDS) loss, guiding the 3D Gaussians to clone and split. Finally, the 3D Gaussians are converted into meshes, and the surface textures are optimized using Mean Square Error(MSE) and Gradient Profile Prior(GPP) losses. Our method addresses the common issue of sparse point clouds in 3D diffusion, resulting in improved geometric structure and detailed textures. Experiments on image-to-3D tasks demonstrate that our approach efficiently generates high-quality 3D assets.
Tree Counting by Bridging 3D Point Clouds with Imagery
Mar 12, 2024



Accurate and consistent methods for counting trees based on remote sensing data are needed to support sustainable forest management, assess climate change mitigation strategies, and build trust in tree carbon credits. Two-dimensional remote sensing imagery primarily shows overstory canopy, and it does not facilitate easy differentiation of individual trees in areas with a dense canopy and does not allow for easy separation of trees when the canopy is dense. We leverage the fusion of three-dimensional LiDAR measurements and 2D imagery to facilitate the accurate counting of trees. We compare a deep learning approach to counting trees in forests using 3D airborne LiDAR data and 2D imagery. The approach is compared with state-of-the-art algorithms, like operating on 3D point cloud and 2D imagery. We empirically evaluate the different methods on the NeonTreeCount data set, which we use to define a tree-counting benchmark. The experiments show that FuseCountNet yields more accurate tree counts.
MedFLIP: Medical Vision-and-Language Self-supervised Fast Pre-Training with Masked Autoencoder
Mar 07, 2024Within the domain of medical analysis, extensive research has explored the potential of mutual learning between Masked Autoencoders(MAEs) and multimodal data. However, the impact of MAEs on intermodality remains a key challenge. We introduce MedFLIP, a Fast Language-Image Pre-training method for Medical analysis. We explore MAEs for zero-shot learning with crossed domains, which enhances the model ability to learn from limited data, a common scenario in medical diagnostics. We verify that masking an image does not affect intermodal learning. Furthermore, we propose the SVD loss to enhance the representation learning for characteristics of medical images, aiming to improve classification accuracy by leveraging the structural intricacies of such data. Lastly, we validate using language will improve the zero-shot performance for the medical image analysis. MedFLIP scaling of the masking process marks an advancement in the field, offering a pathway to rapid and precise medical image analysis without the traditional computational bottlenecks. Through experiments and validation, MedFLIP demonstrates efficient performance improvements, setting an explored standard for future research and application in medical diagnostics.
DisDet: Exploring Detectability of Backdoor Attack on Diffusion Models
Feb 05, 2024
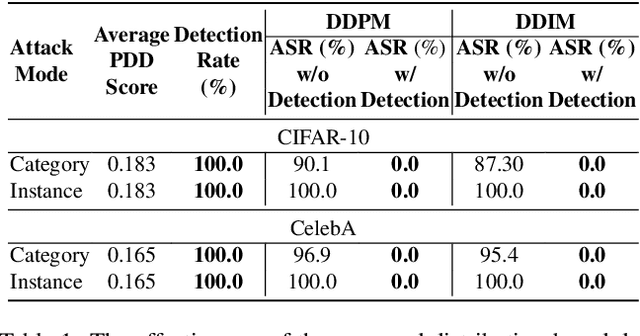

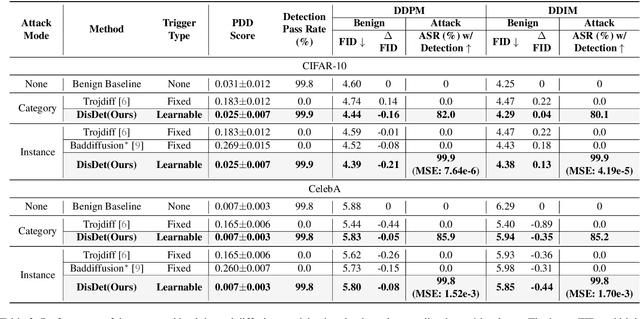
In the exciting generative AI era, the diffusion model has emerged as a very powerful and widely adopted content generation and editing tool for various data modalities, making the study of their potential security risks very necessary and critical. Very recently, some pioneering works have shown the vulnerability of the diffusion model against backdoor attacks, calling for in-depth analysis and investigation of the security challenges of this popular and fundamental AI technique. In this paper, for the first time, we systematically explore the detectability of the poisoned noise input for the backdoored diffusion models, an important performance metric yet little explored in the existing works. Starting from the perspective of a defender, we first analyze the properties of the trigger pattern in the existing diffusion backdoor attacks, discovering the important role of distribution discrepancy in Trojan detection. Based on this finding, we propose a low-cost trigger detection mechanism that can effectively identify the poisoned input noise. We then take a further step to study the same problem from the attack side, proposing a backdoor attack strategy that can learn the unnoticeable trigger to evade our proposed detection scheme. Empirical evaluations across various diffusion models and datasets demonstrate the effectiveness of the proposed trigger detection and detection-evading attack strategy. For trigger detection, our distribution discrepancy-based solution can achieve a 100\% detection rate for the Trojan triggers used in the existing works. For evading trigger detection, our proposed stealthy trigger design approach performs end-to-end learning to make the distribution of poisoned noise input approach that of benign noise, enabling nearly 100\% detection pass rate with very high attack and benign performance for the backdoored diffusion models.
