 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisKnow: Constructing Visual Knowledge Base for Object Understanding
Dec 09, 2025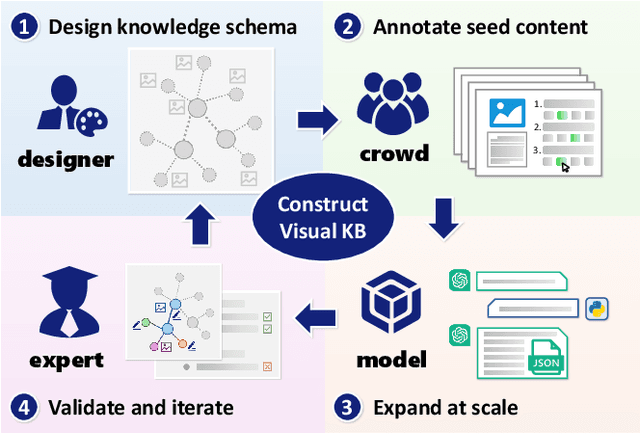



Understanding objects is fundamental to computer vision. Beyond object recognition that provides only a category label as typical output, in-depth object understanding represents a comprehensive perception of an object category, involving its components, appearance characteristics, inter-category relationships, contextual background knowledge, etc. Developing such capability requires sufficient multi-modal data, including visual annotations such as parts, attributes, and co-occurrences for specific tasks, as well as textual knowledge to support high-level tasks like reasoning and question answering. However, these data are generally task-oriented and not systematically organized enough to achieve the expected understanding of object categories. In response, we propose the Visual Knowledge Base that structures multi-modal object knowledge as graphs, and present a construction framework named VisKnow that extracts multi-modal, object-level knowledge for object understanding. This framework integrates enriched aligned text and image-source knowledge with region annotations at both object and part levels through a combination of expert design and large-scale model application. As a specific case study, we construct AnimalKB, a structured animal knowledge base covering 406 animal categories, which contains 22K textual knowledge triplets extracted from encyclopedic documents, 420K images, and corresponding region annotations. A series of experiments showcase how AnimalKB enhances object-level visual tasks such as zero-shot recognition and fine-grained VQA, and serves as challenging benchmarks for knowledge graph completion and part segmentation. Our findings highlight the potential of automatically constructing visual knowledge bases to advance visual understanding and its practical applications. The project page is available at https://vipl-vsu.github.io/VisKnow.
Blocks as Probes: Dissecting Categorization Ability of Large Multimodal Models
Sep 03, 2024



Categorization, a core cognitive ability in humans that organizes objects based on common features, is essential to cognitive science as well as computer vision. To evaluate the categorization ability of visual AI models, various proxy tasks on recognition from datasets to open world scenarios have been proposed. Recent development of Large Multimodal Models (LMMs) has demonstrated impressive results in high-level visual tasks, such as visual question answering, video temporal reasoning, etc., utilizing the advanced architectures and large-scale multimodal instruction tuning. Previous researchers have developed holistic benchmarks to measure the high-level visual capability of LMMs, but there is still a lack of pure and in-depth quantitative evaluation of the most fundamental categorization ability. According to the research on human cognitive process, categorization can be seen as including two parts: category learning and category use. Inspired by this, we propose a novel, challenging, and efficient benchmark based on composite blocks, called ComBo, which provides a disentangled evaluation framework and covers the entire categorization process from learning to use. By analyzing the results of multiple evaluation tasks, we find that although LMMs exhibit acceptable generalization ability in learning new categories, there are still gaps compared to humans in many ways, such as fine-grained perception of spatial relationship and abstract category understanding. Through the study of categorization, we can provide inspiration for the further development of LMMs in terms of interpretability and generalization.