 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Qubit-Efficient Hybrid Quantum Encoding Mechanism for Quantum Machine Learning
Jun 24, 2025Efficiently embedding high-dimensional datasets onto noisy and low-qubit quantum systems is a significant barrier to practical Quantum Machine Learning (QML). Approaches such as quantum autoencoders can be constrained by current hardware capabilities and may exhibit vulnerabilities to reconstruction attacks due to their invertibility. We propose Quantum Principal Geodesic Analysis (qPGA), a novel, non-invertible method for dimensionality reduction and qubit-efficient encoding. Executed classically, qPGA leverages Riemannian geometry to project data onto the unit Hilbert sphere, generating outputs inherently suitable for quantum amplitude encoding. This technique preserves the neighborhood structure of high-dimensional datasets within a compact latent space, significantly reducing qubit requirements for amplitude encoding. We derive theoretical bounds quantifying qubit requirements for effective encoding onto noisy systems. Empirical results on MNIST, Fashion-MNIST, and CIFAR-10 show that qPGA preserves local structure more effectively than both quantum and hybrid autoencoders. Additionally, we demonstrate that qPGA enhances resistance to reconstruction attacks due to its non-invertible nature. In downstream QML classification tasks, qPGA can achieve over 99% accuracy and F1-score on MNIST and Fashion-MNIST, outperforming quantum-dependent baselines. Initial tests on real hardware and noisy simulators confirm its potential for noise-resilient performance, offering a scalable solution for advancing QML applications.
Rehearsal with Auxiliary-Informed Sampling for Audio Deepfake Detection
May 30, 2025The performance of existing audio deepfake detection frameworks degrades when confronted with new deepfake attacks. Rehearsal-based continual learning (CL), which updates models using a limited set of old data samples, helps preserve prior knowledge while incorporating new information. However, existing rehearsal techniques don't effectively capture the diversity of audio characteristics, introducing bias and increasing the risk of forgetting. To address this challenge, we propose Rehearsal with Auxiliary-Informed Sampling (RAIS), a rehearsal-based CL approach for audio deepfake detection. RAIS employs a label generation network to produce auxiliary labels, guiding diverse sample selection for the memory buffer. Extensive experiments show RAIS outperforms state-of-the-art methods, achieving an average Equal Error Rate (EER) of 1.953 % across five experiences. The code is available at: https://github.com/falihgoz/RAIS.
Vision Graph Non-Contrastive Learning for Audio Deepfake Detection with Limited Labels
Jan 09, 2025



Recent advancements in audio deepfake detection have leveraged graph neural networks (GNNs) to model frequency and temporal interdependencies in audio data, effectively identifying deepfake artifacts. However, the reliance of GNN-based methods on substantial labeled data for graph construction and robust performance limits their applicability in scenarios with limited labeled data. Although vast amounts of audio data exist, the process of labeling samples as genuine or fake remains labor-intensive and costly. To address this challenge, we propose SIGNL (Spatio-temporal vIsion Graph Non-contrastive Learning), a novel framework that maintains high GNN performance in low-label settings. SIGNL constructs spatio-temporal graphs by representing patches from the audio's visual spectrogram as nodes. These graph structures are modeled using vision graph convolutional (GC) encoders pre-trained through graph non-contrastive learning, a label-free that maximizes the similarity between positive pairs. The pre-trained encoders are then fine-tuned for audio deepfake detection, reducing reliance on labeled data. Experiments demonstrate that SIGNL outperforms state-of-the-art baselines across multiple audio deepfake detection datasets, achieving the lowest Equal Error Rate (EER) with as little as 5% labeled data. Additionally, SIGNL exhibits strong cross-domain generalization, achieving the lowest EER in evaluations involving diverse attack types and languages in the In-The-Wild dataset.
Computable Model-Independent Bounds for Adversarial Quantum Machine Learning
Nov 11, 2024



By leveraging the principles of quantum mechanics, QML opens doors to novel approaches in machine learning and offers potential speedup. However, machine learning models are well-documented to be vulnerable to malicious manipulations, and this susceptibility extends to the models of QML. This situation necessitates a thorough understanding of QML's resilience against adversarial attacks, particularly in an era where quantum computing capabilities are expanding. In this regard, this paper examines model-independent bounds on adversarial performance for QML. To the best of our knowledge, we introduce the first computation of an approximate lower bound for adversarial error when evaluating model resilience against sophisticated quantum-based adversarial attacks. Experimental results are compared to the computed bound, demonstrating the potential of QML models to achieve high robustness. In the best case, the experimental error is only 10% above the estimated bound, offering evidence of the inherent robustness of quantum models. This work not only advances our theoretical understanding of quantum model resilience but also provides a precise reference bound for the future development of robust QML algorithms.
A Hybrid Quantum Neural Network for Split Learning
Sep 25, 2024



