 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAM: Hierarchical Adapter Merging for Scalable Continual Learning
Sep 16, 2025



Continual learning is an essential capability of human cognition, yet it poses significant challenges for current deep learning models. The primary issue is that new knowledge can interfere with previously learned information, causing the model to forget earlier knowledge in favor of the new, a phenomenon known as catastrophic forgetting. Although large pre-trained models can partially mitigate forgetting by leveraging their existing knowledge and over-parameterization, they often struggle when confronted with novel data distributions. Parameter-Efficient Fine-Tuning (PEFT) methods, such as LoRA, enable efficient adaptation to new knowledge. However, they still face challenges in scaling to dynamic learning scenarios and long sequences of tasks, as maintaining one adapter per task introduces complexity and increases the potential for interference. In this paper, we introduce Hierarchical Adapters Merging (HAM), a novel framework that dynamically combines adapters from different tasks during training. This approach enables HAM to scale effectively, allowing it to manage more tasks than competing baselines with improved efficiency. To achieve this, HAM maintains a fixed set of groups that hierarchically consolidate new adapters. For each task, HAM trains a low-rank adapter along with an importance scalar, then dynamically groups tasks based on adapter similarity. Within each group, adapters are pruned, scaled and merge, facilitating transfer learning between related tasks. Extensive experiments on three vision benchmarks show that HAM significantly outperforms state-of-the-art methods, particularly as the number of tasks increases.
Parameter-Efficient Continual Fine-Tuning: A Survey
Apr 18, 2025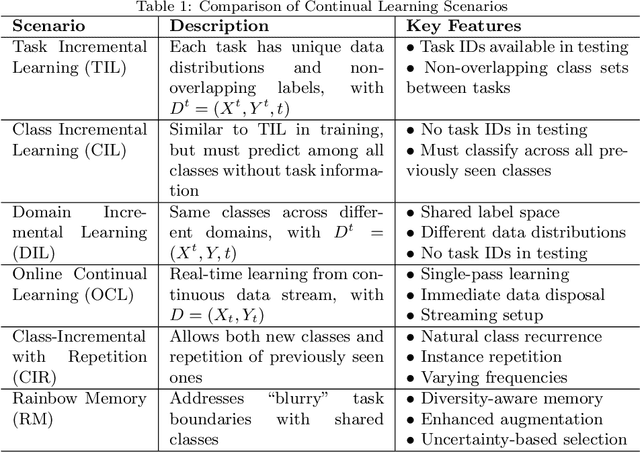

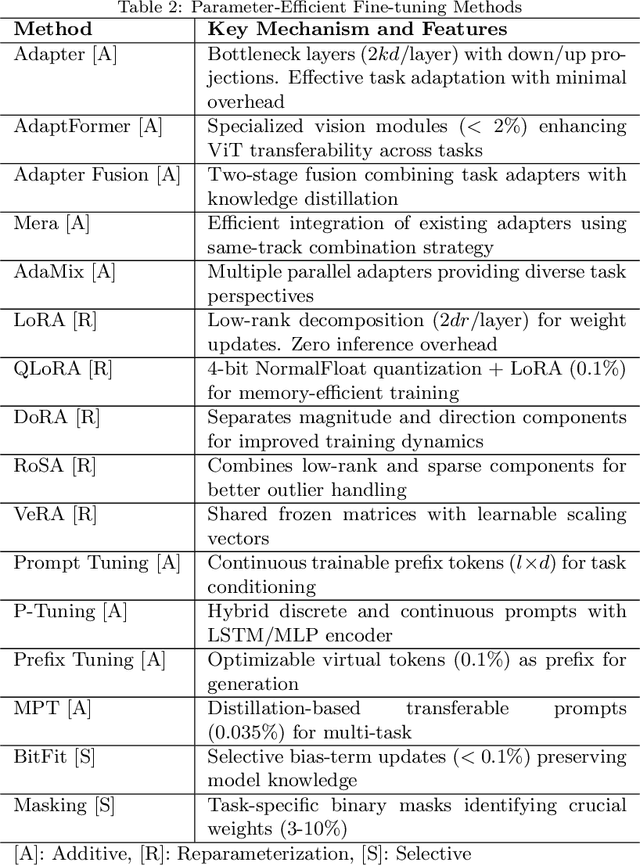
The emergence of large pre-trained networks has revolutionized the AI field, unlocking new possibilities and achieving unprecedented performance. However, these models inherit a fundamental limitation from traditional Machine Learning approaches: their strong dependence on the \textit{i.i.d.} assumption hinders their adaptability to dynamic learning scenarios. We believe the next breakthrough in AI lies in enabling efficient adaptation to evolving environments -- such as the real world -- where new data and tasks arrive sequentially. This challenge defines the field of Continual Learning (CL), a Machine Learning paradigm focused on developing lifelong learning neural models. One alternative to efficiently adapt these large-scale models is known Parameter-Efficient Fine-Tuning (PEFT). These methods tackle the issue of adapting the model to a particular data or scenario by performing small and efficient modifications, achieving similar performance to full fine-tuning. However, these techniques still lack the ability to adjust the model to multiple