 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongReasonArena: A Long Reasoning Benchmark for Large Language Models
Aug 26, 2025Existing long-context benchmarks for Large Language Models (LLMs) focus on evaluating comprehension of long inputs, while overlooking the evaluation of long reasoning abilities. To address this gap, we introduce LongReasonArena, a benchmark specifically designed to assess the long reasoning capabilities of LLMs. Our tasks require models to solve problems by executing multi-step algorithms that reflect key aspects of long reasoning, such as retrieval and backtracking. By controlling the inputs, the required reasoning length can be arbitrarily scaled, reaching up to 1 million tokens of reasoning for the most challenging tasks. Extensive evaluation results demonstrate that LongReasonArena presents a significant challenge for both open-source and proprietary LLMs. For instance, Deepseek-R1 achieves only 7.5% accuracy on our task. Further analysis also reveals that the accuracy exhibits a linear decline with respect to the logarithm of the expected number of reasoning steps. Our code and data is available at https://github.com/LongReasonArena/LongReasonArena.
BitNet v2: Native 4-bit Activations with Hadamard Transformation for 1-bit LLMs
Apr 25, 2025



Efficient deployment of 1-bit Large Language Models (LLMs) is hindered by activation outliers, which complicate quantization to low bit-widths. We introduce BitNet v2, a novel framework enabling native 4-bit activation quantization for 1-bit LLMs. To tackle outliers in attention and feed-forward network activations, we propose H-BitLinear, a module applying an online Hadamard transformation prior to activation quantization. This transformation smooths sharp activation distributions into more Gaussian-like forms, suitable for low-bit representation. Experiments show BitNet v2 trained from scratch with 8-bit activations matches BitNet b1.58 performance. Crucially, BitNet v2 achieves minimal performance degradation when trained with native 4-bit activations, significantly reducing memory footprint and computational cost for batched inference.
BitNet b1.58 2B4T Technical Report
Apr 16, 2025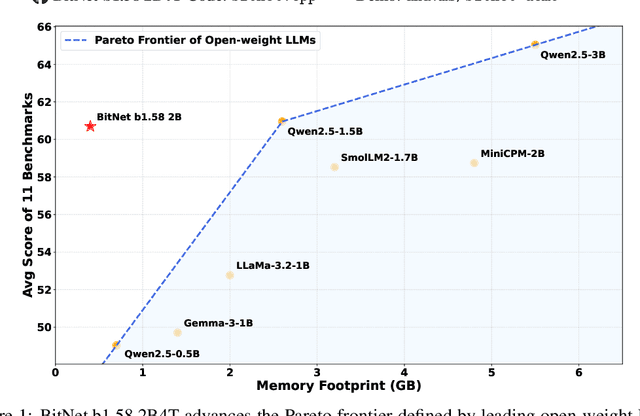
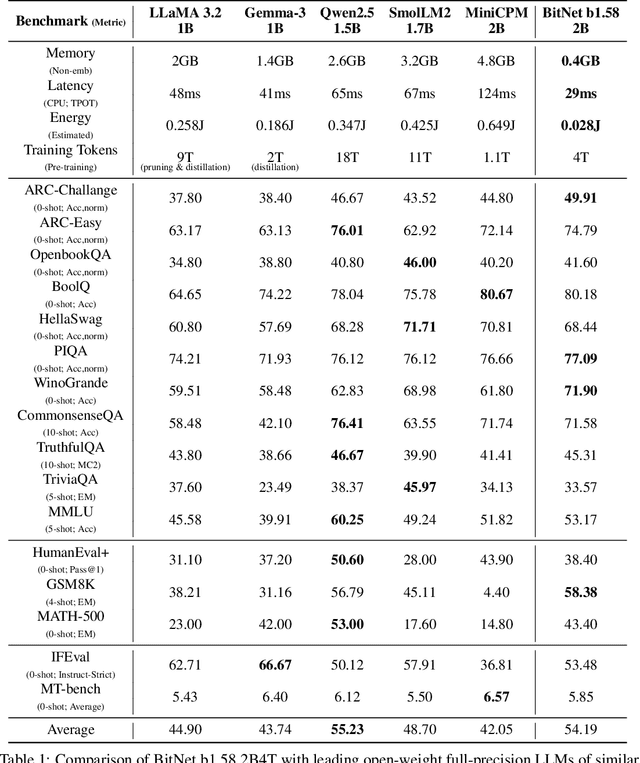
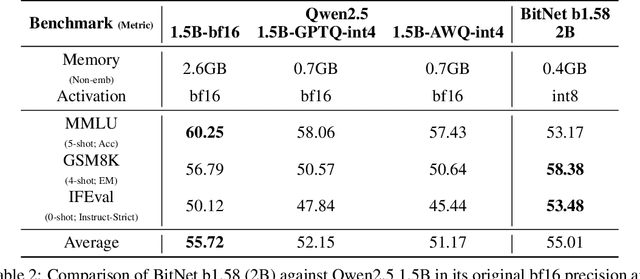
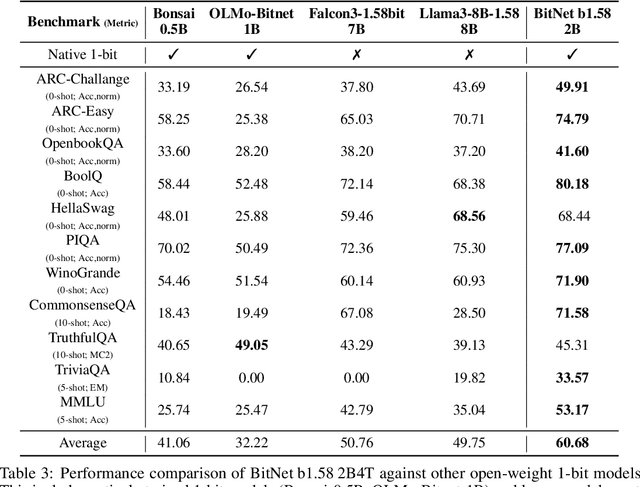
We introduce BitNet b1.58 2B4T, the first open-source, native 1-bit Large Language Model (LLM) at the 2-billion parameter scale. Trained on a corpus of 4 trillion tokens, the model has been rigorously evaluated across benchmarks covering language understanding, mathematical reasoning, coding proficiency, and conversational ability. Our results demonstrate that BitNet b1.58 2B4T achieves performance on par with leading open-weight, full-precision LLMs of similar size, while offering significant advantages in computational efficiency, including substantially reduced memory footprint, energy consumption, and decoding latency. To facilitate further research and adoption, the model weights are released via Hugging Face along with open-source inference implementations for both GPU and CPU architectures.