Quantum Machine Learning (QML) is an emerging field of research with potential applications to distributed collaborative learning, such as Split Learning (SL). SL allows resource-constrained clients to collaboratively train ML models with a server, reduce their computational overhead, and enable data privacy by avoiding raw data sharing. Although QML with SL has been studied, the problem remains open in resource-constrained environments where clients lack quantum computing capabilities. Additionally, data privacy leakage between client and server in SL poses risks of reconstruction attacks on the server side. To address these issues, we propose Hybrid Quantum Split Learning (HQSL), an application of Hybrid QML in SL. HQSL enables classical clients to train models with a hybrid quantum server and curtails reconstruction attacks. In addition, we introduce a novel qubit-efficient data-loading technique for designing a quantum layer in HQSL, minimizing both the number of qubits and circuit depth. Experiments on five datasets demonstrate HQSL's feasibility and ability to enhance classification performance compared to its classical models. Notably, HQSL achieves mean improvements of over 3% in both accuracy and F1-score for the Fashion-MNIST dataset, and over 1.5% in both metrics for the Speech Commands dataset. We expand these studies to include up to 100 clients, confirming HQSL's scalability. Moreover, we introduce a noise-based defense mechanism to tackle reconstruction attacks on the server side. Overall, HQSL enables classical clients to collaboratively train their models with a hybrid quantum server, leveraging quantum advantages while improving model performance and security against data privacy leakage-related reconstruction attacks.
Attacking Slicing Network via Side-channel Reinforcement Learning Attack
Sep 17, 2024



Network slicing in 5G and the future 6G networks will enable the creation of multiple virtualized networks on a shared physical infrastructure. This innovative approach enables the provision of tailored networks to accommodate specific business types or industry users, thus delivering more customized and efficient services. However, the shared memory and cache in network slicing introduce security vulnerabilities that have yet to be fully addressed. In this paper, we introduce a reinforcement learning-based side-channel cache attack framework specifically designed for network slicing environments. Unlike traditional cache attack methods, our framework leverages reinforcement learning to dynamically identify and exploit cache locations storing sensitive information, such as authentication keys and user registration data. We assume that one slice network is compromised and demonstrate how the attacker can induce another shared slice to send registration requests, thereby estimating the cache locations of critical data. By formulating the cache timing channel attack as a reinforcement learning-driven guessing game between the attack slice and the victim slice, our model efficiently explores possible actions to pinpoint memory blocks containing sensitive information. Experimental results showcase the superiority of our approach, achieving a success rate of approximately 95\% to 98\% in accurately identifying the storage locations of sensitive data. This high level of accuracy underscores the potential risks in shared network slicing environments and highlights the need for robust security measures to safeguard against such advanced side-channel attacks.
One-Shot Collaborative Data Distillation
Aug 05, 2024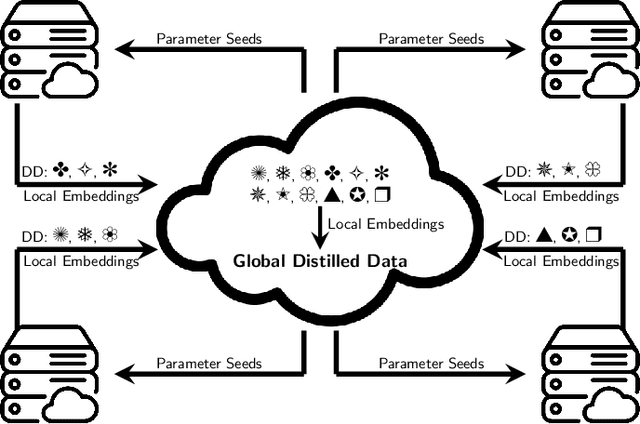
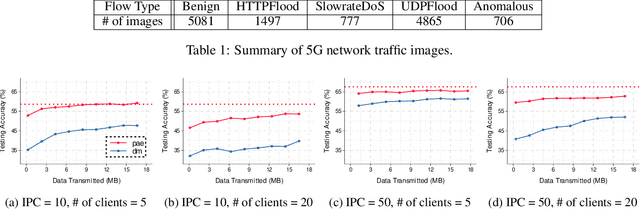

