 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucination-Resistant Security Planning with a Large Language Model
Feb 05, 2026Large language models (LLMs) are promising tools for supporting security management tasks, such as incident response planning. However, their unreliability and tendency to hallucinate remain significant challenges. In this paper, we address these challenges by introducing a principled framework for using an LLM as decision support in security management. Our framework integrates the LLM in an iterative loop where it generates candidate actions that are checked for consistency with system constraints and lookahead predictions. When consistency is low, we abstain from the generated actions and instead collect external feedback, e.g., by evaluating actions in a digital twin. This feedback is then used to refine the candidate actions through in-context learning (ICL). We prove that this design allows to control the hallucination risk by tuning the consistency threshold. Moreover, we establish a bound on the regret of ICL under certain assumptions. To evaluate our framework, we apply it to an incident response use case where the goal is to generate a response and recovery plan based on system logs. Experiments on four public datasets show that our framework reduces recovery times by up to 30% compared to frontier LLMs.
Incident Response Planning Using a Lightweight Large Language Model with Reduced Hallucination
Aug 07, 2025Timely and effective incident response is key to managing the growing frequency of cyberattacks. However, identifying the right response actions for complex systems is a major technical challenge. A promising approach to mitigate this challenge is to use the security knowledge embedded in large language models (LLMs) to assist security operators during incident handling. Recent research has demonstrated the potential of this approach, but current methods are mainly based on prompt engineering of frontier LLMs, which is costly and prone to hallucinations. We address these limitations by presenting a novel way to use an LLM for incident response planning with reduced hallucination. Our method includes three steps: fine-tuning, information retrieval, and lookahead planning. We prove that our method generates response plans with a bounded probability of hallucination and that this probability can be made arbitrarily small at the expense of increased planning time under certain assumptions. Moreover, we show that our method is lightweight and can run on commodity hardware. We evaluate our method on logs from incidents reported in the literature. The experimental results show that our method a) achieves up to 22% shorter recovery times than frontier LLMs and b) generalizes to a broad range of incident types and response actions.
A Qubit-Efficient Hybrid Quantum Encoding Mechanism for Quantum Machine Learning
Jun 24, 2025Efficiently embedding high-dimensional datasets onto noisy and low-qubit quantum systems is a significant barrier to practical Quantum Machine Learning (QML). Approaches such as quantum autoencoders can be constrained by current hardware capabilities and may exhibit vulnerabilities to reconstruction attacks due to their invertibility. We propose Quantum Principal Geodesic Analysis (qPGA), a novel, non-invertible method for dimensionality reduction and qubit-efficient encoding. Executed classically, qPGA leverages Riemannian geometry to project data onto the unit Hilbert sphere, generating outputs inherently suitable for quantum amplitude encoding. This technique preserves the neighborhood structure of high-dimensional datasets within a compact latent space, significantly reducing qubit requirements for amplitude encoding. We derive theoretical bounds quantifying qubit requirements for effective encoding onto noisy systems. Empirical results on MNIST, Fashion-MNIST, and CIFAR-10 show that qPGA preserves local structure more effectively than both quantum and hybrid autoencoders. Additionally, we demonstrate that qPGA enhances resistance to reconstruction attacks due to its non-invertible nature. In downstream QML classification tasks, qPGA can achieve over 99% accuracy and F1-score on MNIST and Fashion-MNIST, outperforming quantum-dependent baselines. Initial tests on real hardware and noisy simulators confirm its potential for noise-resilient performance, offering a scalable solution for advancing QML applications.
Computable Model-Independent Bounds for Adversarial Quantum Machine Learning
Nov 11, 2024



By leveraging the principles of quantum mechanics, QML opens doors to novel approaches in machine learning and offers potential speedup. However, machine learning models are well-documented to be vulnerable to malicious manipulations, and this susceptibility extends to the models of QML. This situation necessitates a thorough understanding of QML's resilience against adversarial attacks, particularly in an era where quantum computing capabilities are expanding. In this regard, this paper examines model-independent bounds on adversarial performance for QML. To the best of our knowledge, we introduce the first computation of an approximate lower bound for adversarial error when evaluating model resilience against sophisticated quantum-based adversarial attacks. Experimental results are compared to the computed bound, demonstrating the potential of QML models to achieve high robustness. In the best case, the experimental error is only 10% above the estimated bound, offering evidence of the inherent robustness of quantum models. This work not only advances our theoretical understanding of quantum model resilience but also provides a precise reference bound for the future development of robust QML algorithms.
