 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuSpring: Neural Spring Fields for Reconstruction and Simulation of Deformable Objects from Videos
Nov 11, 2025In this paper, we aim to create physical digital twins of deformable objects under interaction. Existing methods focus more on the physical learning of current state modeling, but generalize worse to future prediction. This is because existing methods ignore the intrinsic physical properties of deformable objects, resulting in the limited physical learning in the current state modeling. To address this, we present NeuSpring, a neural spring field for the reconstruction and simulation of deformable objects from videos. Built upon spring-mass models for realistic physical simulation, our method consists of two major innovations: 1) a piecewise topology solution that efficiently models multi-region spring connection topologies using zero-order optimization, which considers the material heterogeneity of real-world objects. 2) a neural spring field that represents spring physical properties across different frames using a canonical coordinate-based neural network, which effectively leverages the spatial associativity of springs for physical learning. Experiments on real-world datasets demonstrate that our NeuSping achieves superior reconstruction and simulation performance for current state modeling and future prediction, with Chamfer distance improved by 20% and 25%, respectively.
CodeBoost: Boosting Code LLMs by Squeezing Knowledge from Code Snippets with RL
Aug 07, 2025Code large language models (LLMs) have become indispensable tools for building efficient and automated coding pipelines. Existing models are typically post-trained using reinforcement learning (RL) from general-purpose LLMs using "human instruction-final answer" pairs, where the instructions are usually from manual annotations. However, collecting high-quality coding instructions is both labor-intensive and difficult to scale. On the other hand, code snippets are abundantly available from various sources. This imbalance presents a major bottleneck in instruction-based post-training. We propose CodeBoost, a post-training framework that enhances code LLMs purely from code snippets, without relying on human-annotated instructions. CodeBoost introduces the following key components: (1) maximum-clique curation, which selects a representative and diverse training corpus from code; (2) bi-directional prediction, which enables the model to learn from both forward and backward prediction objectives; (3) error-aware prediction, which incorporates learning signals from both correct and incorrect outputs; (4) heterogeneous augmentation, which diversifies the training distribution to enrich code semantics; and (5) heterogeneous rewarding, which guides model learning through multiple reward types including format correctness and execution feedback from both successes and failures. Extensive experiments across several code LLMs and benchmarks verify that CodeBoost consistently improves performance, demonstrating its effectiveness as a scalable and effective training pipeline.