RPCANet: Deep Unfolding RPCA Based Infrared Small Target Detection
Nov 02, 2023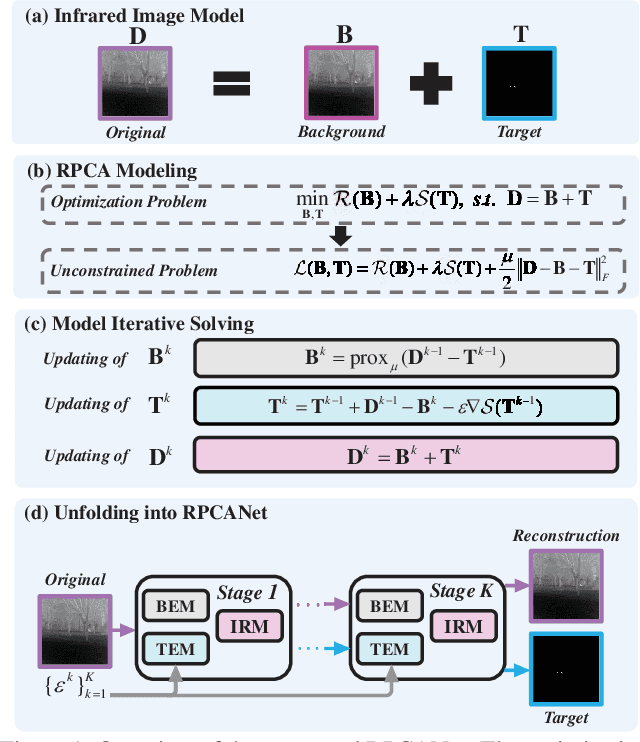
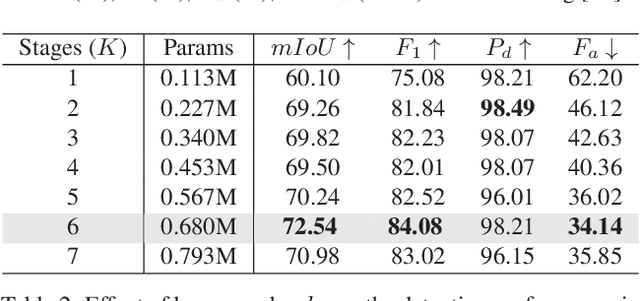
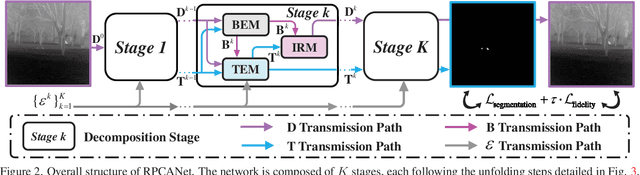
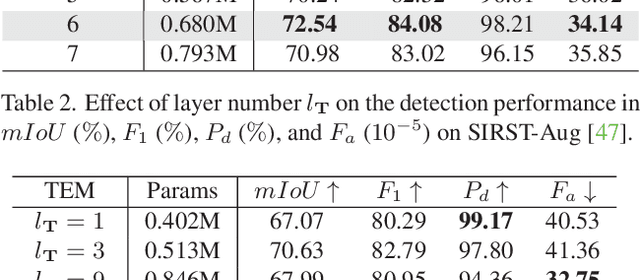
Deep learning (DL) networks have achieved remarkable performance in infrared small target detection (ISTD). However, these structures exhibit a deficiency in interpretability and are widely regarded as black boxes, as they disregard domain knowledge in ISTD. To alleviate this issue, this work proposes an interpretable deep network for detecting infrared dim targets, dubbed RPCANet. Specifically, our approach formulates the ISTD task as sparse target extraction, low-rank background estimation, and image reconstruction in a relaxed Robust Principle Component Analysis (RPCA) model. By unfolding the iterative optimization updating steps into a deep-learning framework, time-consuming and complex matrix calculations are replaced by theory-guided neural networks. RPCANet detects targets with clear interpretability and preserves the intrinsic image feature, instead of directly transforming the detection task into a matrix decomposition problem. Extensive experiments substantiate the effectiveness of our deep unfolding framework and demonstrate its trustworthy results, surpassing baseline methods in both qualitative and quantitative evaluations.