 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempoNet: Learning Realistic Communication and Timing Patterns for Network Traffic Simulation
Jan 22, 2026Realistic network traffic simulation is critical for evaluating intrusion detection systems, stress-testing network protocols, and constructing high-fidelity environments for cybersecurity training. While attack traffic can often be layered into training environments using red-teaming or replay methods, generating authentic benign background traffic remains a core challenge -- particularly in simulating the complex temporal and communication dynamics of real-world networks. This paper introduces TempoNet, a novel generative model that combines multi-task learning with multi-mark temporal point processes to jointly model inter-arrival times and all packet- and flow-header fields. TempoNet captures fine-grained timing patterns and higher-order correlations such as host-pair behavior and seasonal trends, addressing key limitations of GAN-, LLM-, and Bayesian-based methods that fail to reproduce structured temporal variation. TempoNet produces temporally consistent, high-fidelity traces, validated on real-world datasets. Furthermore, we show that intrusion detection models trained on TempoNet-generated background traffic perform comparably to those trained on real data, validating its utility for real-world security applications.
AdaDoS: Adaptive DoS Attack via Deep Adversarial Reinforcement Learning in SDN
Oct 23, 2025Existing defence mechanisms have demonstrated significant effectiveness in mitigating rule-based Denial-of-Service (DoS) attacks, leveraging predefined signatures and static heuristics to identify and block malicious traffic. However, the emergence of AI-driven techniques presents new challenges to SDN security, potentially compromising the efficacy of existing defence mechanisms. In this paper, we introduce~AdaDoS, an adaptive attack model that disrupt network operations while evading detection by existing DoS-based detectors through adversarial reinforcement learning (RL). Specifically, AdaDoS models the problem as a competitive game between an attacker, whose goal is to obstruct network traffic without being detected, and a detector, which aims to identify malicious traffic. AdaDoS can solve this game by dynamically adjusting its attack strategy based on feedback from the SDN and the detector. Additionally, recognising that attackers typically have less information than defenders, AdaDoS formulates the DoS-like attack as a partially observed Markov decision process (POMDP), with the attacker having access only to delay information between attacker and victim nodes. We address this challenge with a novel reciprocal learning module, where the student agent, with limited observations, enhances its performance by learning from the teacher agent, who has full observational capabilities in the SDN environment. AdaDoS represents the first application of RL to develop DoS-like attack sequences, capable of adaptively evading both machine learning-based and rule-based DoS-like attack detectors.
A Qubit-Efficient Hybrid Quantum Encoding Mechanism for Quantum Machine Learning
Jun 24, 2025Efficiently embedding high-dimensional datasets onto noisy and low-qubit quantum systems is a significant barrier to practical Quantum Machine Learning (QML). Approaches such as quantum autoencoders can be constrained by current hardware capabilities and may exhibit vulnerabilities to reconstruction attacks due to their invertibility. We propose Quantum Principal Geodesic Analysis (qPGA), a novel, non-invertible method for dimensionality reduction and qubit-efficient encoding. Executed classically, qPGA leverages Riemannian geometry to project data onto the unit Hilbert sphere, generating outputs inherently suitable for quantum amplitude encoding. This technique preserves the neighborhood structure of high-dimensional datasets within a compact latent space, significantly reducing qubit requirements for amplitude encoding. We derive theoretical bounds quantifying qubit requirements for effective encoding onto noisy systems. Empirical results on MNIST, Fashion-MNIST, and CIFAR-10 show that qPGA preserves local structure more effectively than both quantum and hybrid autoencoders. Additionally, we demonstrate that qPGA enhances resistance to reconstruction attacks due to its non-invertible nature. In downstream QML classification tasks, qPGA can achieve over 99% accuracy and F1-score on MNIST and Fashion-MNIST, outperforming quantum-dependent baselines. Initial tests on real hardware and noisy simulators confirm its potential for noise-resilient performance, offering a scalable solution for advancing QML applications.