tasks continually, as they suffer from the issue of Catastrophic Forgetting. In this survey, we first provide an overview of CL algorithms and PEFT methods before reviewing the state-of-the-art on Parameter-Efficient Continual Fine-Tuning (PECFT). We examine various approaches, discuss evaluation metrics, and explore potential future research directions. Our goal is to highlight the synergy between CL and Parameter-Efficient Fine-Tuning, guide researchers in this field, and pave the way for novel future research directions.
Anomaly detection using Diffusion-based methods
Dec 10, 2024This paper explores the utility of diffusion-based models for anomaly detection, focusing on their efficacy in identifying deviations in both compact and high-resolution datasets. Diffusion-based architectures, including Denoising Diffusion Probabilistic Models (DDPMs) and Diffusion Transformers (DiTs), are evaluated for their performance using reconstruction objectives. By leveraging the strengths of these models, this study benchmarks their performance against traditional anomaly detection methods such as Isolation Forests, One-Class SVMs, and COPOD. The results demonstrate the superior adaptability, scalability, and robustness of diffusion-based methods in handling complex real-world anomaly detection tasks. Key findings highlight the role of reconstruction error in enhancing detection accuracy and underscore the scalability of these models to high-dimensional datasets. Future directions include optimizing encoder-decoder architectures and exploring multi-modal datasets to further advance diffusion-based anomaly detection.
Deep evolving semi-supervised anomaly detection
Dec 01, 2024The aim of this paper is to formalise the task of continual semi-supervised anomaly detection (CSAD), with the aim of highlighting the importance of such a problem formulation which assumes as close to real-world conditions as possible. After an overview of the relevant definitions of continual semi-supervised learning, its components, anomaly detection extension, and the training protocols; the paper introduces a baseline model of a variational autoencoder (VAE) to work with semi-supervised data along with a continual learning method of deep generative replay with outlier rejection. The results show that such a use of extreme value theory (EVT) applied to anomaly detection can provide promising results even in comparison to an upper baseline of joint training. The results explore the effects of how much labelled and unlabelled data is present, of which class, and where it is located in the data stream. Outlier rejection shows promising initial results where it often surpasses a baseline method of Elastic Weight Consolidation (EWC). A baseline for CSAD is put forward along with the specific dataset setups used for reproducability and testability for other practitioners. Future research directions include other CSAD settings and further research into efficient continual hyperparameter tuning.
