 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBook your room in the Turing Hotel! A symmetric and distributed Turing Test with multiple AIs and humans
Mar 19, 2026In this paper, we report our experience with ``TuringHotel'', a novel extension of the Turing Test based on interactions within mixed communities of Large Language Models (LLMs) and human participants. The classical one-to-one interaction of the Turing Test is reinterpreted in a group setting, where both human and artificial agents engage in time-bounded discussions and, interestingly, are both judges and respondents. This community is instantiated in the novel platform UNaIVERSE (https://unaiverse.io), creating a ``World'' which defines the roles and interaction dynamics, facilitated by the platform's built-in programming tools. All communication occurs over an authenticated peer-to-peer network, ensuring that no third parties can access the exchange. The platform also provides a unified interface for humans, accessible via both mobile devices and laptops, that was a key component of the experience in this paper. Results of our experimentation involving 17 human participants and 19 LLMs revealed that current models are still sometimes confused as humans. Interestingly, there are several unexpected mistakes, suggesting that human fingerprints are still identifiable but not fully unambiguous, despite the high-quality language skills of artificial participants. We argue that this is the first experiment conducted in such a distributed setting, and that similar initiatives could be of national interest to support ongoing experiments and competitions aimed at monitoring the evolution of large language models over time.
Streaming Continual Learning for Unified Adaptive Intelligence in Dynamic Environments
Mar 02, 2026Developing effective predictive models becomes challenging in dynamic environments that continuously produce data and constantly change. Continual Learning (CL) and Streaming Machine Learning (SML) are two research areas that tackle this arduous task. We put forward a unified setting that harnesses the benefits of both CL and SML: their ability to quickly adapt to non-stationary data streams without forgetting previous knowledge. We refer to this setting as Streaming Continual Learning (SCL). SCL does not replace either CL or SML. Instead, it extends the techniques and approaches considered by both fields. We start by briefly describing CL and SML and unifying the languages of the two frameworks. We then present the key features of SCL. We finally highlight the importance of bridging the two communities to advance the field of intelligent systems.
Modular Memory is the Key to Continual Learning Agents
Mar 02, 2026Foundation models have transformed machine learning through large-scale pretraining and increased test-time compute. Despite surpassing human performance in several domains, these models remain fundamentally limited in continuous operation, experience accumulation, and personalization, capabilities that are central to adaptive intelligence. While continual learning research has long targeted these goals, its historical focus on in-weight learning (IWL), i.e., updating a single model's parameters to absorb new knowledge, has rendered catastrophic forgetting a persistent challenge. Our position is that combining the strengths of In-Weight Learning (IWL) and the newly emerged capabilities of In-Context Learning (ICL) through the design of modular memory is the missing piece for continual adaptation at scale. We outline a conceptual framework for modular memory-centric architectures that leverage ICL for rapid adaptation and knowledge accumulation, and IWL for stable updates to model capabilities, charting a practical roadmap toward continually learning agents.
HAM: Hierarchical Adapter Merging for Scalable Continual Learning
Sep 16, 2025



Continual learning is an essential capability of human cognition, yet it poses significant challenges for current deep learning models. The primary issue is that new knowledge can interfere with previously learned information, causing the model to forget earlier knowledge in favor of the new, a phenomenon known as catastrophic forgetting. Although large pre-trained models can partially mitigate forgetting by leveraging their existing knowledge and over-parameterization, they often struggle when confronted with novel data distributions. Parameter-Efficient Fine-Tuning (PEFT) methods, such as LoRA, enable efficient adaptation to new knowledge. However, they still face challenges in scaling to dynamic learning scenarios and long sequences of tasks, as maintaining one adapter per task introduces complexity and increases the potential for interference. In this paper, we introduce Hierarchical Adapters Merging (HAM), a novel framework that dynamically combines adapters from different tasks during training. This approach enables HAM to scale effectively, allowing it to manage more tasks than competing baselines with improved efficiency. To achieve this, HAM maintains a fixed set of groups that hierarchically consolidate new adapters. For each task, HAM trains a low-rank adapter along with an importance scalar, then dynamically groups tasks based on adapter similarity. Within each group, adapters are pruned, scaled and merge, facilitating transfer learning between related tasks. Extensive experiments on three vision benchmarks show that HAM significantly outperforms state-of-the-art methods, particularly as the number of tasks increases.
