 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAU-Blendshape for Fine-grained Stylized 3D Facial Expression Manipulation
Jul 16, 2025



While 3D facial animation has made impressive progress, challenges still exist in realizing fine-grained stylized 3D facial expression manipulation due to the lack of appropriate datasets. In this paper, we introduce the AUBlendSet, a 3D facial dataset based on AU-Blendshape representation for fine-grained facial expression manipulation across identities. AUBlendSet is a blendshape data collection based on 32 standard facial action units (AUs) across 500 identities, along with an additional set of facial postures annotated with detailed AUs. Based on AUBlendSet, we propose AUBlendNet to learn AU-Blendshape basis vectors for different character styles. AUBlendNet predicts, in parallel, the AU-Blendshape basis vectors of the corresponding style for a given identity mesh, thereby achieving stylized 3D emotional facial manipulation. We comprehensively validate the effectiveness of AUBlendSet and AUBlendNet through tasks such as stylized facial expression manipulation, speech-driven emotional facial animation, and emotion recognition data augmentation. Through a series of qualitative and quantitative experiments, we demonstrate the potential and importance of AUBlendSet and AUBlendNet in 3D facial animation tasks. To the best of our knowledge, AUBlendSet is the first dataset, and AUBlendNet is the first network for continuous 3D facial expression manipulation for any identity through facial AUs. Our source code is available at https://github.com/wslh852/AUBlendNet.git.
Wav2Sem: Plug-and-Play Audio Semantic Decoupling for 3D Speech-Driven Facial Animation
May 29, 2025In 3D speech-driven facial animation generation, existing methods commonly employ pre-trained self-supervised audio models as encoders. However, due to the prevalence of phonetically similar syllables with distinct lip shapes in language, these near-homophone syllables tend to exhibit significant coupling in self-supervised audio feature spaces, leading to the averaging effect in subsequent lip motion generation. To address this issue, this paper proposes a plug-and-play semantic decorrelation module-Wav2Sem. This module extracts semantic features corresponding to the entire audio sequence, leveraging the added semantic information to decorrelate audio encodings within the feature space, thereby achieving more expressive audio features. Extensive experiments across multiple Speech-driven models indicate that the Wav2Sem module effectively decouples audio features, significantly alleviating the averaging effect of phonetically similar syllables in lip shape generation, thereby enhancing the precision and naturalness of facial animations. Our source code is available at https://github.com/wslh852/Wav2Sem.git.
Position-aware Guided Point Cloud Completion with CLIP Model
Dec 11, 2024
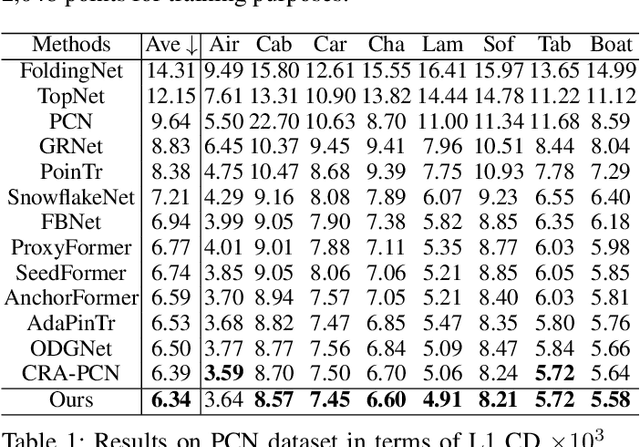


Point cloud completion aims to recover partial geometric and topological shapes caused by equipment defects or limited viewpoints. Current methods either solely rely on the 3D coordinates of the point cloud to complete it or incorporate additional images with well-calibrated intrinsic parameters to guide the geometric estimation of the missing parts. Although these methods have achieved excellent performance by directly predicting the location of complete points, the extracted features lack fine-grained information regarding the location of the missing area. To address this issue, we propose a rapid and efficient method to expand an unimodal framework into a multimodal framework. This approach incorporates a position-aware module designed to enhance the spatial information of the missing parts through a weighted map learning mechanism. In addition, we establish a Point-Text-Image triplet corpus PCI-TI and MVP-TI based on the existing unimodal point cloud completion dataset and use the pre-trained vision-language model CLIP to provide richer detail information for 3D shapes, thereby enhancing performance. Extensive quantitative and qualitative experiments demonstrate that our method outperforms state-of-the-art point cloud completion methods.
Human Motion Instruction Tuning
Nov 25, 2024



