 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Probabilistic Trees and Causal Networks for Clinical and Epidemiological Data
Jan 27, 2025


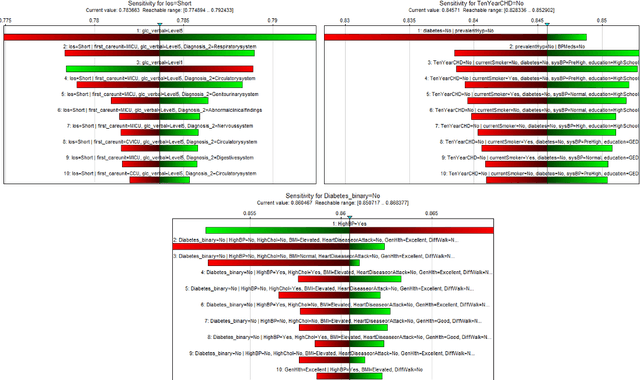
Healthcare decision-making requires not only accurate predictions but also insights into how factors influence patient outcomes. While traditional Machine Learning (ML) models excel at predicting outcomes, such as identifying high risk patients, they are limited in addressing what-if questions about interventions. This study introduces the Probabilistic Causal Fusion (PCF) framework, which integrates Causal Bayesian Networks (CBNs) and Probability Trees (PTrees) to extend beyond predictions. PCF leverages causal relationships from CBNs to structure PTrees, enabling both the quantification of factor impacts and simulation of hypothetical interventions. PCF was validated on three real-world healthcare datasets i.e. MIMIC-IV, Framingham Heart Study, and Diabetes, chosen for their clinically diverse variables. It demonstrated predictive performance comparable to traditional ML models while providing additional causal reasoning capabilities. To enhance interpretability, PCF incorporates sensitivity analysis and SHapley Additive exPlanations (SHAP). Sensitivity analysis quantifies the influence of causal parameters on outcomes such as Length of Stay (LOS), Coronary Heart Disease (CHD), and Diabetes, while SHAP highlights the importance of individual features in predictive modeling. By combining causal reasoning with predictive modeling, PCF bridges the gap between clinical intuition and data-driven insights. Its ability to uncover relationships between modifiable factors and simulate hypothetical scenarios provides clinicians with a clearer understanding of causal pathways. This approach supports more informed, evidence-based decision-making, offering a robust framework for addressing complex questions in diverse healthcare settings.
Seeing Through VisualBERT: A Causal Adventure on Memetic Landscapes
Oct 17, 2024

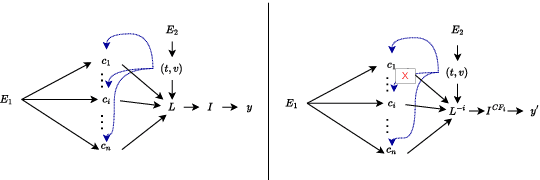
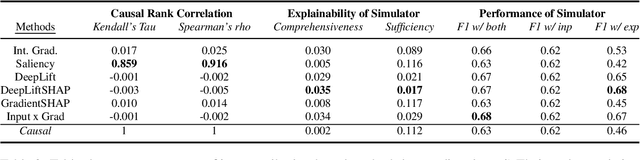
Detecting offensive memes is crucial, yet standard deep neural network systems often remain opaque. Various input attribution-based methods attempt to interpret their behavior, but they face challenges with implicitly offensive memes and non-causal attributions. To address these issues, we propose a framework based on a Structural Causal Model (SCM). In this framework, VisualBERT is trained to predict the class of an input meme based on both meme input and causal concepts, allowing for transparent interpretation. Our qualitative evaluation demonstrates the framework's effectiveness in understanding model behavior, particularly in determining whether the model was right due to the right reason, and in identifying reasons behind misclassification. Additionally, quantitative analysis assesses the significance of proposed modelling choices, such as de-confounding, adversarial learning, and dynamic routing, and compares them with input attribution methods. Surprisingly, we find that input attribution methods do not guarantee causality within our framework, raising questions about their reliability in safety-critical applications. The project page is at: https://newcodevelop.github.io/causality_adventure/
Investigating the validity of structure learning algorithms in identifying risk factors for intervention in patients with diabetes
Mar 21, 2024