Towards Thinking-Optimal Scaling of Test-Time Compute for LLM Reasoning
Feb 25, 2025Recent studies have shown that making a model spend more time thinking through longer Chain of Thoughts (CoTs) enables it to gain significant improvements in complex reasoning tasks. While current researches continue to explore the benefits of increasing test-time compute by extending the CoT lengths of Large Language Models (LLMs), we are concerned about a potential issue hidden behind the current pursuit of test-time scaling: Would excessively scaling the CoT length actually bring adverse effects to a model's reasoning performance? Our explorations on mathematical reasoning tasks reveal an unexpected finding that scaling with longer CoTs can indeed impair the reasoning performance of LLMs in certain domains. Moreover, we discover that there exists an optimal scaled length distribution that differs across different domains. Based on these insights, we propose a Thinking-Optimal Scaling strategy. Our method first uses a small set of seed data with varying response length distributions to teach the model to adopt different reasoning efforts for deep thinking. Then, the model selects its shortest correct response under different reasoning efforts on additional problems for self-improvement. Our self-improved models built upon Qwen2.5-32B-Instruct outperform other distillation-based 32B o1-like models across various math benchmarks, and achieve performance on par with QwQ-32B-Preview.
Bitnet.cpp: Efficient Edge Inference for Ternary LLMs
Feb 17, 2025The advent of 1-bit large language models (LLMs), led by BitNet b1.58, has spurred interest in ternary LLMs. Despite this, research and practical applications focusing on efficient edge inference for ternary LLMs remain scarce. To bridge this gap, we introduce Bitnet.cpp, an inference system optimized for BitNet b1.58 and ternary LLMs. Given that mixed-precision matrix multiplication (mpGEMM) constitutes the bulk of inference time in ternary LLMs, Bitnet.cpp incorporates a novel mpGEMM library to facilitate sub-2-bits-per-weight, efficient and lossless inference. The library features two core solutions: Ternary Lookup Table (TL), which addresses spatial inefficiencies of previous bit-wise methods, and Int2 with a Scale (I2_S), which ensures lossless edge inference, both enabling high-speed inference. Our experiments show that Bitnet.cpp achieves up to a 6.25x increase in speed over full-precision baselines and up to 2.32x over low-bit baselines, setting new benchmarks in the field. Additionally, we expand TL to element-wise lookup table (ELUT) for low-bit LLMs in the appendix, presenting both theoretical and empirical evidence of its considerable potential. Bitnet.cpp is publicly available at https://github.com/microsoft/BitNet/tree/paper , offering a sophisticated solution for the efficient and practical deployment of edge LLMs.