This paper presents LLaMo (Large Language and Human Motion Assistant), a multimodal framework for human motion instruction tuning. In contrast to conventional instruction-tuning approaches that convert non-linguistic inputs, such as video or motion sequences, into language tokens, LLaMo retains motion in its native form for instruction tuning. This method preserves motion-specific details that are often diminished in tokenization, thereby improving the model's ability to interpret complex human behaviors. By processing both video and motion data alongside textual inputs, LLaMo enables a flexible, human-centric analysis. Experimental evaluations across high-complexity domains, including human behaviors and professional activities, indicate that LLaMo effectively captures domain-specific knowledge, enhancing comprehension and prediction in motion-intensive scenarios. We hope LLaMo offers a foundation for future multimodal AI systems with broad applications, from sports analytics to behavioral prediction. Our code and models are available on the project website: https://github.com/ILGLJ/LLaMo.
Diverse Dance Synthesis via Keyframes with Transformer Controllers
Jul 13, 2022Existing keyframe-based motion synthesis mainly focuses on the generation of cyclic actions or short-term motion, such as walking, running, and transitions between close postures. However, these methods will significantly degrade the naturalness and diversity of the synthesized motion when dealing with complex and impromptu movements, e.g., dance performance and martial arts. In addition, current research lacks fine-grained control over the generated motion, which is essential for intelligent human-computer interaction and animation creation. In this paper, we propose a novel keyframe-based motion generation network based on multiple constraints, which can achieve diverse dance synthesis via learned knowledge. Specifically, the algorithm is mainly formulated based on the recurrent neural network (RNN) and the Transformer architecture. The backbone of our network is a hierarchical RNN module composed of two long short-term memory (LSTM) units, in which the first LSTM is utilized to embed the posture information of the historical frames into a latent space, and the second one is employed to predict the human posture for the next frame. Moreover, our framework contains two Transformer-based controllers, which are used to model the constraints of the root trajectory and the velocity factor respectively, so as to better utilize the temporal context of the frames and achieve fine-grained motion control. We verify the proposed approach on a dance dataset containing a wide range of contemporary dance. The results of three quantitative analyses validate the superiority of our algorithm. The video and qualitative experimental results demonstrate that the complex motion sequences generated by our algorithm can achieve diverse and smooth motion transitions between keyframes, even for long-term synthesis.
Video Person Re-identification by Temporal Residual Learning
Feb 22, 2018
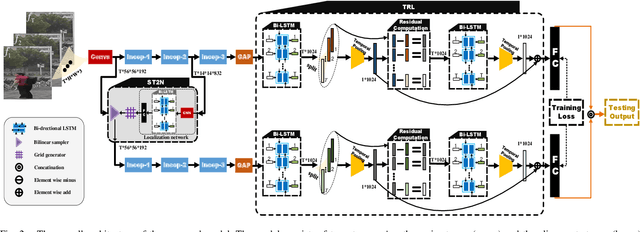


In this paper, we propose a novel feature learning framework for video person re-identification (re-ID). The proposed framework largely aims to exploit the adequate temporal information of video sequences and tackle the poor spatial alignment of moving pedestrians. More specifically, for exploiting the temporal information, we design a temporal residual learning (TRL) module to simultaneously extract the generic and specific features of consecutive frames. The TRL module is equipped with two bi-directional LSTM (BiLSTM), which are respectively responsible to describe a moving person in different aspects, providing complementary information for better feature representations. To deal with the poor spatial alignment in video re-ID datasets, we propose a spatial-temporal transformer network (ST^2N) module. Transformation parameters in the ST^2N module are learned by leveraging the high-level semantic information of the current frame as well as the temporal context knowledge from other frames. The proposed ST^2N module with less learnable parameters allows effective person alignments under significant appearance changes. Extensive experimental results on the large-scale MARS, PRID2011, ILIDS-VID and SDU-VID datasets demonstrate that the proposed method achieves consistently superior performance and outperforms most of the very recent state-of-the-art methods.