 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisKnow: Constructing Visual Knowledge Base for Object Understanding
Dec 09, 2025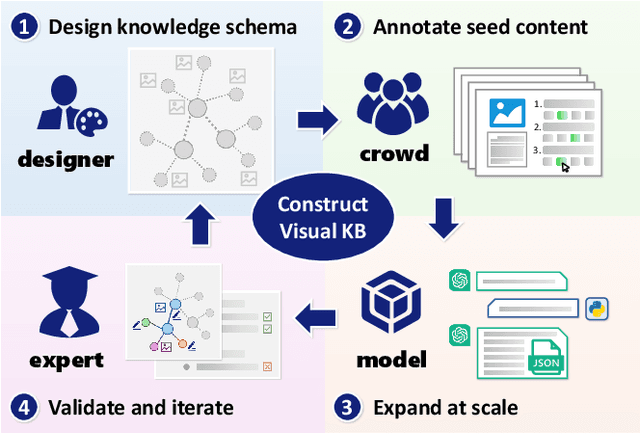



Understanding objects is fundamental to computer vision. Beyond object recognition that provides only a category label as typical output, in-depth object understanding represents a comprehensive perception of an object category, involving its components, appearance characteristics, inter-category relationships, contextual background knowledge, etc. Developing such capability requires sufficient multi-modal data, including visual annotations such as parts, attributes, and co-occurrences for specific tasks, as well as textual knowledge to support high-level tasks like reasoning and question answering. However, these data are generally task-oriented and not systematically organized enough to achieve the expected understanding of object categories. In response, we propose the Visual Knowledge Base that structures multi-modal object knowledge as graphs, and present a construction framework named VisKnow that extracts multi-modal, object-level knowledge for object understanding. This framework integrates enriched aligned text and image-source knowledge with region annotations at both object and part levels through a combination of expert design and large-scale model application. As a specific case study, we construct AnimalKB, a structured animal knowledge base covering 406 animal categories, which contains 22K textual knowledge triplets extracted from encyclopedic documents, 420K images, and corresponding region annotations. A series of experiments showcase how AnimalKB enhances object-level visual tasks such as zero-shot recognition and fine-grained VQA, and serves as challenging benchmarks for knowledge graph completion and part segmentation. Our findings highlight the potential of automatically constructing visual knowledge bases to advance visual understanding and its practical applications. The project page is available at https://vipl-vsu.github.io/VisKnow.
MoTE: Mixture of Ternary Experts for Memory-efficient Large Multimodal Models
Jun 17, 2025Large multimodal Mixture-of-Experts (MoEs) effectively scale the model size to boost performance while maintaining fixed active parameters. However, previous works primarily utilized full-precision experts during sparse up-cycling. Despite they show superior performance on end tasks, the large amount of experts introduces higher memory footprint, which poses significant challenges for the deployment on edge devices. In this work, we propose MoTE, a scalable and memory-efficient approach to train Mixture-of-Ternary-Experts models from dense checkpoint. Instead of training fewer high-precision experts, we propose to train more low-precision experts during up-cycling. Specifically, we use the pre-trained FFN as a shared expert and train ternary routed experts with parameters in {-1, 0, 1}. Extensive experiments show that our approach has promising scaling trend along model size. MoTE achieves comparable performance to full-precision baseline MoE-LLaVA while offering lower memory footprint. Furthermore, our approach is compatible with post-training quantization methods and the advantage further amplifies when memory-constraint goes lower. Given the same amount of expert memory footprint of 3.4GB and combined with post-training quantization, MoTE outperforms MoE-LLaVA by a gain of 4.3% average accuracy on end tasks, demonstrating its effectiveness and potential for memory-constrained devices.
BitVLA: 1-bit Vision-Language-Action Models for Robotics Manipulation