Next Block Prediction: Video Generation via Semi-Autoregressive Modeling
Feb 12, 2025Next-Token Prediction (NTP) is a de facto approach for autoregressive (AR) video generation, but it suffers from suboptimal unidirectional dependencies and slow inference speed. In this work, we propose a semi-autoregressive (semi-AR) framework, called Next-Block Prediction (NBP), for video generation. By uniformly decomposing video content into equal-sized blocks (e.g., rows or frames), we shift the generation unit from individual tokens to blocks, allowing each token in the current block to simultaneously predict the corresponding token in the next block. Unlike traditional AR modeling, our framework employs bidirectional attention within each block, enabling tokens to capture more robust spatial dependencies. By predicting multiple tokens in parallel, NBP models significantly reduce the number of generation steps, leading to faster and more efficient inference. Our model achieves FVD scores of 103.3 on UCF101 and 25.5 on K600, outperforming the vanilla NTP model by an average of 4.4. Furthermore, thanks to the reduced number of inference steps, the NBP model generates 8.89 frames (128x128 resolution) per second, achieving an 11x speedup. We also explored model scales ranging from 700M to 3B parameters, observing significant improvements in generation quality, with FVD scores dropping from 103.3 to 55.3 on UCF101 and from 25.5 to 19.5 on K600, demonstrating the scalability of our approach.
RedStone: Curating General, Code, Math, and QA Data for Large Language Models
Dec 04, 2024
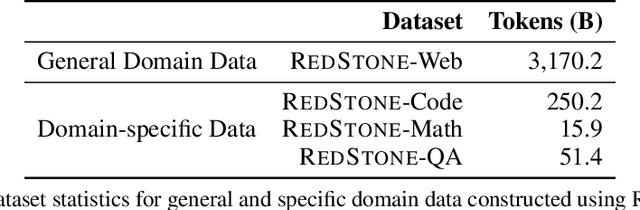
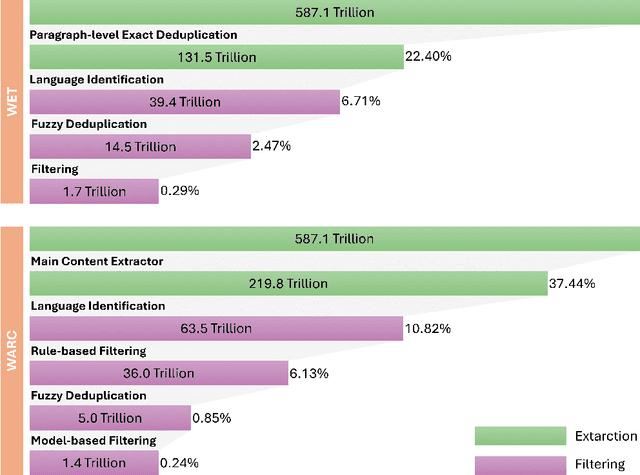
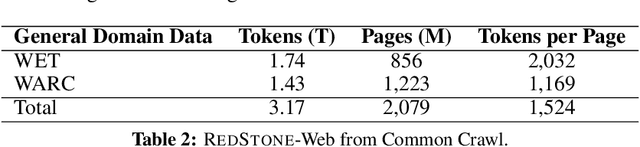
Pre-training Large Language Models (LLMs) on high-quality, meticulously curated datasets is widely recognized as critical for enhancing their performance and generalization capabilities. This study explores the untapped potential of Common Crawl as a comprehensive and flexible resource for pre-training LLMs, addressing both general-purpose language understanding and specialized domain knowledge. We introduce RedStone, an innovative and scalable pipeline engineered to extract and process data from Common Crawl, facilitating the creation of extensive and varied pre-training datasets. Unlike traditional datasets, which often require expensive curation and domain-specific expertise, RedStone leverages the breadth of Common Crawl to deliver datasets tailored to a wide array of domains. In this work, we exemplify its capability by constructing pre-training datasets across multiple fields, including general language understanding, code, mathematics, and question-answering tasks. The flexibility of RedStone allows for easy adaptation to other specialized domains, significantly lowering the barrier to creating valuable domain-specific datasets. Our findings demonstrate that Common Crawl, when harnessed through effective pipelines like RedStone, can serve as a rich, renewable source of pre-training data, unlocking new avenues for domain adaptation and knowledge discovery in LLMs. This work also underscores the importance of innovative data acquisition strategies and highlights the role of web-scale data as a powerful resource in the continued evolution of LLMs. RedStone code and data samples will be publicly available at \url{https://aka.ms/redstone}.