Combining Pre-Trained Models for Enhanced Feature Representation in Reinforcement Learning
Jul 09, 2025The recent focus and release of pre-trained models have been a key components to several advancements in many fields (e.g. Natural Language Processing and Computer Vision), as a matter of fact, pre-trained models learn disparate latent embeddings sharing insightful representations. On the other hand, Reinforcement Learning (RL) focuses on maximizing the cumulative reward obtained via agent's interaction with the environment. RL agents do not have any prior knowledge about the world, and they either learn from scratch an end-to-end mapping between the observation and action spaces or, in more recent works, are paired with monolithic and computationally expensive Foundational Models. How to effectively combine and leverage the hidden information of different pre-trained models simultaneously in RL is still an open and understudied question. In this work, we propose Weight Sharing Attention (WSA), a new architecture to combine embeddings of multiple pre-trained models to shape an enriched state representation, balancing the tradeoff between efficiency and performance. We run an extensive comparison between several combination modes showing that WSA obtains comparable performance on multiple Atari games compared to end-to-end models. Furthermore, we study the generalization capabilities of this approach and analyze how scaling the number of models influences agents' performance during and after training.
Task-Agnostic Experts Composition for Continual Learning
Jun 18, 2025Compositionality is one of the fundamental abilities of the human reasoning process, that allows to decompose a complex problem into simpler elements. Such property is crucial also for neural networks, especially when aiming for a more efficient and sustainable AI framework. We propose a compositional approach by ensembling zero-shot a set of expert models, assessing our methodology using a challenging benchmark, designed to test compositionality capabilities. We show that our Expert Composition method is able to achieve a much higher accuracy than baseline algorithms while requiring less computational resources, hence being more efficient.
Parameter-Efficient Continual Fine-Tuning: A Survey
Apr 18, 2025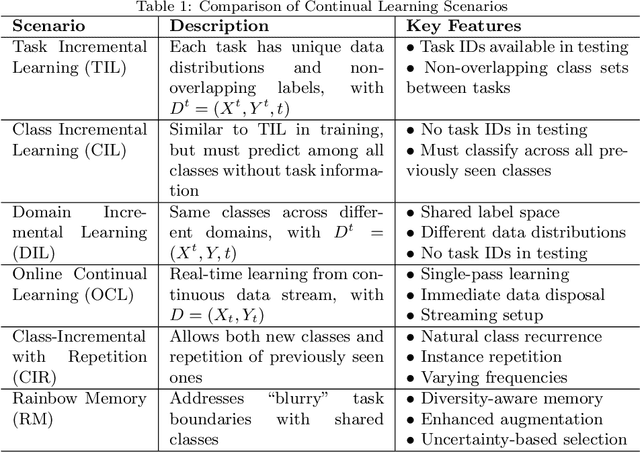

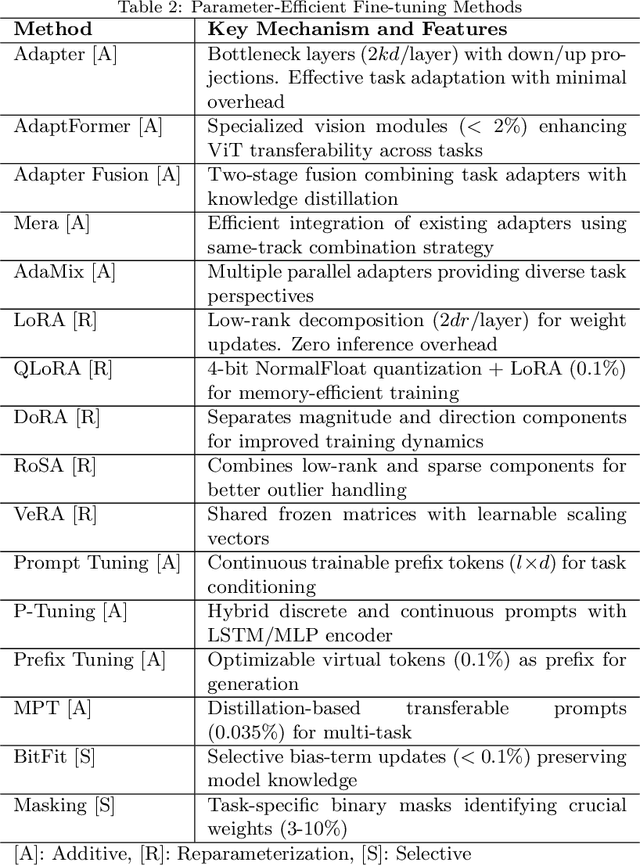
The emergence of large pre-trained networks has revolutionized the AI field, unlocking new possibilities and achieving unprecedented performance. However, these models inherit a fundamental limitation from traditional Machine Learning approaches: their strong dependence on the \textit{i.i.d.} assumption hinders their adaptability to dynamic learning scenarios. We believe the next breakthrough in AI lies in enabling efficient adaptation to evolving environments -- such as the real world -- where new data and tasks arrive sequentially. This challenge defines the field of Continual Learning (CL), a Machine Learning paradigm focused on developing lifelong learning neural models. One alternative to efficiently adapt these large-scale models is known Parameter-Efficient Fine-Tuning (PEFT). These methods tackle the issue of adapting the model to a particular data or scenario by performing small and efficient modifications, achieving similar performance to full fine-tuning. However, these techniques still lack the ability to adjust the model to multiple tasks continually, as they suffer from the issue of Catastrophic Forgetting. In this survey, we first provide an overview of CL algorithms and PEFT methods before reviewing the state-of-the-art on Parameter-Efficient Continual Fine-Tuning (PECFT). We examine various approaches, discuss evaluation metrics, and explore potential future research directions. Our goal is to highlight the synergy between CL and Parameter-Efficient Fine-Tuning, guide researchers in this field, and pave the way for novel future research directions.