Diabetes, a pervasive and enduring health challenge, imposes significant global implications on health, financial healthcare systems, and societal well-being. This study undertakes a comprehensive exploration of various structural learning algorithms to discern causal pathways amongst potential risk factors influencing diabetes progression. The methodology involves the application of these algorithms to relevant diabetes data, followed by the conversion of their output graphs into Causal Bayesian Networks (CBNs), enabling predictive analysis and the evaluation of discrepancies in the effect of hypothetical interventions within our context-specific case study. This study highlights the substantial impact of algorithm selection on intervention outcomes. To consolidate insights from diverse algorithms, we employ a model-averaging technique that helps us obtain a unique causal model for diabetes derived from a varied set of structural learning algorithms. We also investigate how each of those individual graphs, as well as the average graph, compare to the structures elicited by a domain expert who categorised graph edges into high confidence, moderate, and low confidence types, leading into three individual graphs corresponding to the three levels of confidence. The resulting causal model and data are made available online, and serve as a valuable resource and a guide for informed decision-making by healthcare practitioners, offering a comprehensive understanding of the interactions between relevant risk factors and the effect of hypothetical interventions. Therefore, this research not only contributes to the academic discussion on diabetes, but also provides practical guidance for healthcare professionals in developing efficient intervention and risk management strategies.
Federated Split Learning with Only Positive Labels for resource-constrained IoT environment
Jul 25, 2023
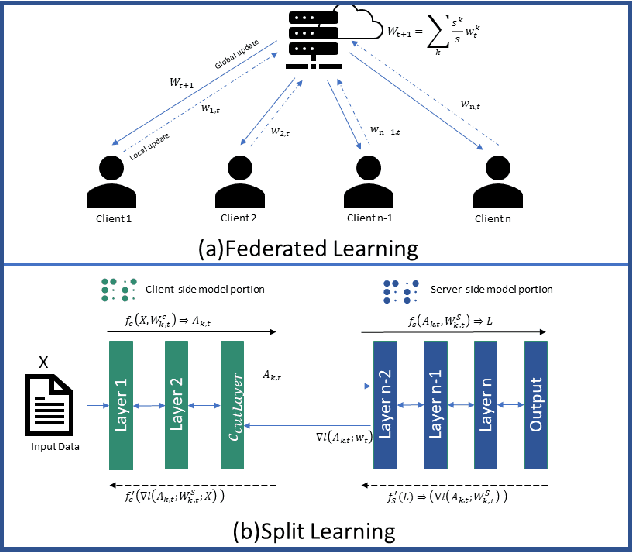


Distributed collaborative machine learning (DCML) is a promising method in the Internet of Things (IoT) domain for training deep learning models, as data is distributed across multiple devices. A key advantage of this approach is that it improves data privacy by removing the necessity for the centralized aggregation of raw data but also empowers IoT devices with low computational power. Among various techniques in a DCML framework, federated split learning, known as splitfed learning (SFL), is the most suitable for efficient training and testing when devices have limited computational capabilities. Nevertheless, when resource-constrained IoT devices have only positive labeled data, multiclass classification deep learning models in SFL fail to converge or provide suboptimal results. To overcome these challenges, we propose splitfed learning with positive labels (SFPL). SFPL applies a random shuffling function to the smashed data received from clients before supplying it to the server for model training. Additionally, SFPL incorporates the local batch normalization for the client-side model portion during the inference phase. Our results demonstrate that SFPL outperforms SFL: (i) by factors of 51.54 and 32.57 for ResNet-56 and ResNet-32, respectively, with the CIFAR-100 dataset, and (ii) by factors of 9.23 and 8.52 for ResNet-32 and ResNet-8, respectively, with CIFAR-10 dataset. Overall, this investigation underscores the efficacy of the proposed SFPL framework in DCML.
Enabling Deep Learning for All-in EDGE paradigm
Apr 07, 2022



