 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Shot Collaborative Data Distillation
Paper and Code
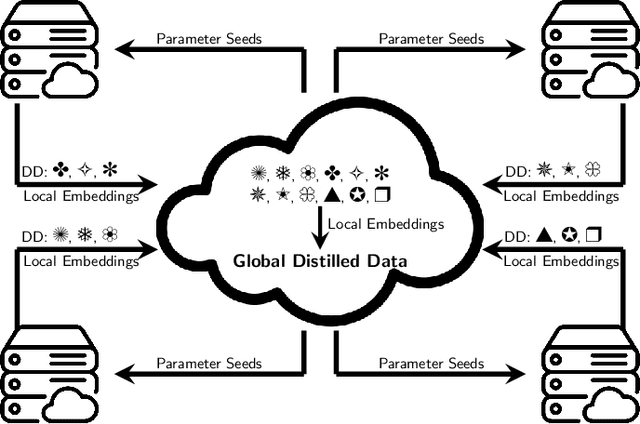
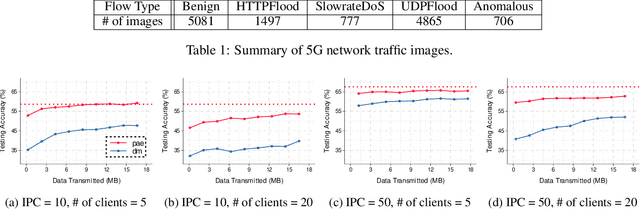

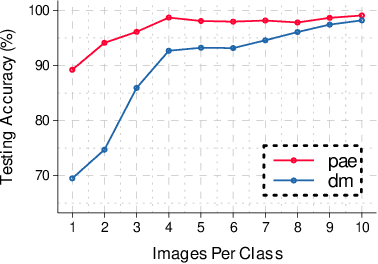
Large machine-learning training datasets can be distilled into small collections of informative synthetic data samples. These synthetic sets support efficient model learning and reduce the communication cost of data sharing. Thus, high-fidelity distilled data can support the efficient deployment of machine learning applications in distributed network environments. A naive way to construct a synthetic set in a distributed environment is to allow each client to perform local data distillation and to merge local distillations at a central server. However, the quality of the resulting set is impaired by heterogeneity in the distributions of the local data held by clients. To overcome this challenge, we introduce the first collaborative data distillation technique, called CollabDM, which captures the global distribution of the data and requires only a single round of communication between client and server. Our method outperforms the state-of-the-art one-shot learning method on skewed data in distributed learning environments. We also show the promising practical benefits of our method when applied to attack detection in 5G networks.