A Hybrid Quantum Neural Network for Split Learning
Sep 25, 2024



Quantum Machine Learning (QML) is an emerging field of research with potential applications to distributed collaborative learning, such as Split Learning (SL). SL allows resource-constrained clients to collaboratively train ML models with a server, reduce their computational overhead, and enable data privacy by avoiding raw data sharing. Although QML with SL has been studied, the problem remains open in resource-constrained environments where clients lack quantum computing capabilities. Additionally, data privacy leakage between client and server in SL poses risks of reconstruction attacks on the server side. To address these issues, we propose Hybrid Quantum Split Learning (HQSL), an application of Hybrid QML in SL. HQSL enables classical clients to train models with a hybrid quantum server and curtails reconstruction attacks. In addition, we introduce a novel qubit-efficient data-loading technique for designing a quantum layer in HQSL, minimizing both the number of qubits and circuit depth. Experiments on five datasets demonstrate HQSL's feasibility and ability to enhance classification performance compared to its classical models. Notably, HQSL achieves mean improvements of over 3% in both accuracy and F1-score for the Fashion-MNIST dataset, and over 1.5% in both metrics for the Speech Commands dataset. We expand these studies to include up to 100 clients, confirming HQSL's scalability. Moreover, we introduce a noise-based defense mechanism to tackle reconstruction attacks on the server side. Overall, HQSL enables classical clients to collaboratively train their models with a hybrid quantum server, leveraging quantum advantages while improving model performance and security against data privacy leakage-related reconstruction attacks.
Lightweight Conceptual Dictionary Learning for Text Classification Using Information Compression
Apr 28, 2024



We propose a novel, lightweight supervised dictionary learning framework for text classification based on data compression and representation. This two-phase algorithm initially employs the Lempel-Ziv-Welch (LZW) algorithm to construct a dictionary from text datasets, focusing on the conceptual significance of dictionary elements. Subsequently, dictionaries are refined considering label data, optimizing dictionary atoms to enhance discriminative power based on mutual information and class distribution. This process generates discriminative numerical representations, facilitating the training of simple classifiers such as SVMs and neural networks. We evaluate our algorithm's information-theoretic performance using information bottleneck principles and introduce the information plane area rank (IPAR) as a novel metric to quantify the information-theoretic performance. Tested on six benchmark text datasets, our algorithm competes closely with top models, especially in limited-vocabulary contexts, using significantly fewer parameters. \review{Our algorithm closely matches top-performing models, deviating by only ~2\% on limited-vocabulary datasets, using just 10\% of their parameters. However, it falls short on diverse-vocabulary datasets, likely due to the LZW algorithm's constraints with low-repetition data. This contrast highlights its efficiency and limitations across different dataset types.