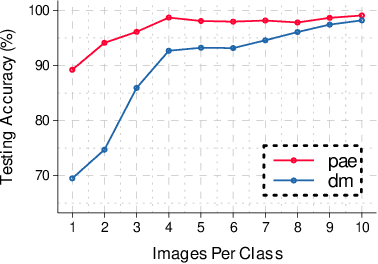
Large machine-learning training datasets can be distilled into small collections of informative synthetic data samples. These synthetic sets support efficient model learning and reduce the communication cost of data sharing. Thus, high-fidelity distilled data can support the efficient deployment of machine learning applications in distributed network environments. A naive way to construct a synthetic set in a distributed environment is to allow each client to perform local data distillation and to merge local distillations at a central server. However, the quality of the resulting set is impaired by heterogeneity in the distributions of the local data held by clients. To overcome this challenge, we introduce the first collaborative data distillation technique, called CollabDM, which captures the global distribution of the data and requires only a single round of communication between client and server. Our method outperforms the state-of-the-art one-shot learning method on skewed data in distributed learning environments. We also show the promising practical benefits of our method when applied to attack detection in 5G networks.
ST-DPGAN: A Privacy-preserving Framework for Spatiotemporal Data Generation
Jun 04, 2024



Spatiotemporal data is prevalent in a wide range of edge devices, such as those used in personal communication and financial transactions. Recent advancements have sparked a growing interest in integrating spatiotemporal analysis with large-scale language models. However, spatiotemporal data often contains sensitive information, making it unsuitable for open third-party access. To address this challenge, we propose a Graph-GAN-based model for generating privacy-protected spatiotemporal data. Our approach incorporates spatial and temporal attention blocks in the discriminator and a spatiotemporal deconvolution structure in the generator. These enhancements enable efficient training under Gaussian noise to achieve differential privacy. Extensive experiments conducted on three real-world spatiotemporal datasets validate the efficacy of our model. Our method provides a privacy guarantee while maintaining the data utility. The prediction model trained on our generated data maintains a competitive performance compared to the model trained on the original data.
Entropy Causal Graphs for Multivariate Time Series Anomaly Detection
Dec 15, 2023Many multivariate time series anomaly detection frameworks have been proposed and widely applied. However, most of these frameworks do not consider intrinsic relationships between variables in multivariate time series data, thus ignoring the causal relationship among variables and degrading anomaly detection performance. This work proposes a novel framework called CGAD, an entropy Causal Graph for multivariate time series Anomaly Detection. CGAD utilizes transfer entropy to construct graph structures that unveil the underlying causal relationships among time series data. Weighted graph convolutional networks combined with causal convolutions are employed to model both the causal graph structures and the temporal patterns within multivariate time series data. Furthermore, CGAD applies anomaly scoring, leveraging median absolute deviation-based normalization to improve the robustness of the anomaly identification process. Extensive experiments demonstrate that CGAD outperforms state-of-the-art methods on real-world datasets with a 15% average improvement based on three different multivariate time series anomaly detection metrics.
Radio Signal Classification by Adversarially Robust Quantum Machine Learning
Dec 13, 2023Radio signal classification plays a pivotal role in identifying the modulation scheme used in received radio signals, which is essential for demodulation and proper interpretation of the transmitted information. Researchers have underscored the high susceptibility of ML algorithms for radio signal classification to adversarial attacks. Such vulnerability could result in severe consequences, including misinterpretation of critical messages, interception of classified information, or disruption of communication channels. Recent advancements in quantum computing have revolutionized theories and implementations of computation, bringing the unprecedented development of Quantum Machine Learning (QML). It is shown that quantum variational classifiers (QVCs) provide notably enhanced robustness against classical adversarial attacks in image classification. However, no research has yet explored whether QML can similarly mitigate adversarial threats in the context of radio signal classification. This work applies QVCs to radio signal classification and studies their robustness to various adversarial attacks. We also propose the novel application of the approximate amplitude encoding (AAE) technique to encode radio signal data efficiently. Our extensive simulation results present that attacks generated on QVCs transfer well to CNN models, indicating that these adversarial examples can fool neural networks that they are not explicitly designed to attack. However, the converse is not true. QVCs primarily resist the attacks generated on CNNs. Overall, with comprehensive simulations, our results shed new light on the growing field of QML by bridging knowledge gaps in QAML in radio signal classification and uncovering the advantages of applying QML methods in practical applications.