 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitNet a4.8: 4-bit Activations for 1-bit LLMs
Paper and Code
Nov 07, 2024

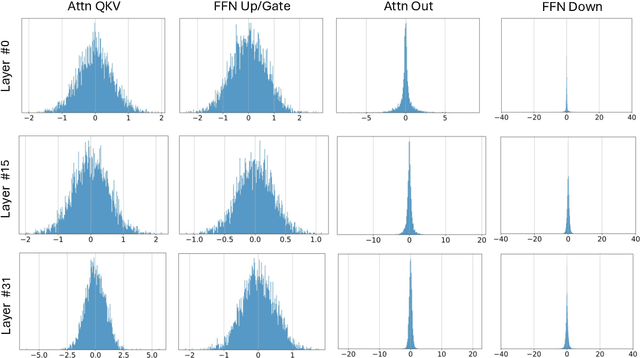

Recent research on the 1-bit Large Language Models (LLMs), such as BitNet b1.58, presents a promising direction for reducing the inference cost of LLMs while maintaining their performance. In this work, we introduce BitNet a4.8, enabling 4-bit activations for 1-bit LLMs. BitNet a4.8 employs a hybrid quantization and sparsification strategy to mitigate the quantization errors introduced by the outlier channels. Specifically, we utilize 4-bit activations for inputs to the attention and feed-forward network layers, while sparsifying intermediate states followed with 8-bit quantization. Extensive experiments demonstrate that BitNet a4.8 achieves performance comparable to BitNet b1.58 with equivalent training costs, while being faster in inference with enabling 4-bit (INT4/FP4) kernels. Additionally, BitNet a4.8 activates only 55% of parameters and supports 3-bit KV cache, further enhancing the efficiency of large-scale LLM deployment and inference.