Deep Learning-based models have been widely investigated, and they have demonstrated significant performance on non-trivial tasks such as speech recognition, image processing, and natural language understanding. However, this is at the cost of substantial data requirements. Considering the widespread proliferation of edge devices (e.g. Internet of Things devices) over the last decade, Deep Learning in the edge paradigm, such as device-cloud integrated platforms, is required to leverage its superior performance. Moreover, it is suitable from the data requirements perspective in the edge paradigm because the proliferation of edge devices has resulted in an explosion in the volume of generated and collected data. However, there are difficulties due to other requirements such as high computation, high latency, and high bandwidth caused by Deep Learning applications in real-world scenarios. In this regard, this survey paper investigates Deep Learning at the edge, its architecture, enabling technologies, and model adaption techniques, where edge servers and edge devices participate in deep learning training and inference. For simplicity, we call this paradigm the All-in EDGE paradigm. Besides, this paper presents the key performance metrics for Deep Learning at the All-in EDGE paradigm to evaluate various deep learning techniques and choose a suitable design. Moreover, various open challenges arising from the deployment of Deep Learning at the All-in EDGE paradigm are identified and discussed.
The Verbal and Non Verbal Signals of Depression -- Combining Acoustics, Text and Visuals for Estimating Depression Level
Apr 02, 2019
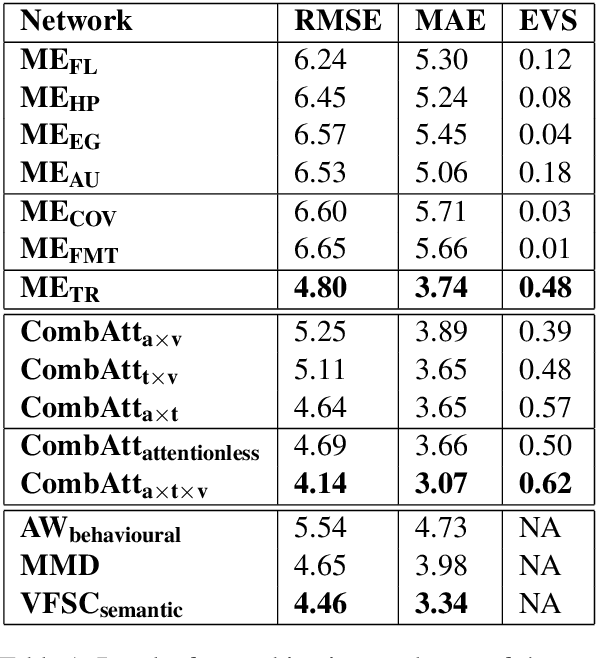
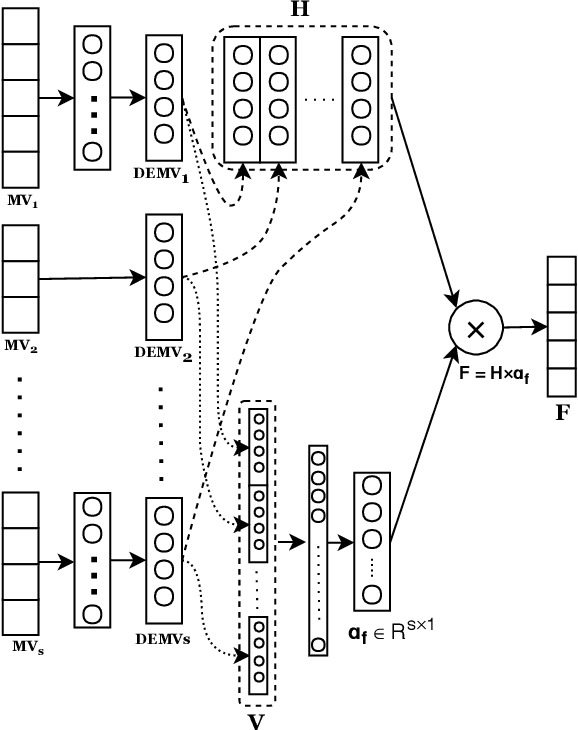
Depression is a serious medical condition that is suffered by a large number of people around the world. It significantly affects the way one feels, causing a persistent lowering of mood. In this paper, we propose a novel attention-based deep neural network which facilitates the fusion of various modalities. We use this network to regress the depression level. Acoustic, text and visual modalities have been used to train our proposed network. Various experiments have been carried out on the benchmark dataset, namely, Distress Analysis Interview Corpus - a Wizard of Oz (DAIC-WOZ). From the results, we empirically justify that the fusion of all three modalities helps in giving the most accurate estimation of depression level. Our proposed approach outperforms the state-of-the-art by 7.17% on root mean squared error (RMSE) and 8.08% on mean absolute error (MAE).