UAVScenes: A Multi-Modal Dataset for UAVs
Jul 30, 2025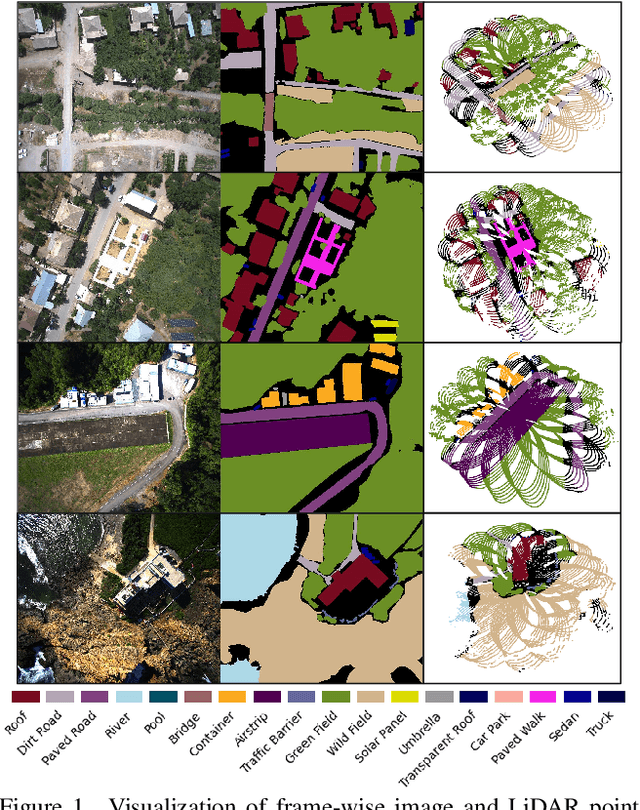
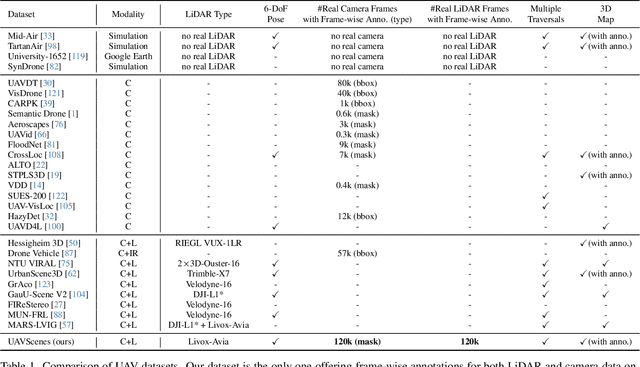
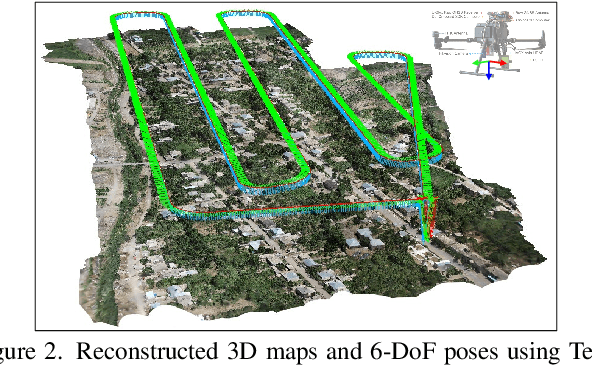
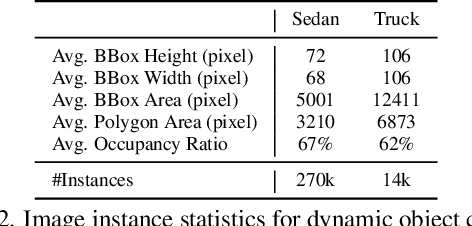
Multi-modal perception is essential for unmanned aerial vehicle (UAV) operations, as it enables a comprehensive understanding of the UAVs' surrounding environment. However, most existing multi-modal UAV datasets are primarily biased toward localization and 3D reconstruction tasks, or only support map-level semantic segmentation due to the lack of frame-wise annotations for both camera images and LiDAR point clouds. This limitation prevents them from being used for high-level scene understanding tasks. To address this gap and advance multi-modal UAV perception, we introduce UAVScenes, a large-scale dataset designed to benchmark various tasks across both 2D and 3D modalities. Our benchmark dataset is built upon the well-calibrated multi-modal UAV dataset MARS-LVIG, originally developed only for simultaneous localization and mapping (SLAM). We enhance this dataset by providing manually labeled semantic annotations for both frame-wise images and LiDAR point clouds, along with accurate 6-degree-of-freedom (6-DoF) poses. These additions enable a wide range of UAV perception tasks, including segmentation, depth estimation, 6-DoF localization, place recognition, and novel view synthesis (NVS). Our dataset is available at https://github.com/sijieaaa/UAVScenes
GPSFormer: A Global Perception and Local Structure Fitting-based Transformer for Point Cloud Understanding
Jul 18, 2024



Despite the significant advancements in pre-training methods for point cloud understanding, directly capturing intricate shape information from irregular point clouds without reliance on external data remains a formidable challenge. To address this problem, we propose GPSFormer, an innovative Global Perception and Local Structure Fitting-based Transformer, which learns detailed shape information from point clouds with remarkable precision. The core of GPSFormer is the Global Perception Module (GPM) and the Local Structure Fitting Convolution (LSFConv). Specifically, GPM utilizes Adaptive Deformable Graph Convolution (ADGConv) to identify short-range dependencies among similar features in the feature space and employs Multi-Head Attention (MHA) to learn long-range dependencies across all positions within the feature space, ultimately enabling flexible learning of contextual representations. Inspired by Taylor series, we design LSFConv, which learns both low-order fundamental and high-order refinement information from explicitly encoded local geometric structures. Integrating the GPM and LSFConv as fundamental components, we construct GPSFormer, a cutting-edge Transformer that effectively captures global and local structures of point clouds. Extensive experiments validate GPSFormer's effectiveness in three point cloud tasks: shape classification, part segmentation, and few-shot learning. The code of GPSFormer is available at \url{https://github.com/changshuowang/GPSFormer}.
