 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Person Re-identification by Temporal Residual Learning
Paper and Code
Feb 22, 2018
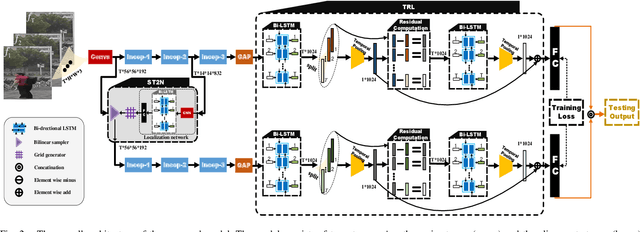


In this paper, we propose a novel feature learning framework for video person re-identification (re-ID). The proposed framework largely aims to exploit the adequate temporal information of video sequences and tackle the poor spatial alignment of moving pedestrians. More specifically, for exploiting the temporal information, we design a temporal residual learning (TRL) module to simultaneously extract the generic and specific features of consecutive frames. The TRL module is equipped with two bi-directional LSTM (BiLSTM), which are respectively responsible to describe a moving person in different aspects, providing complementary information for better feature representations. To deal with the poor spatial alignment in video re-ID datasets, we propose a spatial-temporal transformer network (ST^2N) module. Transformation parameters in the ST^2N module are learned by leveraging the high-level semantic information of the current frame as well as the temporal context knowledge from other frames. The proposed ST^2N module with less learnable parameters allows effective person alignments under significant appearance changes. Extensive experimental results on the large-scale MARS, PRID2011, ILIDS-VID and SDU-VID datasets demonstrate that the proposed method achieves consistently superior performance and outperforms most of the very recent state-of-the-art methods.