 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Linguistic Divide: A Survey on Leveraging Large Language Models for Machine Translation
Apr 03, 2025The advent of Large Language Models (LLMs) has significantly reshaped the landscape of machine translation (MT), particularly for low-resource languages and domains that lack sufficient parallel corpora, linguistic tools, and computational infrastructure. This survey presents a comprehensive overview of recent progress in leveraging LLMs for MT. We analyze techniques such as few-shot prompting, cross-lingual transfer, and parameter-efficient fine-tuning that enable effective adaptation to under-resourced settings. The paper also explores synthetic data generation strategies using LLMs, including back-translation and lexical augmentation. Additionally, we compare LLM-based translation with traditional encoder-decoder models across diverse language pairs, highlighting the strengths and limitations of each. We discuss persistent challenges such as hallucinations, evaluation inconsistencies, and inherited biases while also evaluating emerging LLM-driven metrics for translation quality. This survey offers practical insights and outlines future directions for building robust, inclusive, and scalable MT systems in the era of large-scale generative models.
Thinking Machines: A Survey of LLM based Reasoning Strategies
Mar 13, 2025Large Language Models (LLMs) are highly proficient in language-based tasks. Their language capabilities have positioned them at the forefront of the future AGI (Artificial General Intelligence) race. However, on closer inspection, Valmeekam et al. (2024); Zecevic et al. (2023); Wu et al. (2024) highlight a significant gap between their language proficiency and reasoning abilities. Reasoning in LLMs and Vision Language Models (VLMs) aims to bridge this gap by enabling these models to think and re-evaluate their actions and responses. Reasoning is an essential capability for complex problem-solving and a necessary step toward establishing trust in Artificial Intelligence (AI). This will make AI suitable for deployment in sensitive domains, such as healthcare, banking, law, defense, security etc. In recent times, with the advent of powerful reasoning models like OpenAI O1 and DeepSeek R1, reasoning endowment has become a critical research topic in LLMs. In this paper, we provide a detailed overview and comparison of existing reasoning techniques and present a systematic survey of reasoning-imbued language models. We also study current challenges and present our findings.
Seeing Through VisualBERT: A Causal Adventure on Memetic Landscapes
Oct 17, 2024

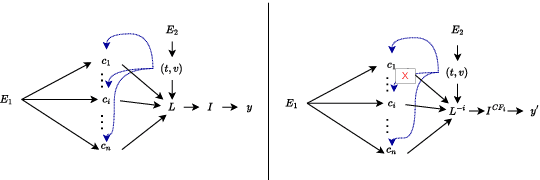
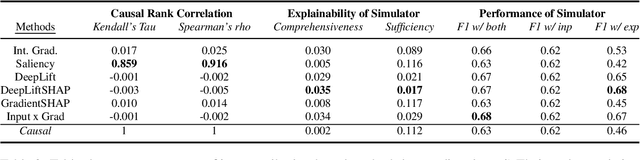
Detecting offensive memes is crucial, yet standard deep neural network systems often remain opaque. Various input attribution-based methods attempt to interpret their behavior, but they face challenges with implicitly offensive memes and non-causal attributions. To address these issues, we propose a framework based on a Structural Causal Model (SCM). In this framework, VisualBERT is trained to predict the class of an input meme based on both meme input and causal concepts, allowing for transparent interpretation. Our qualitative evaluation demonstrates the framework's effectiveness in understanding model behavior, particularly in determining whether the model was right due to the right reason, and in identifying reasons behind misclassification. Additionally, quantitative analysis assesses the significance of proposed modelling choices, such as de-confounding, adversarial learning, and dynamic routing, and compares them with input attribution methods. Surprisingly, we find that input attribution methods do not guarantee causality within our framework, raising questions about their reliability in safety-critical applications. The project page is at: https://newcodevelop.github.io/causality_adventure/