A Unified Framework for Human AI Collaboration in Security Operations Centers with Trusted Autonomy
May 29, 2025This article presents a structured framework for Human-AI collaboration in Security Operations Centers (SOCs), integrating AI autonomy, trust calibration, and Human-in-the-loop decision making. Existing frameworks in SOCs often focus narrowly on automation, lacking systematic structures to manage human oversight, trust calibration, and scalable autonomy with AI. Many assume static or binary autonomy settings, failing to account for the varied complexity, criticality, and risk across SOC tasks considering Humans and AI collaboration. To address these limitations, we propose a novel autonomy tiered framework grounded in five levels of AI autonomy from manual to fully autonomous, mapped to Human-in-the-Loop (HITL) roles and task-specific trust thresholds. This enables adaptive and explainable AI integration across core SOC functions, including monitoring, protection, threat detection, alert triage, and incident response. The proposed framework differentiates itself from previous research by creating formal connections between autonomy, trust, and HITL across various SOC levels, which allows for adaptive task distribution according to operational complexity and associated risks. The framework is exemplified through a simulated cyber range that features the cybersecurity AI-Avatar, a fine-tuned LLM-based SOC assistant. The AI-Avatar case study illustrates human-AI collaboration for SOC tasks, reducing alert fatigue, enhancing response coordination, and strategically calibrating trust. This research systematically presents both the theoretical and practical aspects and feasibility of designing next-generation cognitive SOCs that leverage AI not to replace but to enhance human decision-making.
RLSA-PFL: Robust Lightweight Secure Aggregation with Model Inconsistency Detection in Privacy-Preserving Federated Learning
Feb 13, 2025Federated Learning (FL) allows users to collaboratively train a global machine learning model by sharing local model only, without exposing their private data to a central server. This distributed learning is particularly appealing in scenarios where data privacy is crucial, and it has garnered substantial attention from both industry and academia. However, studies have revealed privacy vulnerabilities in FL, where adversaries can potentially infer sensitive information from the shared model parameters. In this paper, we present an efficient masking-based secure aggregation scheme utilizing lightweight cryptographic primitives to mitigate privacy risks. Our scheme offers several advantages over existing methods. First, it requires only a single setup phase for the entire FL training session, significantly reducing communication overhead. Second, it minimizes user-side overhead by eliminating the need for user-to-user interactions, utilizing an intermediate server layer and a lightweight key negotiation method. Third, the scheme is highly resilient to user dropouts, and the users can join at any FL round. Fourth, it can detect and defend against malicious server activities, including recently discovered model inconsistency attacks. Finally, our scheme ensures security in both semi-honest and malicious settings. We provide security analysis to formally prove the robustness of our approach. Furthermore, we implemented an end-to-end prototype of our scheme. We conducted comprehensive experiments and comparisons, which show that it outperforms existing solutions in terms of communication and computation overhead, functionality, and security.
CAMP in the Odyssey: Provably Robust Reinforcement Learning with Certified Radius Maximization
Jan 29, 2025



Deep reinforcement learning (DRL) has gained widespread adoption in control and decision-making tasks due to its strong performance in dynamic environments. However, DRL agents are vulnerable to noisy observations and adversarial attacks, and concerns about the adversarial robustness of DRL systems have emerged. Recent efforts have focused on addressing these robustness issues by establishing rigorous theoretical guarantees for the returns achieved by DRL agents in adversarial settings. Among these approaches, policy smoothing has proven to be an effective and scalable method for certifying the robustness of DRL agents. Nevertheless, existing certifiably robust DRL relies on policies trained with simple Gaussian augmentations, resulting in a suboptimal trade-off between certified robustness and certified return. To address this issue, we introduce a novel paradigm dubbed \texttt{C}ertified-r\texttt{A}dius-\texttt{M}aximizing \texttt{P}olicy (\texttt{CAMP}) training. \texttt{CAMP} is designed to enhance DRL policies, achieving better utility without compromising provable robustness. By leveraging the insight that the global certified radius can be derived from local certified radii based on training-time statistics, \texttt{CAMP} formulates a surrogate loss related to the local certified radius and optimizes the policy guided by this surrogate loss. We also introduce \textit{policy imitation} as a novel technique to stabilize \texttt{CAMP} training. Experimental results demonstrate that \texttt{CAMP} significantly improves the robustness-return trade-off across various tasks. Based on the results, \texttt{CAMP} can achieve up to twice the certified expected return compared to that of baselines. Our code is available at https://github.com/NeuralSec/camp-robust-rl.