An Interpretable Low-complexity Model for Wireless Channel Estimation
Feb 12, 2024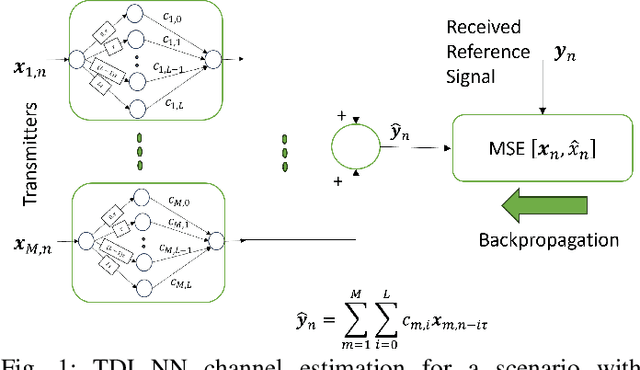
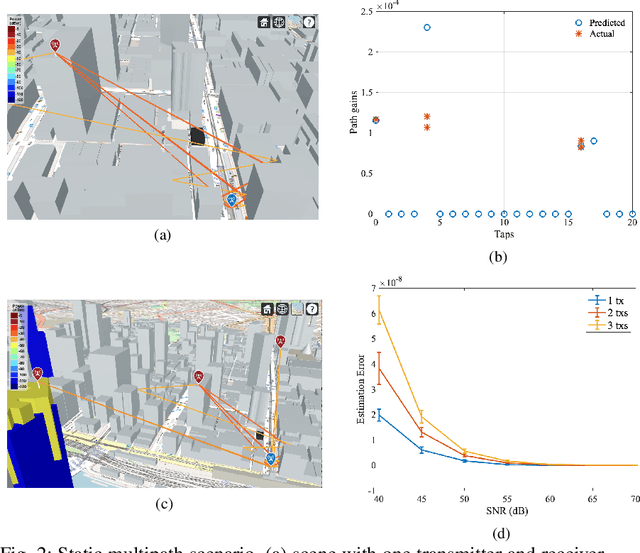
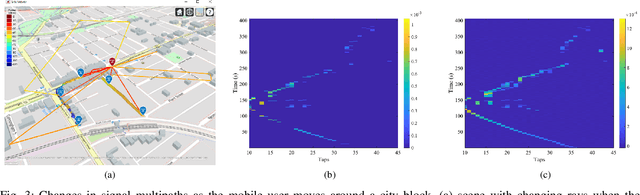
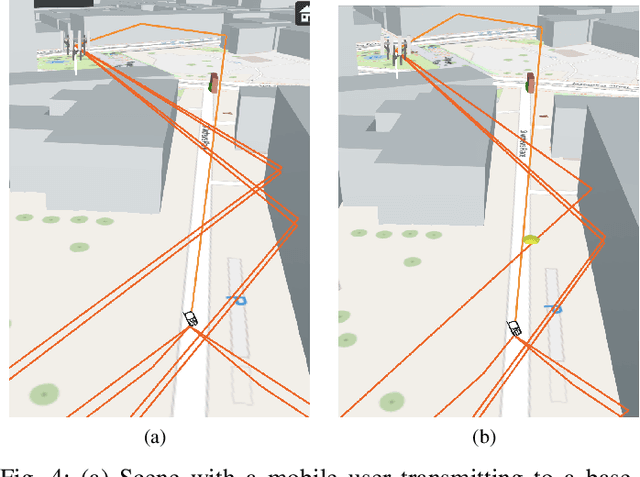
With the advent of machine learning, there has been renewed interest in the problem of wireless channel estimation. This paper presents a novel low-complexity wireless channel estimation scheme based on a tapped delay line (TDL) model of wireless signal propagation, where a data-driven machine learning approach is used to estimate the path delays and gains. Advantages of this approach include low computation time and training data requirements, as well as interpretability since the estimated model parameters and their variance provide comprehensive representation of the dynamic wireless multipath environment. We evaluate this model's performance using Matlab's ray-tracing tool under static and dynamic conditions for increased realism instead of the standard evaluation approaches using statistical channel models. Our results show that our TDL-based model can accurately estimate the path delays and associated gains for a broad-range of locations and operating conditions. Root-mean-square estimation error remained less than $10^{-4}$, or $-40$dB, for SNR $\geq 30$dB in all of our experiments. The key motivation for the novel channel estimation model is to gain environment awareness, i.e., detecting changes in path delays and gains related to interesting objects and events in the field. The channel state with multipath delays and gains is a detailed measure to sense the field than the single-tap channel state indicator calculated in current OFDM systems.
OIL-AD: An Anomaly Detection Framework for Sequential Decision Sequences
Feb 07, 2024Anomaly detection in decision-making sequences is a challenging problem due to the complexity of normality representation learning and the sequential nature of the task. Most existing methods based on Reinforcement Learning (RL) are difficult to implement in the real world due to unrealistic assumptions, such as having access to environment dynamics, reward signals, and online interactions with the environment. To address these limitations, we propose an unsupervised method named Offline Imitation Learning based Anomaly Detection (OIL-AD), which detects anomalies in decision-making sequences using two extracted behaviour features: action optimality and sequential association. Our offline learning model is an adaptation of behavioural cloning with a transformer policy network, where we modify the training process to learn a Q function and a state value function from normal trajectories. We propose that the Q function and the state value function can provide sufficient information about agents' behavioural data, from which we derive two features for anomaly detection. The intuition behind our method is that the action optimality feature derived from the Q function can differentiate the optimal action from others at each local state, and the sequential association feature derived from the state value function has the potential to maintain the temporal correlations between decisions (state-action pairs). Our experiments show that OIL-AD can achieve outstanding online anomaly detection performance with up to 34.8% improvement in F1 score over comparable baselines.
