 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaylor Series-Inspired Local Structure Fitting Network for Few-shot Point Cloud Semantic Segmentation
Apr 03, 2025Few-shot point cloud semantic segmentation aims to accurately segment "unseen" new categories in point cloud scenes using limited labeled data. However, pretraining-based methods not only introduce excessive time overhead but also overlook the local structure representation among irregular point clouds. To address these issues, we propose a pretraining-free local structure fitting network for few-shot point cloud semantic segmentation, named TaylorSeg. Specifically, inspired by Taylor series, we treat the local structure representation of irregular point clouds as a polynomial fitting problem and propose a novel local structure fitting convolution, called TaylorConv. This convolution learns the low-order basic information and high-order refined information of point clouds from explicit encoding of local geometric structures. Then, using TaylorConv as the basic component, we construct two variants of TaylorSeg: a non-parametric TaylorSeg-NN and a parametric TaylorSeg-PN. The former can achieve performance comparable to existing parametric models without pretraining. For the latter, we equip it with an Adaptive Push-Pull (APP) module to mitigate the feature distribution differences between the query set and the support set. Extensive experiments validate the effectiveness of the proposed method. Notably, under the 2-way 1-shot setting, TaylorSeg-PN achieves improvements of +2.28% and +4.37% mIoU on the S3DIS and ScanNet datasets respectively, compared to the previous state-of-the-art methods. Our code is available at https://github.com/changshuowang/TaylorSeg.
GPSFormer: A Global Perception and Local Structure Fitting-based Transformer for Point Cloud Understanding
Jul 18, 2024



Despite the significant advancements in pre-training methods for point cloud understanding, directly capturing intricate shape information from irregular point clouds without reliance on external data remains a formidable challenge. To address this problem, we propose GPSFormer, an innovative Global Perception and Local Structure Fitting-based Transformer, which learns detailed shape information from point clouds with remarkable precision. The core of GPSFormer is the Global Perception Module (GPM) and the Local Structure Fitting Convolution (LSFConv). Specifically, GPM utilizes Adaptive Deformable Graph Convolution (ADGConv) to identify short-range dependencies among similar features in the feature space and employs Multi-Head Attention (MHA) to learn long-range dependencies across all positions within the feature space, ultimately enabling flexible learning of contextual representations. Inspired by Taylor series, we design LSFConv, which learns both low-order fundamental and high-order refinement information from explicitly encoded local geometric structures. Integrating the GPM and LSFConv as fundamental components, we construct GPSFormer, a cutting-edge Transformer that effectively captures global and local structures of point clouds. Extensive experiments validate GPSFormer's effectiveness in three point cloud tasks: shape classification, part segmentation, and few-shot learning. The code of GPSFormer is available at \url{https://github.com/changshuowang/GPSFormer}.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020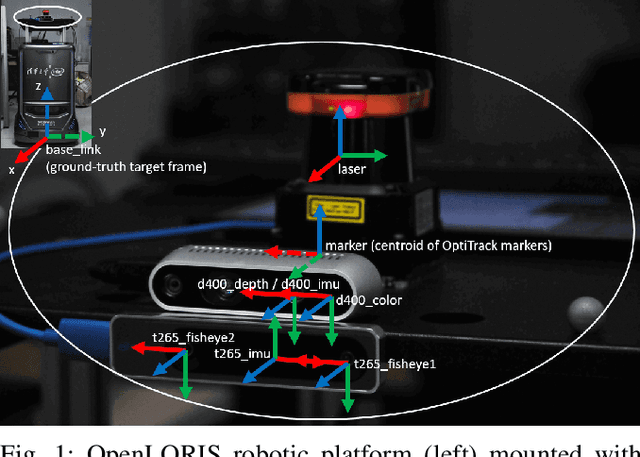
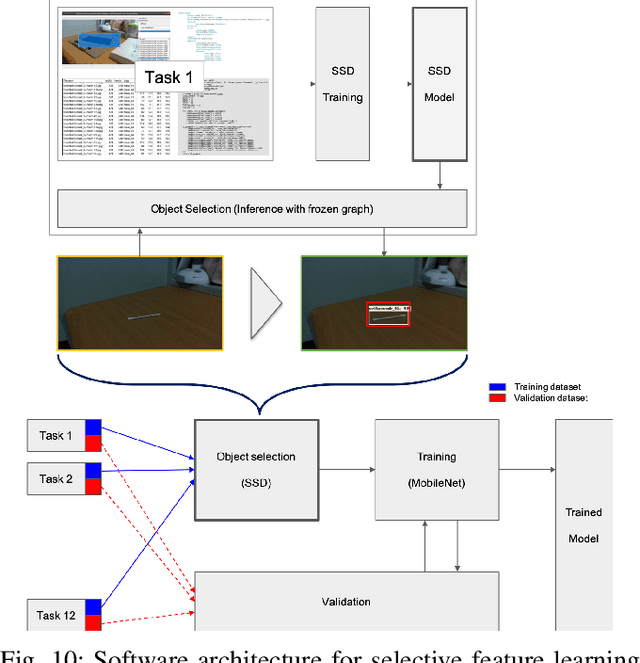
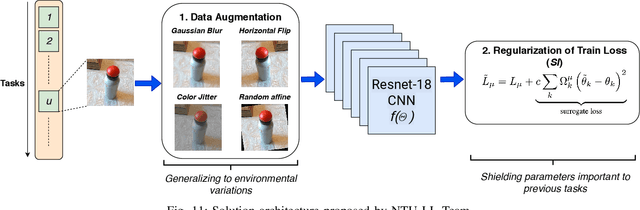

