 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSE: A Unified Model for Universal Sound Separation and Extraction
Dec 24, 2025Sound separation (SS) and target sound extraction (TSE) are fundamental techniques for addressing complex acoustic scenarios. While existing SS methods struggle with determining the unknown number of sound sources, TSE approaches require precisely specified clues to achieve optimal performance. This paper proposes a unified framework that synergistically combines SS and TSE to overcome their individual limitations. Our architecture employs two complementary components: 1) An Encoder-Decoder Attractor (EDA) network that automatically infers both the source count and corresponding acoustic clues for SS, and 2) A multi-modal fusion network that precisely interprets diverse user-provided clues (acoustic, semantic, or visual) for TSE. Through joint training with cross-task consistency constraints, we establish a unified latent space that bridges both paradigms. During inference, the system adaptively operates in either fully autonomous SS mode or clue-driven TSE mode. Experiments demonstrate remarkable performance in both tasks, with notable improvements of 1.4 dB SDR improvement in SS compared to baseline and 86\% TSE accuracy.
AIonopedia: an LLM agent orchestrating multimodal learning for ionic liquid discovery
Nov 14, 2025The discovery of novel Ionic Liquids (ILs) is hindered by critical challenges in property prediction, including limited data, poor model accuracy, and fragmented workflows. Leveraging the power of Large Language Models (LLMs), we introduce AIonopedia, to the best of our knowledge, the first LLM agent for IL discovery. Powered by an LLM-augmented multimodal domain foundation model for ILs, AIonopedia enables accurate property predictions and incorporates a hierarchical search architecture for molecular screening and design. Trained and evaluated on a newly curated and comprehensive IL dataset, our model delivers superior performance. Complementing these results, evaluations on literature-reported systems indicate that the agent can perform effective IL modification. Moving beyond offline tests, the practical efficacy was further confirmed through real-world wet-lab validation, in which the agent demonstrated exceptional generalization capabilities on challenging out-of-distribution tasks, underscoring its ability to accelerate real-world IL discovery.
RWKV-PCSSC: Exploring RWKV Model for Point Cloud Semantic Scene Completion
Nov 13, 2025



Semantic Scene Completion (SSC) aims to generate a complete semantic scene from an incomplete input. Existing approaches often employ dense network architectures with a high parameter count, leading to increased model complexity and resource demands. To address these limitations, we propose RWKV-PCSSC, a lightweight point cloud semantic scene completion network inspired by the Receptance Weighted Key Value (RWKV) mechanism. Specifically, we introduce a RWKV Seed Generator (RWKV-SG) module that can aggregate features from a partial point cloud to produce a coarse point cloud with coarse features. Subsequently, the point-wise feature of the point cloud is progressively restored through multiple stages of the RWKV Point Deconvolution (RWKV-PD) modules. By leveraging a compact and efficient design, our method achieves a lightweight model representation. Experimental results demonstrate that RWKV-PCSSC reduces the parameter count by 4.18$\times$ and improves memory efficiency by 1.37$\times$ compared to state-of-the-art methods PointSSC. Furthermore, our network achieves state-of-the-art performance on established indoor (SSC-PC, NYUCAD-PC) and outdoor (PointSSC) scene dataset, as well as on our proposed datasets (NYUCAD-PC-V2, 3D-FRONT-PC).
* 13 pages, 8 figures, published to ACM MM
Efficient Generative AI Boosts Probabilistic Forecasting of Sudden Stratospheric Warmings
Oct 30, 2025Sudden Stratospheric Warmings (SSWs) are key sources of subseasonal predictability and major drivers of extreme winter weather. Yet, their accurate and efficient forecast remains a persistent challenge for numerical weather prediction (NWP) systems due to limitations in physical representation, initialization, and the immense computational demands of ensemble forecasts. While data-driven forecasting is rapidly evolving, its application to the complex, three-dimensional dynamics of SSWs, particularly for probabilistic forecast, remains underexplored. Here, we bridge this gap by developing a Flow Matching-based generative AI model (FM-Cast) for efficient and skillful probabilistic forecasting of the spatiotemporal evolution of stratospheric circulation. Evaluated across 18 major SSW events (1998-2024), FM-Cast skillfully forecasts the onset, intensity, and morphology of 10 events up to 20 days in advance, achieving ensemble accuracies above 50%. Its performance is comparable to or exceeds leading NWP systems while requiring only two minutes for a 50-member, 30-day forecast on a consumer GPU. Furthermore, leveraging FM-Cast as a scientific tool, we demonstrate through idealized experiments that SSW predictability is fundamentally linked to its underlying physical drivers, distinguishing between events forced from the troposphere and those driven by internal stratospheric dynamics. Our work thus establishes a computationally efficient paradigm for probabilistic forecasting stratospheric anomalies and showcases generative AI's potential to deepen the physical understanding of atmosphere-climate dynamics.