MH-MoE: Multi-Head Mixture-of-Experts
Nov 26, 2024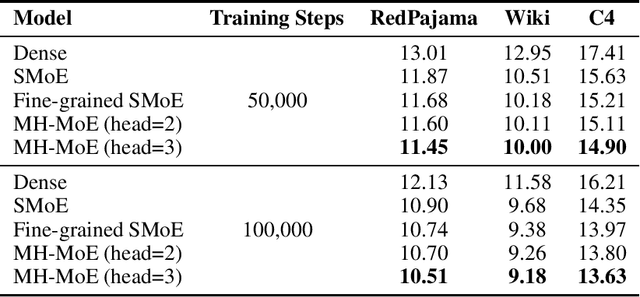
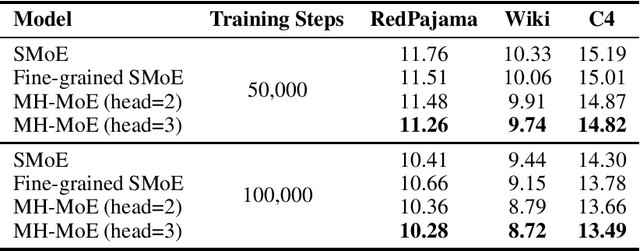
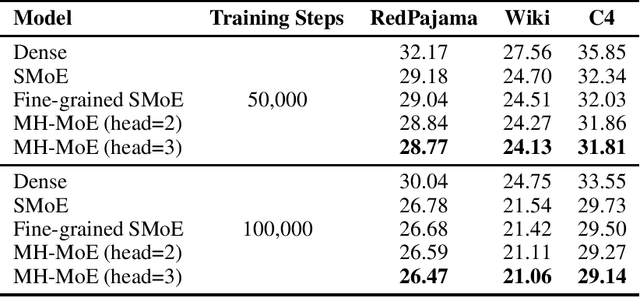

Multi-Head Mixture-of-Experts (MH-MoE) demonstrates superior performance by using the multi-head mechanism to collectively attend to information from various representation spaces within different experts. In this paper, we present a novel implementation of MH-MoE that maintains both FLOPs and parameter parity with sparse Mixture of Experts models. Experimental results on language models show that the new implementation yields quality improvements over both vanilla MoE and fine-grained MoE models. Additionally, our experiments demonstrate that MH-MoE is compatible with 1-bit Large Language Models (LLMs) such as BitNet.
BitNet a4.8: 4-bit Activations for 1-bit LLMs
Nov 07, 2024

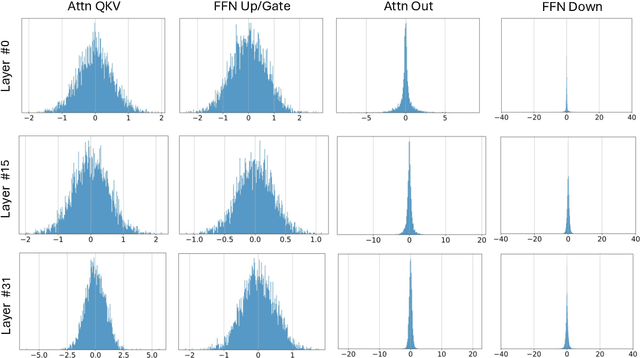

Recent research on the 1-bit Large Language Models (LLMs), such as BitNet b1.58, presents a promising direction for reducing the inference cost of LLMs while maintaining their performance. In this work, we introduce BitNet a4.8, enabling 4-bit activations for 1-bit LLMs. BitNet a4.8 employs a hybrid quantization and sparsification strategy to mitigate the quantization errors introduced by the outlier channels. Specifically, we utilize 4-bit activations for inputs to the attention and feed-forward network layers, while sparsifying intermediate states followed with 8-bit quantization. Extensive experiments demonstrate that BitNet a4.8 achieves performance comparable to BitNet b1.58 with equivalent training costs, while being faster in inference with enabling 4-bit (INT4/FP4) kernels. Additionally, BitNet a4.8 activates only 55% of parameters and supports 3-bit KV cache, further enhancing the efficiency of large-scale LLM deployment and inference.
1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs
Oct 21, 2024Recent advances in 1-bit Large Language Models (LLMs), such as BitNet and BitNet b1.58, present a promising approach to enhancing the efficiency of LLMs in terms of speed and energy consumption. These developments also enable local LLM deployment across a broad range of devices. In this work, we introduce bitnet.cpp, a tailored software stack designed to unlock the full potential of 1-bit LLMs. Specifically, we develop a set of kernels to support fast and lossless inference of ternary BitNet b1.58 LLMs on CPUs. Extensive experiments demonstrate that bitnet.cpp achieves significant speedups, ranging from 2.37x to 6.17x on x86 CPUs and from 1.37x to 5.07x on ARM CPUs, across various model sizes. The code is available at https://github.com/microsoft/BitNet.