This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".
SSA-CNN: Semantic Self-Attention CNN for Pedestrian Detection
Mar 04, 2019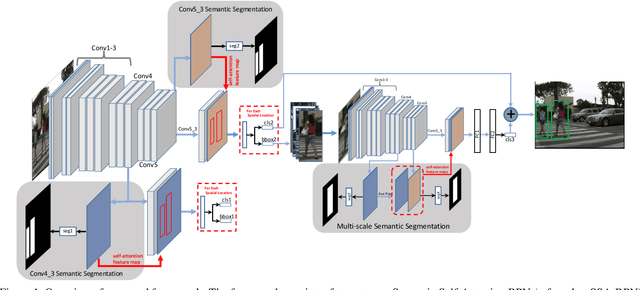

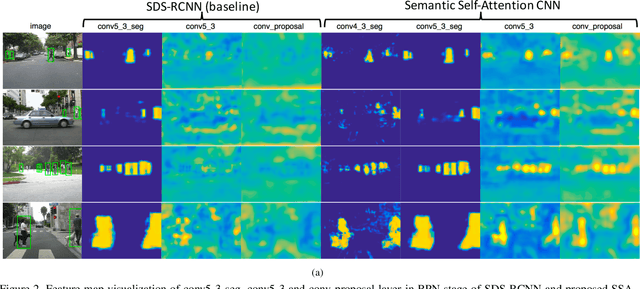
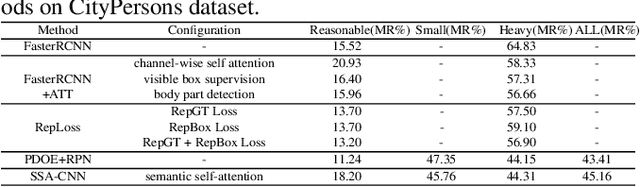
Pedestrian detection plays an important role in many applications such as autonomous driving. We propose a method that explores semantic segmentation results as self-attention cues to significantly improve the pedestrian detection performance. Specifically, a multi-task network is designed to jointly learn semantic segmentation and pedestrian detection from image datasets with weak box-wise annotations. The semantic segmentation feature maps are concatenated with corresponding convolution features maps to provide more discriminative features for pedestrian detection and pedestrian classification. By jointly learning segmentation and detection, our proposed pedestrian self-attention mechanism can effectively identify pedestrian regions and suppress backgrounds. In addition, we propose to incorporate semantic attention information from multi-scale layers into deep convolution neural network to boost pedestrian detection. Experiment results show that the proposed method achieves the best detection performance with MR of 6.27% on Caltech dataset and obtain competitive performance on CityPersons dataset while maintaining high computational efficiency.
Situation-Aware Pedestrian Trajectory Prediction with Spatio-Temporal Attention Model
Feb 13, 2019

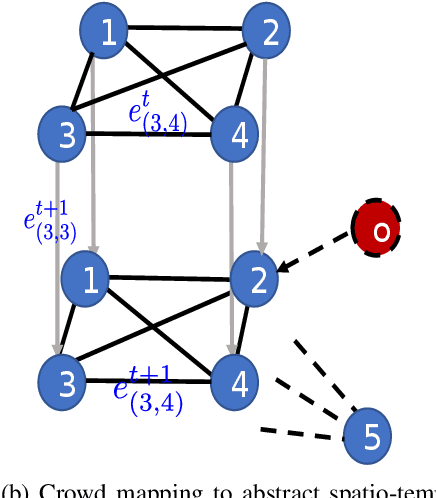
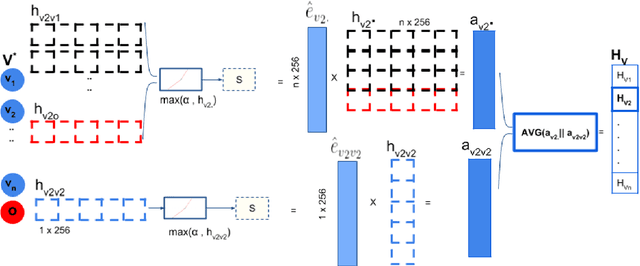
Pedestrian trajectory prediction is essential for collision avoidance in autonomous driving and robot navigation. However, predicting a pedestrian's trajectory in crowded environments is non-trivial as it is influenced by other pedestrians' motion and static structures that are present in the scene. Such human-human and human-space interactions lead to non-linearities in the trajectories. In this paper, we present a new spatio-temporal graph based Long Short-Term Memory (LSTM) network for predicting pedestrian trajectory in crowded environments, which takes into account the interaction with static (physical objects) and dynamic (other pedestrians) elements in the scene. Our results are based on two widely-used datasets to demonstrate that the proposed method outperforms the state-of-the-art approaches in human trajectory prediction. In particular, our method leads to a reduction in Average Displacement Error (ADE) and Final Displacement Error (FDE) of up to 55% and 61% respectively over state-of-the-art approaches.