Universal Adversarial Framework to Improve Adversarial Robustness for Diabetic Retinopathy Detection
Dec 13, 2023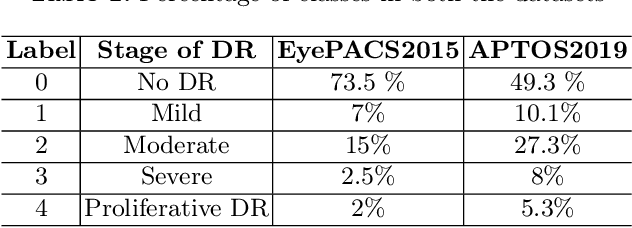
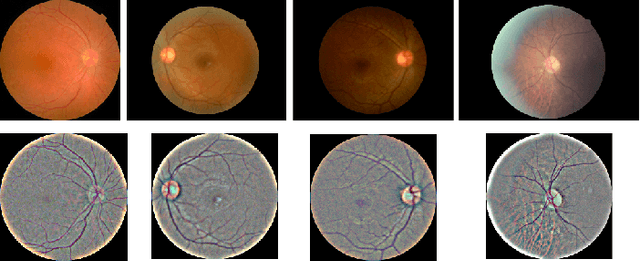
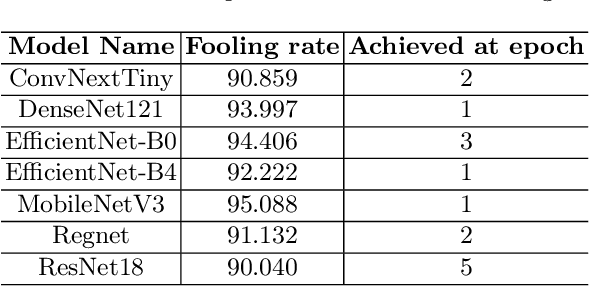
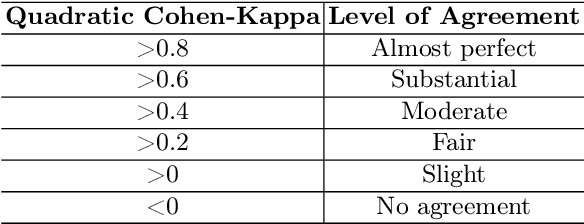
Diabetic Retinopathy (DR) is a prevalent illness associated with Diabetes which, if left untreated, can result in irreversible blindness. Deep Learning based systems are gradually being introduced as automated support for clinical diagnosis. Since healthcare has always been an extremely important domain demanding error-free performance, any adversaries could pose a big threat to the applicability of such systems. In this work, we use Universal Adversarial Perturbations (UAPs) to quantify the vulnerability of Medical Deep Neural Networks (DNNs) for detecting DR. To the best of our knowledge, this is the very first attempt that works on attacking complete fine-grained classification of DR images using various UAPs. Also, as a part of this work, we use UAPs to fine-tune the trained models to defend against adversarial samples. We experiment on several models and observe that the performance of such models towards unseen adversarial attacks gets boosted on average by $3.41$ Cohen-kappa value and maximum by $31.92$ Cohen-kappa value. The performance degradation on normal data upon ensembling the fine-tuned models was found to be statistically insignificant using t-test, highlighting the benefits of UAP-based adversarial fine-tuning.
Impact of Visual Context on Noisy Multimodal NMT: An Empirical Study for English to Indian Languages
Aug 30, 2023The study investigates the effectiveness of utilizing multimodal information in Neural Machine Translation (NMT). While prior research focused on using multimodal data in low-resource scenarios, this study examines how image features impact translation when added to a large-scale, pre-trained unimodal NMT system. Surprisingly, the study finds that images might be redundant in this context. Additionally, the research introduces synthetic noise to assess whether images help the model deal with textual noise. Multimodal models slightly outperform text-only models in noisy settings, even with random images. The study's experiments translate from English to Hindi, Bengali, and Malayalam, outperforming state-of-the-art benchmarks significantly. Interestingly, the effect of visual context varies with source text noise: no visual context works best for non-noisy translations, cropped image features are optimal for low noise, and full image features work better in high-noise scenarios. This sheds light on the role of visual context, especially in noisy settings, opening up a new research direction for Noisy Neural Machine Translation in multimodal setups. The research emphasizes the importance of combining visual and textual information for improved translation in various environments.