Universal Adversarial Framework to Improve Adversarial Robustness for Diabetic Retinopathy Detection
Dec 13, 2023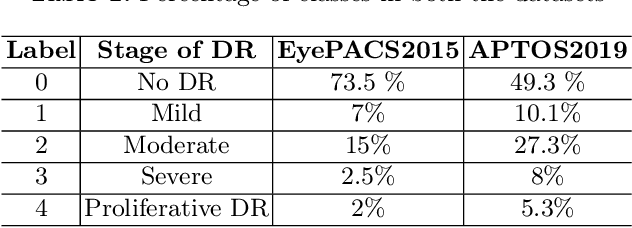
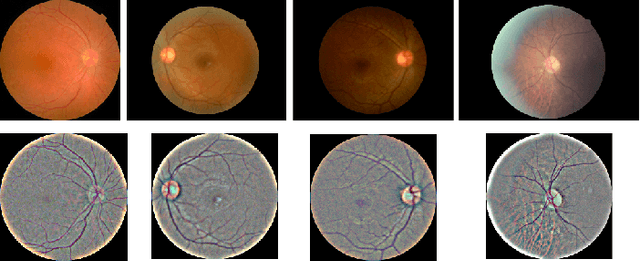
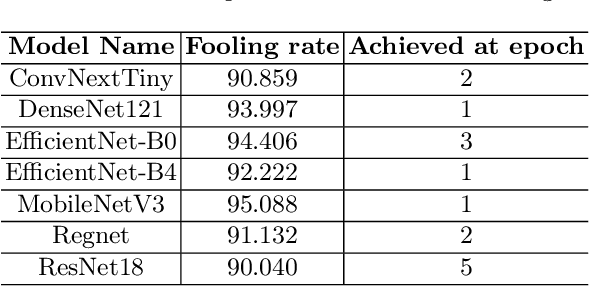
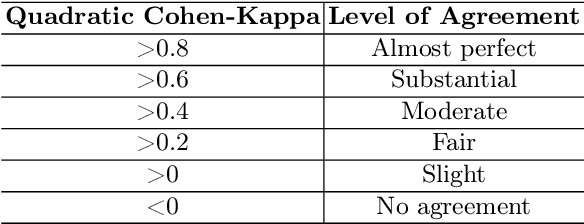
Diabetic Retinopathy (DR) is a prevalent illness associated with Diabetes which, if left untreated, can result in irreversible blindness. Deep Learning based systems are gradually being introduced as automated support for clinical diagnosis. Since healthcare has always been an extremely important domain demanding error-free performance, any adversaries could pose a big threat to the applicability of such systems. In this work, we use Universal Adversarial Perturbations (UAPs) to quantify the vulnerability of Medical Deep Neural Networks (DNNs) for detecting DR. To the best of our knowledge, this is the very first attempt that works on attacking complete fine-grained classification of DR images using various UAPs. Also, as a part of this work, we use UAPs to fine-tune the trained models to defend against adversarial samples. We experiment on several models and observe that the performance of such models towards unseen adversarial attacks gets boosted on average by $3.41$ Cohen-kappa value and maximum by $31.92$ Cohen-kappa value. The performance degradation on normal data upon ensembling the fine-tuned models was found to be statistically insignificant using t-test, highlighting the benefits of UAP-based adversarial fine-tuning.
Impact of Visual Context on Noisy Multimodal NMT: An Empirical Study for English to Indian Languages
Aug 30, 2023The study investigates the effectiveness of utilizing multimodal information in Neural Machine Translation (NMT). While prior research focused on using multimodal data in low-resource scenarios, this study examines how image features impact translation when added to a large-scale, pre-trained unimodal NMT system. Surprisingly, the study finds that images might be redundant in this context. Additionally, the research introduces synthetic noise to assess whether images help the model deal with textual noise. Multimodal models slightly outperform text-only models in noisy settings, even with random images. The study's experiments translate from English to Hindi, Bengali, and Malayalam, outperforming state-of-the-art benchmarks significantly. Interestingly, the effect of visual context varies with source text noise: no visual context works best for non-noisy translations, cropped image features are optimal for low noise, and full image features work better in high-noise scenarios. This sheds light on the role of visual context, especially in noisy settings, opening up a new research direction for Noisy Neural Machine Translation in multimodal setups. The research emphasizes the importance of combining visual and textual information for improved translation in various environments.
IITP at WAT 2021: System description for English-Hindi Multimodal Translation Task
Jul 04, 2021


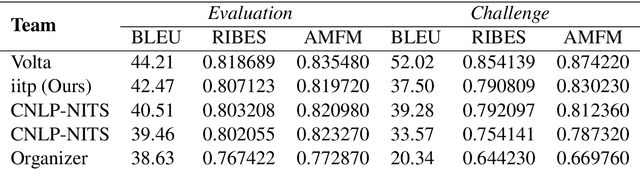
Neural Machine Translation (NMT) is a predominant machine translation technology nowadays because of its end-to-end trainable flexibility. However, NMT still struggles to translate properly in low-resource settings specifically on distant language pairs. One way to overcome this is to use the information from other modalities if available. The idea is that despite differences in languages, both the source and target language speakers see the same thing and the visual representation of both the source and target is the same, which can positively assist the system. Multimodal information can help the NMT system to improve the translation by removing ambiguity on some phrases or words. We participate in the 8th Workshop on Asian Translation (WAT - 2021) for English-Hindi multimodal translation task and achieve 42.47 and 37.50 BLEU points for Evaluation and Challenge subset, respectively.
