 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttacking Slicing Network via Side-channel Reinforcement Learning Attack
Sep 17, 2024



Network slicing in 5G and the future 6G networks will enable the creation of multiple virtualized networks on a shared physical infrastructure. This innovative approach enables the provision of tailored networks to accommodate specific business types or industry users, thus delivering more customized and efficient services. However, the shared memory and cache in network slicing introduce security vulnerabilities that have yet to be fully addressed. In this paper, we introduce a reinforcement learning-based side-channel cache attack framework specifically designed for network slicing environments. Unlike traditional cache attack methods, our framework leverages reinforcement learning to dynamically identify and exploit cache locations storing sensitive information, such as authentication keys and user registration data. We assume that one slice network is compromised and demonstrate how the attacker can induce another shared slice to send registration requests, thereby estimating the cache locations of critical data. By formulating the cache timing channel attack as a reinforcement learning-driven guessing game between the attack slice and the victim slice, our model efficiently explores possible actions to pinpoint memory blocks containing sensitive information. Experimental results showcase the superiority of our approach, achieving a success rate of approximately 95\% to 98\% in accurately identifying the storage locations of sensitive data. This high level of accuracy underscores the potential risks in shared network slicing environments and highlights the need for robust security measures to safeguard against such advanced side-channel attacks.
One-Shot Collaborative Data Distillation
Aug 05, 2024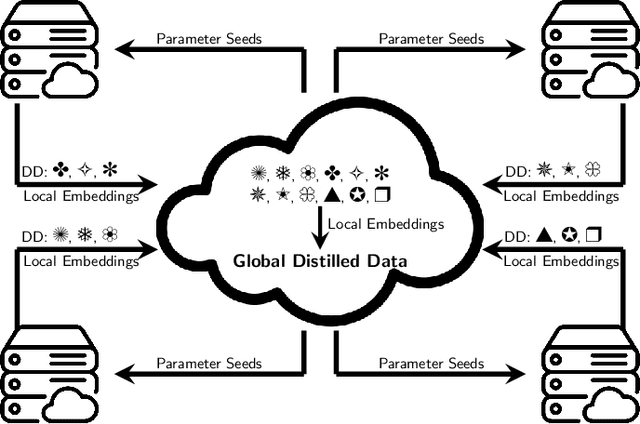
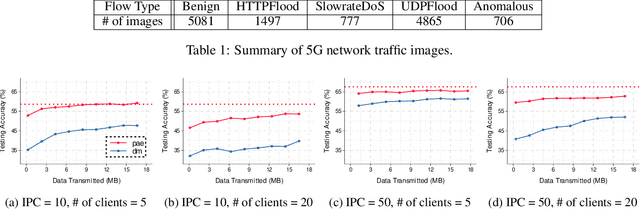

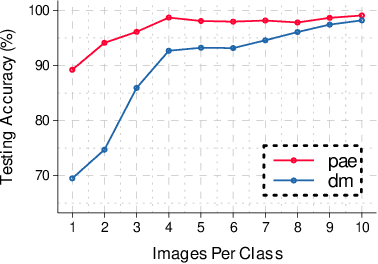
Large machine-learning training datasets can be distilled into small collections of informative synthetic data samples. These synthetic sets support efficient model learning and reduce the communication cost of data sharing. Thus, high-fidelity distilled data can support the efficient deployment of machine learning applications in distributed network environments. A naive way to construct a synthetic set in a distributed environment is to allow each client to perform local data distillation and to merge local distillations at a central server. However, the quality of the resulting set is impaired by heterogeneity in the distributions of the local data held by clients. To overcome this challenge, we introduce the first collaborative data distillation technique, called CollabDM, which captures the global distribution of the data and requires only a single round of communication between client and server. Our method outperforms the state-of-the-art one-shot learning method on skewed data in distributed learning environments. We also show the promising practical benefits of our method when applied to attack detection in 5G networks.