Review: deep learning on 3D point clouds
Jan 17, 2020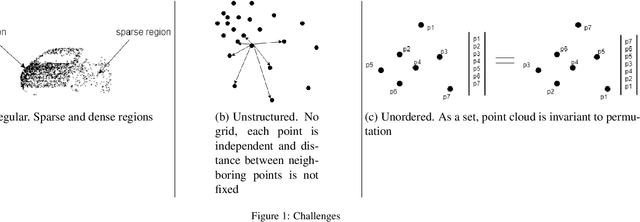
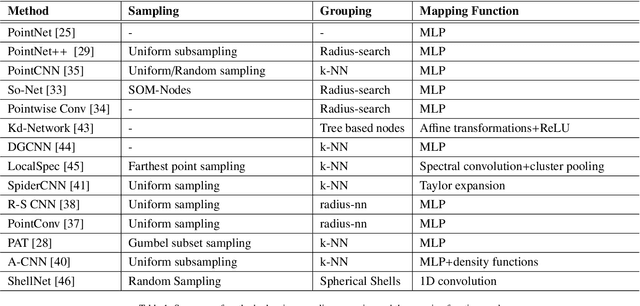
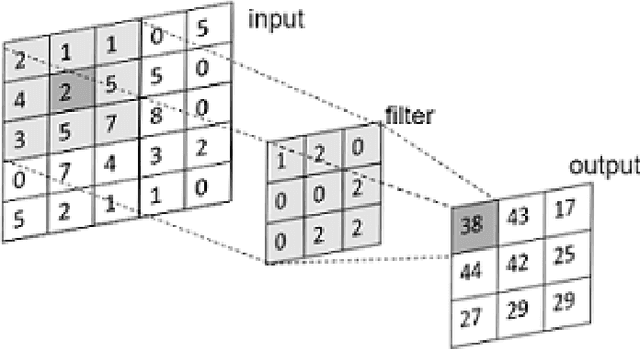
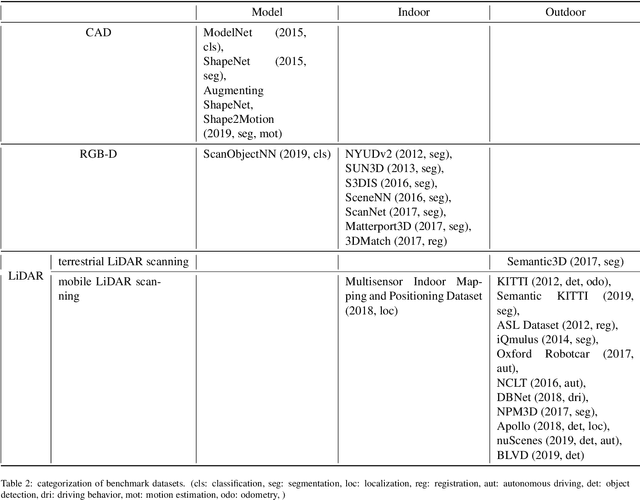
Point cloud is point sets defined in 3D metric space. Point cloud has become one of the most significant data format for 3D representation. Its gaining increased popularity as a result of increased availability of acquisition devices, such as LiDAR, as well as increased application in areas such as robotics, autonomous driving, augmented and virtual reality. Deep learning is now the most powerful tool for data processing in computer vision, becoming the most preferred technique for tasks such as classification, segmentation, and detection. While deep learning techniques are mainly applied to data with a structured grid, point cloud, on the other hand, is unstructured. The unstructuredness of point clouds makes use of deep learning for its processing directly very challenging. Earlier approaches overcome this challenge by preprocessing the point cloud into a structured grid format at the cost of increased computational cost or lost of depth information. Recently, however, many state-of-the-arts deep learning techniques that directly operate on point cloud are being developed. This paper contains a survey of the recent state-of-the-art deep learning techniques that mainly focused on point cloud data. We first briefly discussed the major challenges faced when using deep learning directly on point cloud, we also briefly discussed earlier approaches which overcome the challenges by preprocessing the point cloud into a structured grid. We then give the review of the various state-of-the-art deep learning approaches that directly process point cloud in its unstructured form. We introduced the popular 3D point cloud benchmark datasets. And we also further discussed the application of deep learning in popular 3D vision tasks including classification, segmentation and detection.