 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAM: Hierarchical Adapter Merging for Scalable Continual Learning
Sep 16, 2025Continual learning is an essential capability of human cognition, yet it poses significant challenges for current deep learning models. The primary issue is that new knowledge can interfere with previously learned information, causing the model to forget earlier knowledge in favor of the new, a phenomenon known as catastrophic forgetting. Although large pre-trained models can partially mitigate forgetting by leveraging their existing knowledge and over-parameterization, they often struggle when confronted with novel data distributions. Parameter-Efficient Fine-Tuning (PEFT) methods, such as LoRA, enable efficient adaptation to new knowledge. However, they still face challenges in scaling to dynamic learning scenarios and long sequences of tasks, as maintaining one adapter per task introduces complexity and increases the potential for interference. In this paper, we introduce Hierarchical Adapters Merging (HAM), a novel framework that dynamically combines adapters from different tasks during training. This approach enables HAM to scale effectively, allowing it to manage more tasks than competing baselines with improved efficiency. To achieve this, HAM maintains a fixed set of groups that hierarchically consolidate new adapters. For each task, HAM trains a low-rank adapter along with an importance scalar, then dynamically groups tasks based on adapter similarity. Within each group, adapters are pruned, scaled and merge, facilitating transfer learning between related tasks. Extensive experiments on three vision benchmarks show that HAM significantly outperforms state-of-the-art methods, particularly as the number of tasks increases.
Parameter-Efficient Continual Fine-Tuning: A Survey
Apr 18, 2025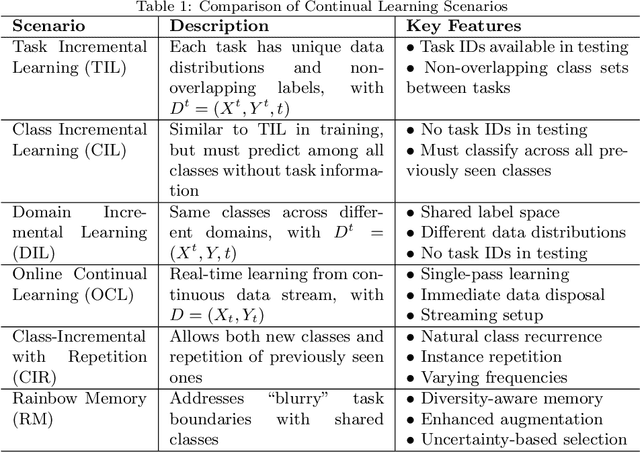

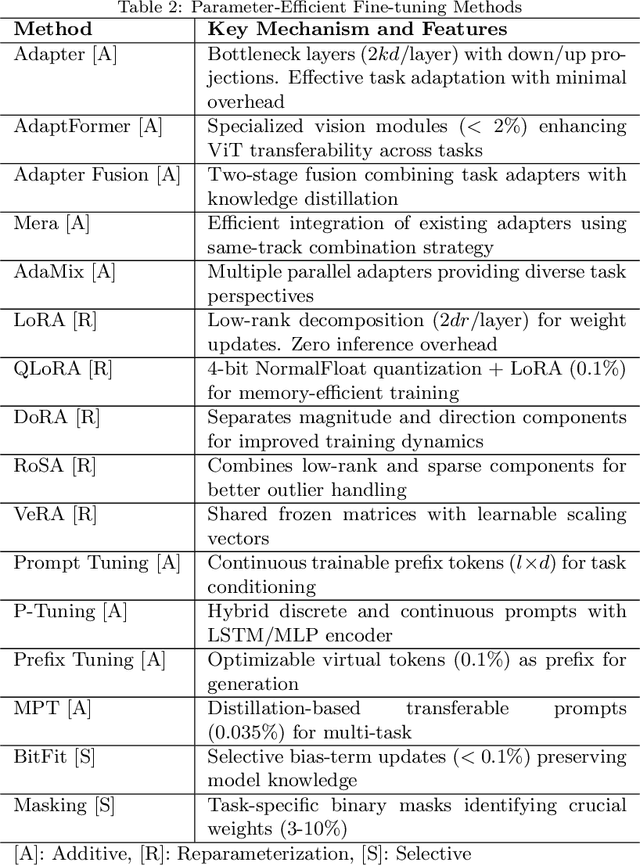
The emergence of large pre-trained networks has revolutionized the AI field, unlocking new possibilities and achieving unprecedented performance. However, these models inherit a fundamental limitation from traditional Machine Learning approaches: their strong dependence on the \textit{i.i.d.