MDAR: A Multi-scene Dynamic Audio Reasoning Benchmark
Sep 26, 2025The ability to reason from audio, including speech, paralinguistic cues, environmental sounds, and music, is essential for AI agents to interact effectively in real-world scenarios. Existing benchmarks mainly focus on static or single-scene settings and do not fully capture scenarios where multiple speakers, unfolding events, and heterogeneous audio sources interact. To address these challenges, we introduce MDAR, a benchmark for evaluating models on complex, multi-scene, and dynamically evolving audio reasoning tasks. MDAR comprises 3,000 carefully curated question-answer pairs linked to diverse audio clips, covering five categories of complex reasoning and spanning three question types. We benchmark 26 state-of-the-art audio language models on MDAR and observe that they exhibit limitations in complex reasoning tasks. On single-choice questions, Qwen2.5-Omni (open-source) achieves 76.67% accuracy, whereas GPT-4o Audio (closed-source) reaches 68.47%; however, GPT-4o Audio substantially outperforms Qwen2.5-Omni on the more challenging multiple-choice and open-ended tasks. Across all three question types, no model achieves 80% performance. These findings underscore the unique challenges posed by MDAR and its value as a benchmark for advancing audio reasoning research.Code and benchmark can be found at https://github.com/luckyerr/MDAR.
MoTE: Mixture of Ternary Experts for Memory-efficient Large Multimodal Models
Jun 17, 2025Large multimodal Mixture-of-Experts (MoEs) effectively scale the model size to boost performance while maintaining fixed active parameters. However, previous works primarily utilized full-precision experts during sparse up-cycling. Despite they show superior performance on end tasks, the large amount of experts introduces higher memory footprint, which poses significant challenges for the deployment on edge devices. In this work, we propose MoTE, a scalable and memory-efficient approach to train Mixture-of-Ternary-Experts models from dense checkpoint. Instead of training fewer high-precision experts, we propose to train more low-precision experts during up-cycling. Specifically, we use the pre-trained FFN as a shared expert and train ternary routed experts with parameters in {-1, 0, 1}. Extensive experiments show that our approach has promising scaling trend along model size. MoTE achieves comparable performance to full-precision baseline MoE-LLaVA while offering lower memory footprint. Furthermore, our approach is compatible with post-training quantization methods and the advantage further amplifies when memory-constraint goes lower. Given the same amount of expert memory footprint of 3.4GB and combined with post-training quantization, MoTE outperforms MoE-LLaVA by a gain of 4.3% average accuracy on end tasks, demonstrating its effectiveness and potential for memory-constrained devices.
BitVLA: 1-bit Vision-Language-Action Models for Robotics Manipulation
Jun 09, 2025Vision-Language-Action (VLA) models have shown impressive capabilities across a wide range of robotics manipulation tasks. However, their growing model size poses significant challenges for deployment on resource-constrained robotic systems. While 1-bit pretraining has proven effective for enhancing the inference efficiency of large language models with minimal performance loss, its application to VLA models remains underexplored. In this work, we present BitVLA, the first 1-bit VLA model for robotics manipulation, in which every parameter is ternary, i.e., {-1, 0, 1}. To further reduce the memory footprint of the vision encoder, we propose the distillation-aware training strategy that compresses the full-precision encoder to 1.58-bit weights. During this process, a full-precision encoder serves as a teacher model to better align latent representations. Despite the lack of large-scale robotics pretraining, BitVLA achieves performance comparable to the state-of-the-art model OpenVLA-OFT with 4-bit post-training quantization on the LIBERO benchmark, while consuming only 29.8% of the memory. These results highlight BitVLA's promise for deployment on memory-constrained edge devices. We release the code and model weights in https://github.com/ustcwhy/BitVLA.
Dy3DGS-SLAM: Monocular 3D Gaussian Splatting SLAM for Dynamic Environments
Jun 06, 2025Current Simultaneous Localization and Mapping (SLAM) methods based on Neural Radiance Fields (NeRF) or 3D Gaussian Splatting excel in reconstructing static 3D scenes but struggle with tracking and reconstruction in dynamic environments, such as real-world scenes with moving elements. Existing NeRF-based SLAM approaches addressing dynamic challenges typically rely on RGB-D inputs, with few methods accommodating pure RGB input. To overcome these limitations, we propose Dy3DGS-SLAM, the first 3D Gaussian Splatting (3DGS) SLAM method for dynamic scenes using monocular RGB input. To address dynamic interference, we fuse optical flow masks and depth masks through a probabilistic model to obtain a fused dynamic mask. With only a single network iteration, this can constrain tracking scales and refine rendered geometry. Based on the fused dynamic mask, we designed a novel motion loss to constrain the pose estimation network for tracking. In mapping, we use the rendering loss of dynamic pixels, color, and depth to eliminate transient interference and occlusion caused by dynamic objects. Experimental results demonstrate that Dy3DGS-SLAM achieves state-of-the-art tracking and rendering in dynamic environments, outperforming or matching existing RGB-D methods.