Jun 09, 2025Vision-Language-Action (VLA) models have shown impressive capabilities across a wide range of robotics manipulation tasks. However, their growing model size poses significant challenges for deployment on resource-constrained robotic systems. While 1-bit pretraining has proven effective for enhancing the inference efficiency of large language models with minimal performance loss, its application to VLA models remains underexplored. In this work, we present BitVLA, the first 1-bit VLA model for robotics manipulation, in which every parameter is ternary, i.e., {-1, 0, 1}. To further reduce the memory footprint of the vision encoder, we propose the distillation-aware training strategy that compresses the full-precision encoder to 1.58-bit weights. During this process, a full-precision encoder serves as a teacher model to better align latent representations. Despite the lack of large-scale robotics pretraining, BitVLA achieves performance comparable to the state-of-the-art model OpenVLA-OFT with 4-bit post-training quantization on the LIBERO benchmark, while consuming only 29.8% of the memory. These results highlight BitVLA's promise for deployment on memory-constrained edge devices. We release the code and model weights in https://github.com/ustcwhy/BitVLA.
SocialMOIF: Multi-Order Intention Fusion for Pedestrian Trajectory Prediction
Apr 22, 2025The analysis and prediction of agent trajectories are crucial for decision-making processes in intelligent systems, with precise short-term trajectory forecasting being highly significant across a range of applications. Agents and their social interactions have been quantified and modeled by researchers from various perspectives; however, substantial limitations exist in the current work due to the inherent high uncertainty of agent intentions and the complex higher-order influences among neighboring groups. SocialMOIF is proposed to tackle these challenges, concentrating on the higher-order intention interactions among neighboring groups while reinforcing the primary role of first-order intention interactions between neighbors and the target agent. This method develops a multi-order intention fusion model to achieve a more comprehensive understanding of both direct and indirect intention information. Within SocialMOIF, a trajectory distribution approximator is designed to guide the trajectories toward values that align more closely with the actual data, thereby enhancing model interpretability. Furthermore, a global trajectory optimizer is introduced to enable more accurate and efficient parallel predictions. By incorporating a novel loss function that accounts for distance and direction during training, experimental results demonstrate that the model outperforms previous state-of-the-art baselines across multiple metrics in both dynamic and static datasets.
Robotic Programmer: Video Instructed Policy Code Generation for Robotic Manipulation
Jan 08, 2025Zero-shot generalization across various robots, tasks and environments remains a significant challenge in robotic manipulation. Policy code generation methods use executable code to connect high-level task descriptions and low-level action sequences, leveraging the generalization capabilities of large language models and atomic skill libraries. In this work, we propose Robotic Programmer (RoboPro), a robotic foundation model, enabling the capability of perceiving visual information and following free-form instructions to perform robotic manipulation with policy code in a zero-shot manner. To address low efficiency and high cost in collecting runtime code data for robotic tasks, we devise Video2Code to synthesize executable code from extensive videos in-the-wild with off-the-shelf vision-language model and code-domain large language model. Extensive experiments show that RoboPro achieves the state-of-the-art zero-shot performance on robotic manipulation in both simulators and real-world environments. Specifically, the zero-shot success rate of RoboPro on RLBench surpasses the state-of-the-art model GPT-4o by 11.6%, which is even comparable to a strong supervised training baseline. Furthermore, RoboPro is robust to variations on API formats and skill sets.
RoboGSim: A Real2Sim2Real Robotic Gaussian Splatting Simulator
Nov 18, 2024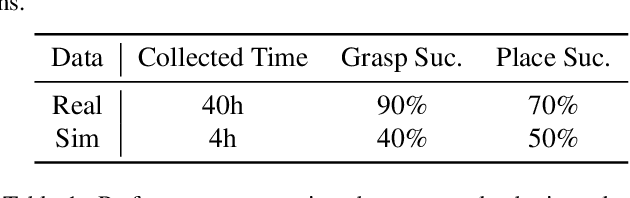
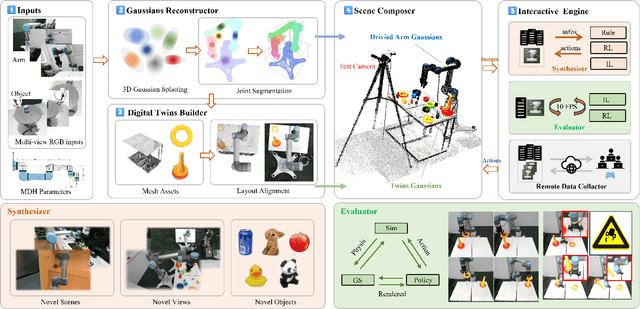


