 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Split Learning with Only Positive Labels for resource-constrained IoT environment
Jul 25, 2023
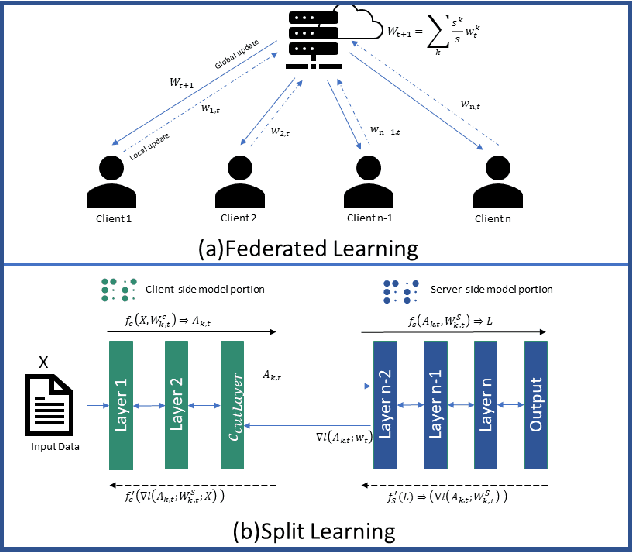


Distributed collaborative machine learning (DCML) is a promising method in the Internet of Things (IoT) domain for training deep learning models, as data is distributed across multiple devices. A key advantage of this approach is that it improves data privacy by removing the necessity for the centralized aggregation of raw data but also empowers IoT devices with low computational power. Among various techniques in a DCML framework, federated split learning, known as splitfed learning (SFL), is the most suitable for efficient training and testing when devices have limited computational capabilities. Nevertheless, when resource-constrained IoT devices have only positive labeled data, multiclass classification deep learning models in SFL fail to converge or provide suboptimal results. To overcome these challenges, we propose splitfed learning with positive labels (SFPL). SFPL applies a random shuffling function to the smashed data received from clients before supplying it to the server for model training. Additionally, SFPL incorporates the local batch normalization for the client-side model portion during the inference phase. Our results demonstrate that SFPL outperforms SFL: (i) by factors of 51.54 and 32.57 for ResNet-56 and ResNet-32, respectively, with the CIFAR-100 dataset, and (ii) by factors of 9.23 and 8.52 for ResNet-32 and ResNet-8, respectively, with CIFAR-10 dataset. Overall, this investigation underscores the efficacy of the proposed SFPL framework in DCML.
Enabling Deep Learning for All-in EDGE paradigm
Apr 07, 2022



Deep Learning-based models have been widely investigated, and they have demonstrated significant performance on non-trivial tasks such as speech recognition, image processing, and natural language understanding. However, this is at the cost of substantial data requirements. Considering the widespread proliferation of edge devices (e.g. Internet of Things devices) over the last decade, Deep Learning in the edge paradigm, such as device-cloud integrated platforms, is required to leverage its superior performance. Moreover, it is suitable from the data requirements perspective in the edge paradigm because the proliferation of edge devices has resulted in an explosion in the volume of generated and collected data. However, there are difficulties due to other requirements such as high computation, high latency, and high bandwidth caused by Deep Learning applications in real-world scenarios. In this regard, this survey paper investigates Deep Learning at the edge, its architecture, enabling technologies, and model adaption techniques, where edge servers and edge devices participate in deep learning training and inference. For simplicity, we call this paradigm the All-in EDGE paradigm. Besides, this paper presents the key performance metrics for Deep Learning at the All-in EDGE paradigm to evaluate various deep learning techniques and choose a suitable design. Moreover, various open challenges arising from the deployment of Deep Learning at the All-in EDGE paradigm are identified and discussed.
Splitfed learning without client-side synchronization: Analyzing client-side split network portion size to overall performance
Sep 19, 2021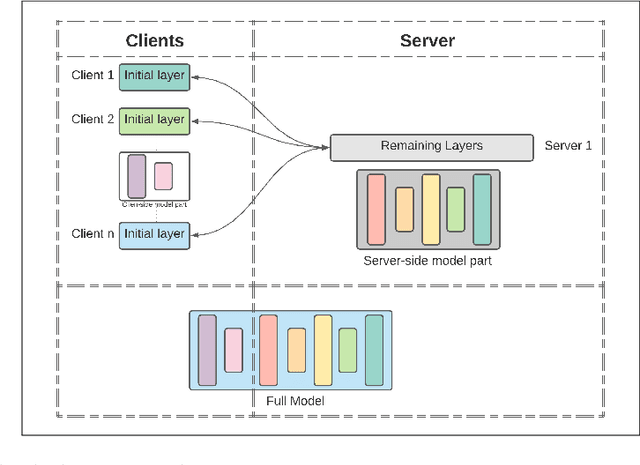


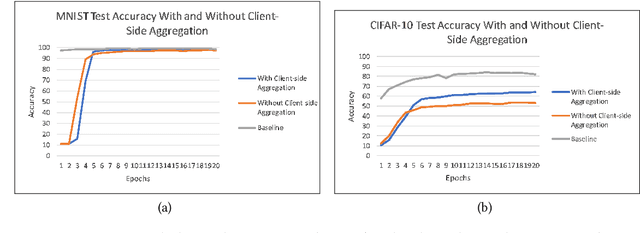
Federated Learning (FL), Split Learning (SL), and SplitFed Learning (SFL) are three recent developments in distributed machine learning that are gaining attention due to their ability to preserve the privacy of raw data. Thus, they are widely applicable in various domains where data is sensitive, such as large-scale medical image classification, internet-of-medical-things, and cross-organization phishing email detection. SFL is developed on the confluence point of FL and SL. It brings the best of FL and SL by providing parallel client-side machine learning model updates from the FL paradigm and a higher level of model privacy (while training) by splitting the model between the clients and server coming from SL. However, SFL has communication and computation overhead at the client-side due to the requirement of client-side model synchronization. For the resource-constrained client-side, removal of such requirements is required to gain efficiency in the learning. In this regard, this paper studies SFL without client-side model synchronization. The resulting architecture is known as Multi-head Split Learning. Our empirical studies considering the ResNet18 model on MNIST data under IID data distribution among distributed clients find that Multi-head Split Learning is feasible. Its performance is comparable to the SFL. Moreover, SFL provides only 1%-2% better accuracy than Multi-head Split Learning on the MNIST test set. To further strengthen our results, we study the Multi-head Split Learning with various client-side model portions and its impact on the overall performance. To this end, our results find a minimal impact on the overall performance of the model.