AI-Compass: A Comprehensive and Effective Multi-module Testing Tool for AI Systems
Nov 09, 2024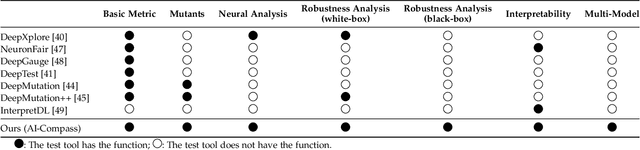

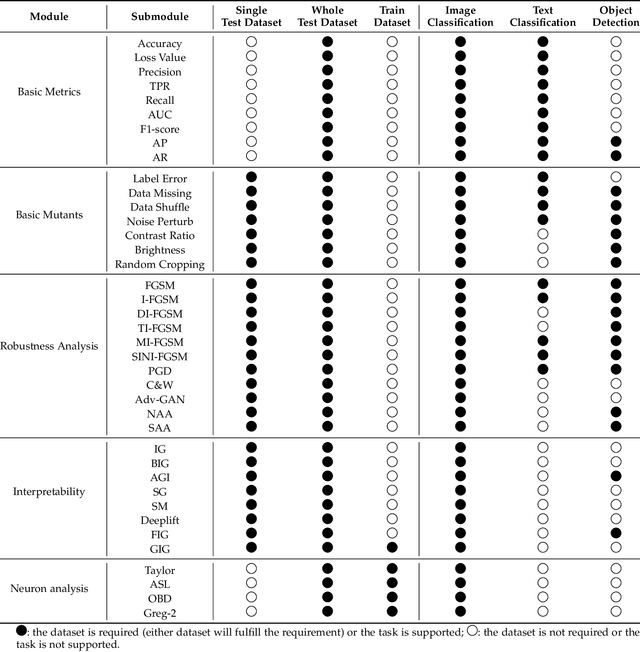

AI systems, in particular with deep learning techniques, have demonstrated superior performance for various real-world applications. Given the need for tailored optimization in specific scenarios, as well as the concerns related to the exploits of subsurface vulnerabilities, a more comprehensive and in-depth testing AI system becomes a pivotal topic. We have seen the emergence of testing tools in real-world applications that aim to expand testing capabilities. However, they often concentrate on ad-hoc tasks, rendering them unsuitable for simultaneously testing multiple aspects or components. Furthermore, trustworthiness issues arising from adversarial attacks and the challenge of interpreting deep learning models pose new challenges for developing more comprehensive and in-depth AI system testing tools. In this study, we design and implement a testing tool, \tool, to comprehensively and effectively evaluate AI systems. The tool extensively assesses multiple measurements towards adversarial robustness, model interpretability, and performs neuron analysis. The feasibility of the proposed testing tool is thoroughly validated across various modalities, including image classification, object detection, and text classification. Extensive experiments demonstrate that \tool is the state-of-the-art tool for a comprehensive assessment of the robustness and trustworthiness of AI systems. Our research sheds light on a general solution for AI systems testing landscape.