Failure-tolerant Distributed Learning for Anomaly Detection in Wireless Networks
Mar 23, 2023



The analysis of distributed techniques is often focused upon their efficiency, without considering their robustness (or lack thereof). Such a consideration is particularly important when devices or central servers can fail, which can potentially cripple distributed systems. When such failures arise in wireless communications networks, important services that they use/provide (like anomaly detection) can be left inoperable and can result in a cascade of security problems. In this paper, we present a novel method to address these risks by combining both flat- and star-topologies, combining the performance and reliability benefits of both. We refer to this method as "Tol-FL", due to its increased failure-tolerance as compared to the technique of Federated Learning. Our approach both limits device failure risks while outperforming prior methods by up to 8% in terms of anomaly detection AUROC in a range of realistic settings that consider client as well as server failure, all while reducing communication costs. This performance demonstrates that Tol-FL is a highly suitable method for distributed model training for anomaly detection, especially in the domain of wireless networks.
A Game-Theoretic Approach for AI-based Botnet Attack Defence
Dec 04, 2021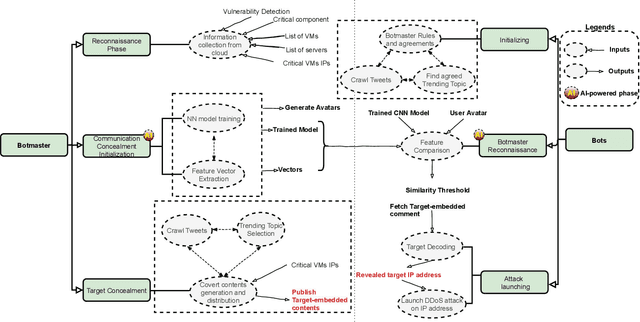
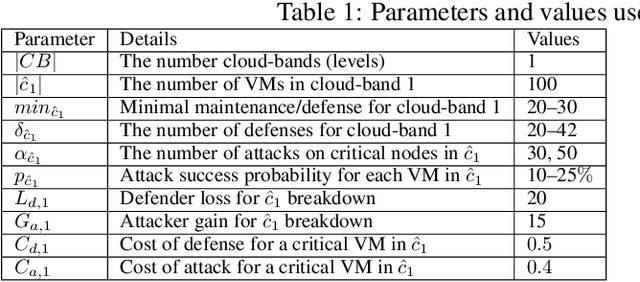

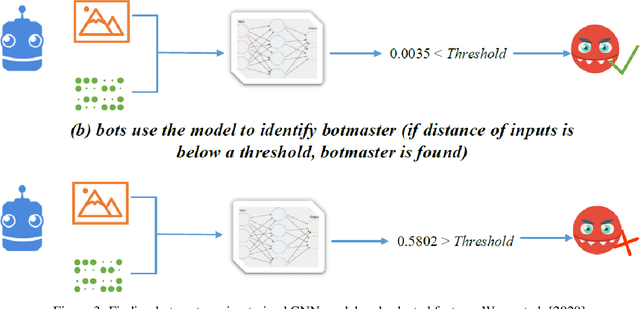
The new generation of botnets leverages Artificial Intelligent (AI) techniques to conceal the identity of botmasters and the attack intention to avoid detection. Unfortunately, there has not been an existing assessment tool capable of evaluating the effectiveness of existing defense strategies against this kind of AI-based botnet attack. In this paper, we propose a sequential game theory model that is capable to analyse the details of the potential strategies botnet attackers and defenders could use to reach Nash Equilibrium (NE). The utility function is computed under the assumption when the attacker launches the maximum number of DDoS attacks with the minimum attack cost while the defender utilises the maximum number of defense strategies with the minimum defense cost. We conduct a numerical analysis based on a various number of defense strategies involved on different (simulated) cloud-band sizes in relation to different attack success rate values. Our experimental results confirm that the success of defense highly depends on the number of defense strategies used according to careful evaluation of attack rates.