IITP at AILA 2019: System Report for Artificial Intelligence for Legal Assistance Shared Task
May 24, 2021
In this article, we present a description of our systems as a part of our participation in the shared task namely Artificial Intelligence for Legal Assistance (AILA 2019). This is an integral event of Forum for Information Retrieval Evaluation-2019. The outcomes of this track would be helpful for the automation of the working process of the Indian Judiciary System. The manual working procedures and documentation at any level (from lower to higher court) of the judiciary system are very complex in nature. The systems produced as a part of this track would assist the law practitioners. It would be helpful for common men too. This kind of track also opens the path of research of Natural Language Processing (NLP) in the judicial domain. This track defined two problems such as Task 1: Identifying relevant prior cases for a given situation and Task 2: Identifying the most relevant statutes for a given situation. We tackled both of them. Our proposed approaches are based on BM25 and Doc2Vec. As per the results declared by the task organizers, we are in 3rd and a modest position in Task 1 and Task 2 respectively.
IITP in COLIEE@ICAIL 2019: Legal Information Retrieval using BM25 and BERT
Apr 29, 2021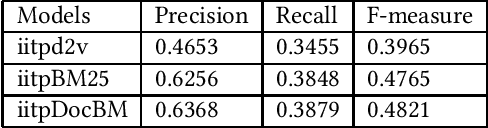
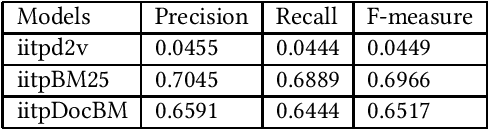
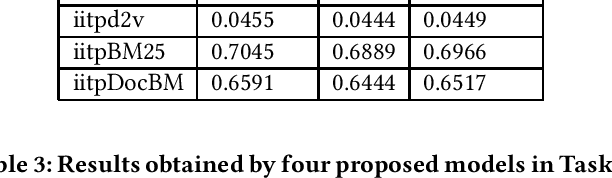
Natural Language Processing (NLP) and Information Retrieval (IR) in the judicial domain is an essential task. With the advent of availability domain-specific data in electronic form and aid of different Artificial intelligence (AI) technologies, automated language processing becomes more comfortable, and hence it becomes feasible for researchers and developers to provide various automated tools to the legal community to reduce human burden. The Competition on Legal Information Extraction/Entailment (COLIEE-2019) run in association with the International Conference on Artificial Intelligence and Law (ICAIL)-2019 has come up with few challenging tasks. The shared defined four sub-tasks (i.e. Task1, Task2, Task3 and Task4), which will be able to provide few automated systems to the judicial system. The paper presents our working note on the experiments carried out as a part of our participation in all the sub-tasks defined in this shared task. We make use of different Information Retrieval(IR) and deep learning based approaches to tackle these problems. We obtain encouraging results in all these four sub-tasks.
IITP at MEDIQA 2019: Systems Report for Natural Language Inference, Question Entailment and Question Answering
Jun 14, 2019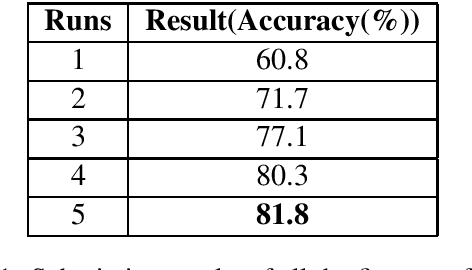
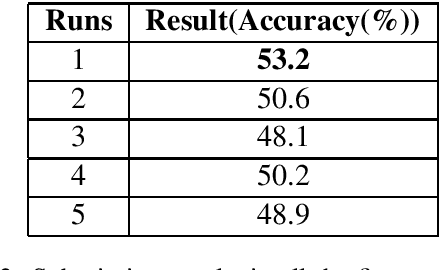
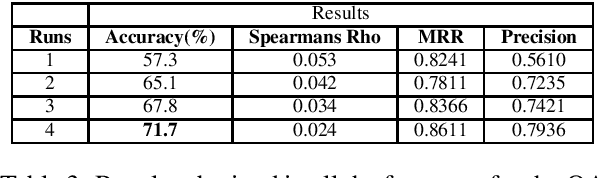
This paper presents the experiments accomplished as a part of our participation in the MEDIQA challenge, an (Abacha et al., 2019) shared task. We participated in all the three tasks defined in this particular shared task. The tasks are viz. i. Natural Language Inference (NLI) ii. Recognizing Question Entailment(RQE) and their application in medical Question Answering (QA). We submitted runs using multiple deep learning based systems (runs) for each of these three tasks. We submitted five system results in each of the NLI and RQE tasks, and four system results for the QA task. The systems yield encouraging results in all three tasks. The highest performance obtained in NLI, RQE and QA tasks are 81.8%, 53.2%, and 71.7%, respectively.