Continual Learning Should Move Beyond Incremental Classification
Feb 17, 2025


Continual learning (CL) is the sub-field of machine learning concerned with accumulating knowledge in dynamic environments. So far, CL research has mainly focused on incremental classification tasks, where models learn to classify new categories while retaining knowledge of previously learned ones. Here, we argue that maintaining such a focus limits both theoretical development and practical applicability of CL methods. Through a detailed analysis of concrete examples - including multi-target classification, robotics with constrained output spaces, learning in continuous task domains, and higher-level concept memorization - we demonstrate how current CL approaches often fail when applied beyond standard classification. We identify three fundamental challenges: (C1) the nature of continuity in learning problems, (C2) the choice of appropriate spaces and metrics for measuring similarity, and (C3) the role of learning objectives beyond classification. For each challenge, we provide specific recommendations to help move the field forward, including formalizing temporal dynamics through distribution processes, developing principled approaches for continuous task spaces, and incorporating density estimation and generative objectives. In so doing, this position paper aims to broaden the scope of CL research while strengthening its theoretical foundations, making it more applicable to real-world problems.
Adaptive AI-based Decentralized Resource Management in the Cloud-Edge Continuum
Jan 27, 2025The increasing complexity of application requirements and the dynamic nature of the Cloud-Edge Continuum present significant challenges for efficient resource management. These challenges stem from the ever-changing infrastructure, which is characterized by additions, removals, and reconfigurations of nodes and links, as well as the variability of application workloads. Traditional centralized approaches struggle to adapt to these changes due to their static nature, while decentralized solutions face challenges such as limited global visibility and coordination overhead. This paper proposes a hybrid decentralized framework for dynamic application placement and resource management. The framework utilizes Graph Neural Networks (GNNs) to embed resource and application states, enabling comprehensive representation and efficient decision-making. It employs a collaborative multi-agent reinforcement learning (MARL) approach, where local agents optimize resource management in their neighborhoods and a global orchestrator ensures system-wide coordination. By combining decentralized application placement with centralized oversight, our framework addresses the scalability, adaptability, and accuracy challenges inherent in the Cloud-Edge Continuum. This work contributes to the development of decentralized application placement strategies, the integration of GNN embeddings, and collaborative MARL systems, providing a foundation for efficient, adaptive and scalable resource management.
Continually Learn to Map Visual Concepts to Large Language Models in Resource-constrained Environments
Jul 11, 2024



Learning continually from a stream of non-i.i.d. data is an open challenge in deep learning, even more so when working in resource-constrained environments such as embedded devices. Visual models that are continually updated through supervised learning are often prone to overfitting, catastrophic forgetting, and biased representations. On the other hand, large language models contain knowledge about multiple concepts and their relations, which can foster a more robust, informed and coherent learning process. This work proposes Continual Visual Mapping (CVM), an approach that continually ground vision representations to a knowledge space extracted from a fixed Language model. Specifically, CVM continually trains a small and efficient visual model to map its representations into a conceptual space established by a fixed Large Language Model. Due to their smaller nature, CVM can be used when directly adapting large visual pre-trained models is unfeasible due to computational or data constraints. CVM overcome state-of-the-art continual learning methods on five benchmarks and offers a promising avenue for addressing generalization capabilities in continual learning, even in computationally constrained devices.