Learning dissection trajectories from expert surgical videos via imitation learning with equivariant diffusion
Jun 05, 2025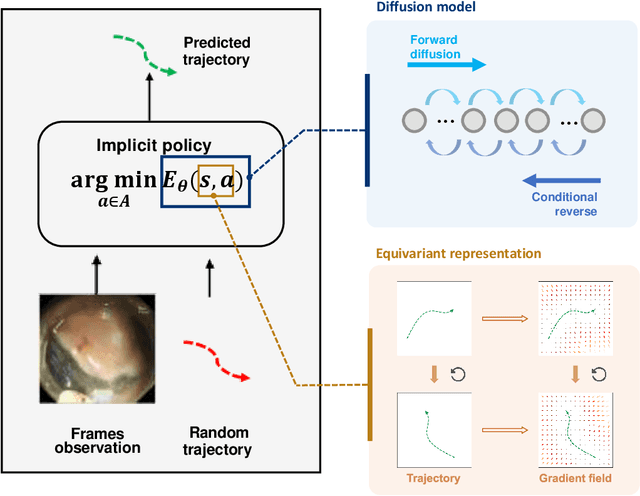
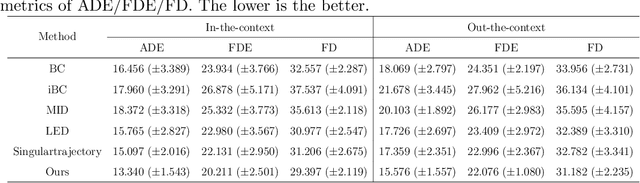
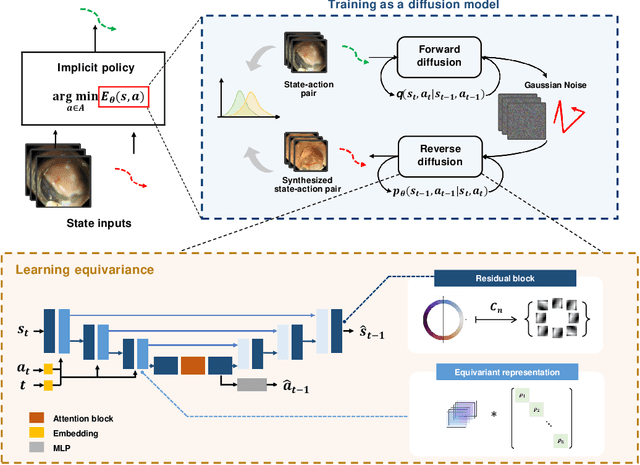
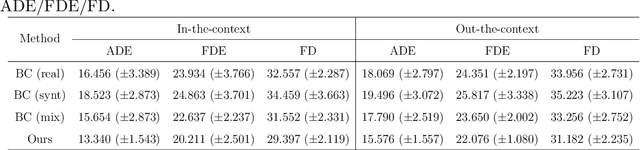
Endoscopic Submucosal Dissection (ESD) is a well-established technique for removing epithelial lesions. Predicting dissection trajectories in ESD videos offers significant potential for enhancing surgical skill training and simplifying the learning process, yet this area remains underexplored. While imitation learning has shown promise in acquiring skills from expert demonstrations, challenges persist in handling uncertain future movements, learning geometric symmetries, and generalizing to diverse surgical scenarios. To address these, we introduce a novel approach: Implicit Diffusion Policy with Equivariant Representations for Imitation Learning (iDPOE). Our method models expert behavior through a joint state action distribution, capturing the stochastic nature of dissection trajectories and enabling robust visual representation learning across various endoscopic views. By incorporating a diffusion model into policy learning, iDPOE ensures efficient training and sampling, leading to more accurate predictions and better generalization. Additionally, we enhance the model's ability to generalize to geometric symmetries by embedding equivariance into the learning process. To address state mismatches, we develop a forward-process guided action inference strategy for conditional sampling. Using an ESD video dataset of nearly 2000 clips, experimental results show that our approach surpasses state-of-the-art methods, both explicit and implicit, in trajectory prediction. To the best of our knowledge, this is the first application of imitation learning to surgical skill development for dissection trajectory prediction.
BitNet v2: Native 4-bit Activations with Hadamard Transformation for 1-bit LLMs
Apr 25, 2025



Efficient deployment of 1-bit Large Language Models (LLMs) is hindered by activation outliers, which complicate quantization to low bit-widths. We introduce BitNet v2, a novel framework enabling native 4-bit activation quantization for 1-bit LLMs. To tackle outliers in attention and feed-forward network activations, we propose H-BitLinear, a module applying an online Hadamard transformation prior to activation quantization. This transformation smooths sharp activation distributions into more Gaussian-like forms, suitable for low-bit representation. Experiments show BitNet v2 trained from scratch with 8-bit activations matches BitNet b1.58 performance. Crucially, BitNet v2 achieves minimal performance degradation when trained with native 4-bit activations, significantly reducing memory footprint and computational cost for batched inference.