Robustness and Security Enhancement of Radio Frequency Fingerprint Identification in Time-Varying Channels
Oct 10, 2024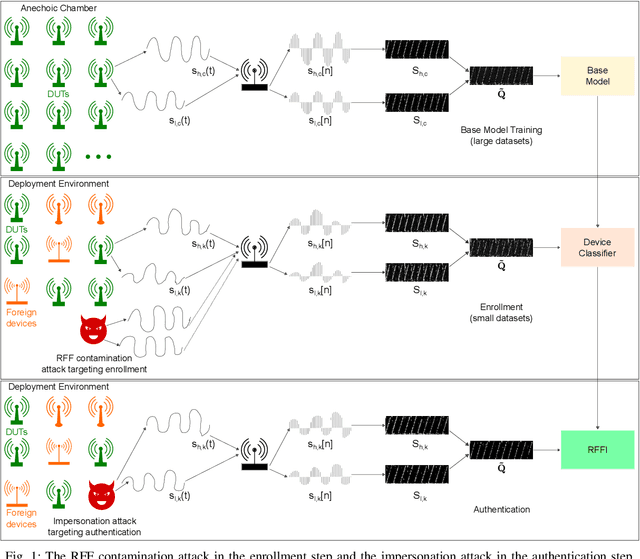



Radio frequency fingerprint identification (RFFI) is becoming increasingly popular, especially in applications with constrained power, such as the Internet of Things (IoT). Due to subtle manufacturing variations, wireless devices have unique radio frequency fingerprints (RFFs). These RFFs can be used with pattern recognition algorithms to classify wireless devices. However, Implementing reliable RFFI in time-varying channels is challenging because RFFs are often distorted by channel effects, reducing the classification accuracy. This paper introduces a new channel-robust RFF, and leverages transfer learning to enhance RFFI in the time-varying channels. Experimental results show that the proposed RFFI system achieved an average classification accuracy improvement of 33.3 % in indoor environments and 34.5 % in outdoor environments. This paper also analyzes the security of the proposed RFFI system to address the security flaw in formalized impersonation attacks. Since RFF collection is being carried out in uncontrolled deployment environments, RFFI systems can be targeted with false RFFs sent by rogue devices. The resulting classifiers may classify the rogue devices as legitimate, effectively replacing their true identities. To defend against impersonation attacks, a novel keyless countermeasure is proposed, which exploits the intrinsic output of the softmax function after classifier training without sacrificing the lightweight nature of RFFI. Experimental results demonstrate an average increase of 0.3 in the area under the receiver operating characteristic curve (AUC), with a 40.0 % improvement in attack detection rate in indoor and outdoor environments.
A Hybrid Quantum Neural Network for Split Learning
Sep 25, 2024



Quantum Machine Learning (QML) is an emerging field of research with potential applications to distributed collaborative learning, such as Split Learning (SL). SL allows resource-constrained clients to collaboratively train ML models with a server, reduce their computational overhead, and enable data privacy by avoiding raw data sharing. Although QML with SL has been studied, the problem remains open in resource-constrained environments where clients lack quantum computing capabilities. Additionally, data privacy leakage between client and server in SL poses risks of reconstruction attacks on the server side. To address these issues, we propose Hybrid Quantum Split Learning (HQSL), an application of Hybrid QML in SL. HQSL enables classical clients to train models with a hybrid quantum server and curtails reconstruction attacks. In addition, we introduce a novel qubit-efficient data-loading technique for designing a quantum layer in HQSL, minimizing both the number of qubits and circuit depth. Experiments on five datasets demonstrate HQSL's feasibility and ability to enhance classification performance compared to its classical models. Notably, HQSL achieves mean improvements of over 3% in both accuracy and F1-score for the Fashion-MNIST dataset, and over 1.5% in both metrics for the Speech Commands dataset. We expand these studies to include up to 100 clients, confirming HQSL's scalability. Moreover, we introduce a noise-based defense mechanism to tackle reconstruction attacks on the server side. Overall, HQSL enables classical clients to collaboratively train their models with a hybrid quantum server, leveraging quantum advantages while improving model performance and security against data privacy leakage-related reconstruction attacks.
Attacking Slicing Network via Side-channel Reinforcement Learning Attack
Sep 17, 2024



Network slicing in 5G and the future 6G networks will enable the creation of multiple virtualized networks on a shared physical infrastructure. This innovative approach enables the provision of tailored networks to accommodate specific business types or industry users, thus delivering more customized and efficient services. However, the shared memory and cache in network slicing introduce security vulnerabilities that have yet to be fully addressed. In this paper, we introduce a reinforcement learning-based side-channel cache attack framework specifically designed for network slicing environments. Unlike traditional cache attack methods, our framework leverages reinforcement learning to dynamically identify and exploit cache locations storing sensitive information, such as authentication keys and user registration data. We assume that one slice network is compromised and demonstrate how the attacker can induce another shared slice to send registration requests, thereby estimating the cache locations of critical data. By formulating the cache timing channel attack as a reinforcement learning-driven guessing game between the attack slice and the victim slice, our model efficiently explores possible actions to pinpoint memory blocks containing sensitive information. Experimental results showcase the superiority of our approach, achieving a success rate of approximately 95\% to 98\% in accurately identifying the storage locations of sensitive data. This high level of accuracy underscores the potential risks in shared network slicing environments and highlights the need for robust security measures to safeguard against such advanced side-channel attacks.