Efficient acquisition of real-world embodied data has been increasingly critical. However, large-scale demonstrations captured by remote operation tend to take extremely high costs and fail to scale up the data size in an efficient manner. Sampling the episodes under a simulated environment is a promising way for large-scale collection while existing simulators fail to high-fidelity modeling on texture and physics. To address these limitations, we introduce the RoboGSim, a real2sim2real robotic simulator, powered by 3D Gaussian Splatting and the physics engine. RoboGSim mainly includes four parts: Gaussian Reconstructor, Digital Twins Builder, Scene Composer, and Interactive Engine. It can synthesize the simulated data with novel views, objects, trajectories, and scenes. RoboGSim also provides an online, reproducible, and safe evaluation for different manipulation policies. The real2sim and sim2real transfer experiments show a high consistency in the texture and physics. Moreover, the effectiveness of synthetic data is validated under the real-world manipulated tasks. We hope RoboGSim serves as a closed-loop simulator for fair comparison on policy learning. More information can be found on our project page https://robogsim.github.io/ .
EMMA: Empowering Multi-modal Mamba with Structural and Hierarchical Alignment
Oct 08, 2024



Mamba-based architectures have shown to be a promising new direction for deep learning models owing to their competitive performance and sub-quadratic deployment speed. However, current Mamba multi-modal large language models (MLLM) are insufficient in extracting visual features, leading to imbalanced cross-modal alignment between visual and textural latents, negatively impacting performance on multi-modal tasks. In this work, we propose Empowering Multi-modal Mamba with Structural and Hierarchical Alignment (EMMA), which enables the MLLM to extract fine-grained visual information. Specifically, we propose a pixel-wise alignment module to autoregressively optimize the learning and processing of spatial image-level features along with textual tokens, enabling structural alignment at the image level. In addition, to prevent the degradation of visual information during the cross-model alignment process, we propose a multi-scale feature fusion (MFF) module to combine multi-scale visual features from intermediate layers, enabling hierarchical alignment at the feature level. Extensive experiments are conducted across a variety of multi-modal benchmarks. Our model shows lower latency than other Mamba-based MLLMs and is nearly four times faster than transformer-based MLLMs of similar scale during inference. Due to better cross-modal alignment, our model exhibits lower degrees of hallucination and enhanced sensitivity to visual details, which manifests in superior performance across diverse multi-modal benchmarks. Code will be provided.
Blocks as Probes: Dissecting Categorization Ability of Large Multimodal Models
Sep 03, 2024



Categorization, a core cognitive ability in humans that organizes objects based on common features, is essential to cognitive science as well as computer vision. To evaluate the categorization ability of visual AI models, various proxy tasks on recognition from datasets to open world scenarios have been proposed. Recent development of Large Multimodal Models (LMMs) has demonstrated impressive results in high-level visual tasks, such as visual question answering, video temporal reasoning, etc., utilizing the advanced architectures and large-scale multimodal instruction tuning. Previous researchers have developed holistic benchmarks to measure the high-level visual capability of LMMs, but there is still a lack of pure and in-depth quantitative evaluation of the most fundamental categorization ability. According to the research on human cognitive process, categorization can be seen as including two parts: category learning and category use. Inspired by this, we propose a novel, challenging, and efficient benchmark based on composite blocks, called ComBo, which provides a disentangled evaluation framework and covers the entire categorization process from learning to use. By analyzing the results of multiple evaluation tasks, we find that although LMMs exhibit acceptable generalization ability in learning new categories, there are still gaps compared to humans in many ways, such as fine-grained perception of spatial relationship and abstract category understanding. Through the study of categorization, we can provide inspiration for the further development of LMMs in terms of interpretability and generalization.
GPSFormer: A Global Perception and Local Structure Fitting-based Transformer for Point Cloud Understanding
Jul 18, 2024



Despite the significant advancements in pre-training methods for point cloud understanding, directly capturing intricate shape information from irregular point clouds without reliance on external data remains a formidable challenge. To address this problem, we propose GPSFormer, an innovative Global Perception and Local Structure Fitting-based Transformer, which learns detailed shape information from point clouds with remarkable precision. The core of GPSFormer is the Global Perception Module (GPM) and the Local Structure Fitting Convolution (LSFConv). Specifically, GPM utilizes Adaptive Deformable Graph Convolution (ADGConv) to identify short-range dependencies among similar features in the feature space and employs Multi-Head Attention (MHA) to learn long-range dependencies across all positions within the feature space, ultimately enabling flexible learning of contextual representations. Inspired by Taylor series, we design LSFConv, which learns both low-order fundamental and high-order refinement information from explicitly encoded local geometric structures. Integrating the GPM and LSFConv as fundamental components, we construct GPSFormer, a cutting-edge Transformer that effectively captures global and local structures of point clouds. Extensive experiments validate GPSFormer's effectiveness in three point cloud tasks: shape classification, part segmentation, and few-shot learning. The code of GPSFormer is available at \url{https://github.com/changshuowang/GPSFormer}.
Q-Sparse: All Large Language Models can be Fully Sparsely-Activated
Jul 15, 2024



We introduce, Q-Sparse, a simple yet effective approach to training sparsely-activated large language models (LLMs). Q-Sparse enables full sparsity of activations in LLMs which can bring significant efficiency gains in inference. This is achieved by applying top-K sparsification to the activations and the straight-through-estimator to the training. The key results from this work are, (1) Q-Sparse can achieve results comparable to those of baseline LLMs while being much more efficient at inference time; (2) We present an inference-optimal scaling law for sparsely-activated LLMs; (3) Q-Sparse is effective in different settings, including training-from-scratch, continue-training of off-the-shelf LLMs, and finetuning; (4) Q-Sparse works for both full-precision and 1-bit LLMs (e.g., BitNet b1.58). Particularly, the synergy of BitNet b1.58 and Q-Sparse (can be equipped with MoE) provides the cornerstone and a clear path to revolutionize the efficiency, including cost and energy consumption, of future LLMs.