} assumption hinders their adaptability to dynamic learning scenarios. We believe the next breakthrough in AI lies in enabling efficient adaptation to evolving environments -- such as the real world -- where new data and tasks arrive sequentially. This challenge defines the field of Continual Learning (CL), a Machine Learning paradigm focused on developing lifelong learning neural models. One alternative to efficiently adapt these large-scale models is known Parameter-Efficient Fine-Tuning (PEFT). These methods tackle the issue of adapting the model to a particular data or scenario by performing small and efficient modifications, achieving similar performance to full fine-tuning. However, these techniques still lack the ability to adjust the model to multiple tasks continually, as they suffer from the issue of Catastrophic Forgetting. In this survey, we first provide an overview of CL algorithms and PEFT methods before reviewing the state-of-the-art on Parameter-Efficient Continual Fine-Tuning (PECFT). We examine various approaches, discuss evaluation metrics, and explore potential future research directions. Our goal is to highlight the synergy between CL and Parameter-Efficient Fine-Tuning, guide researchers in this field, and pave the way for novel future research directions.
In-context Interference in Chat-based Large Language Models
Sep 22, 2023
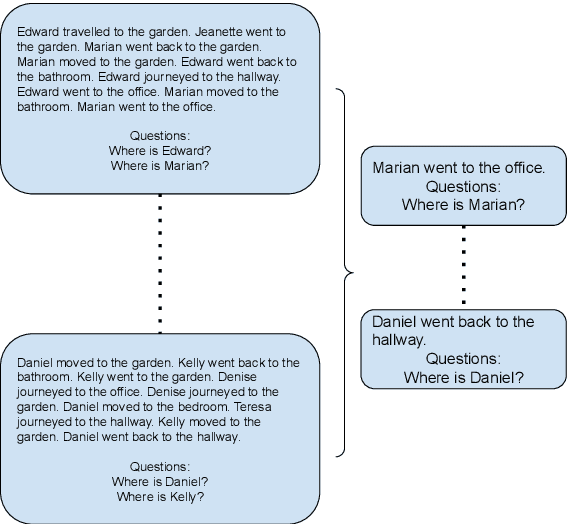
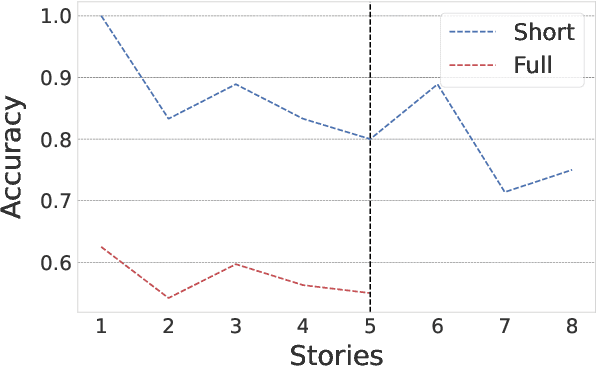
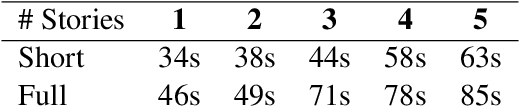
Large language models (LLMs) have had a huge impact on society due to their impressive capabilities and vast knowledge of the world. Various applications and tools have been created that allow users to interact with these models in a black-box scenario. However, one limitation of this scenario is that users cannot modify the internal knowledge of the model, and the only way to add or modify internal knowledge is by explicitly mentioning it to the model during the current interaction. This learning process is called in-context training, and it refers to training that is confined to the user's current session or context. In-context learning has significant applications, but also has limitations that are seldom studied. In this paper, we present a study that shows how the model can suffer from interference between information that continually flows in the context, causing it to forget previously learned knowledge, which can reduce the model's performance. Along with showing the problem, we propose an evaluation benchmark based on the bAbI dataset.