 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-aware Adversarial Fine-tuning for CLIP
Feb 12, 2026Recent studies have shown that CLIP model's adversarial robustness in zero-shot classification tasks can be enhanced by adversarially fine-tuning its image encoder with adversarial examples (AEs), which are generated by minimizing the cosine similarity between images and a hand-crafted template (e.g., ''A photo of a {label}''). However, it has been shown that the cosine similarity between a single image and a single hand-crafted template is insufficient to measure the similarity for image-text pairs. Building on this, in this paper, we find that the AEs generated using cosine similarity may fail to fool CLIP when the similarity metric is replaced with semantically enriched alternatives, making the image encoder fine-tuned with these AEs less robust. To overcome this issue, we first propose a semantic-ensemble attack to generate semantic-aware AEs by minimizing the average similarity between the original image and an ensemble of refined textual descriptions. These descriptions are initially generated by a foundation model to capture core semantic features beyond hand-crafted templates and are then refined to reduce hallucinations. To this end, we propose Semantic-aware Adversarial Fine-Tuning (SAFT), which fine-tunes CLIP's image encoder with semantic-aware AEs. Extensive experiments show that SAFT outperforms current methods, achieving substantial improvements in zero-shot adversarial robustness across 16 datasets. Our code is available at: https://github.com/tmlr-group/SAFT.
Position: Certified Robustness Does Not (Yet) Imply Model Security
Jun 16, 2025While certified robustness is widely promoted as a solution to adversarial examples in Artificial Intelligence systems, significant challenges remain before these techniques can be meaningfully deployed in real-world applications. We identify critical gaps in current research, including the paradox of detection without distinction, the lack of clear criteria for practitioners to evaluate certification schemes, and the potential security risks arising from users' expectations surrounding ``guaranteed" robustness claims. This position paper is a call to arms for the certification research community, proposing concrete steps to address these fundamental challenges and advance the field toward practical applicability.
Intrinsic and Extrinsic Factor Disentanglement for Recommendation in Various Context Scenarios
Mar 05, 2025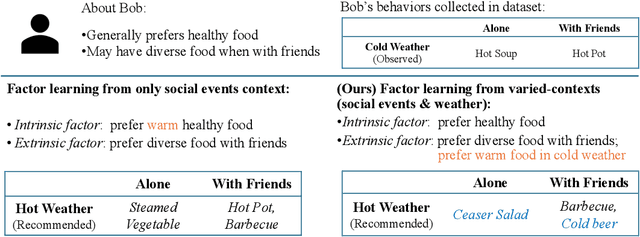
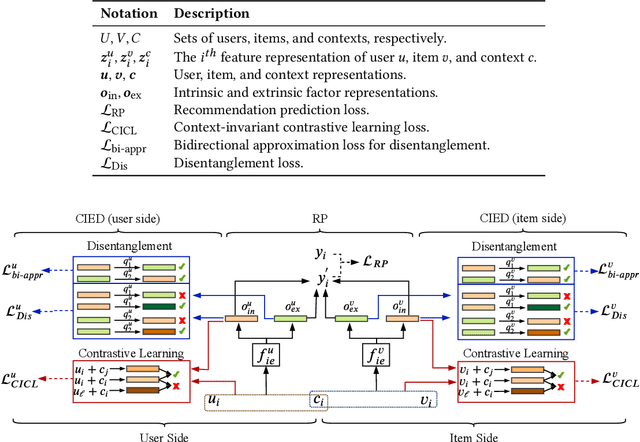
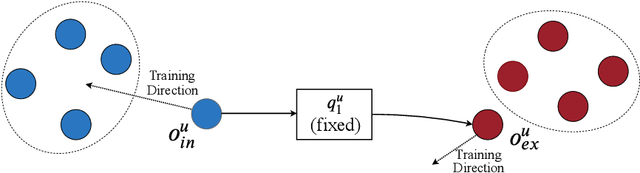
In recommender systems, the patterns of user behaviors (e.g., purchase, click) may vary greatly in different contexts (e.g., time and location). This is because user behavior is jointly determined by two types of factors: intrinsic factors, which reflect consistent user preference, and extrinsic factors, which reflect external incentives that may vary in different contexts. Differentiating between intrinsic and extrinsic factors helps learn user behaviors better. However, existing studies have only considered differentiating them from a single, pre-defined context (e.g., time or location), ignoring the fact that a user's extrinsic factors may be influenced by the interplay of various contexts at the same time. In this paper, we propose the Intrinsic-Extrinsic Disentangled Recommendation (IEDR) model, a generic framework that differentiates intrinsic from extrinsic factors considering various contexts simultaneously, enabling more accurate differentiation of factors and hence the improvement of recommendation accuracy. IEDR contains a context-invariant contrastive learning component to capture intrinsic factors, and a disentanglement component to extract extrinsic factors under the interplay of various contexts. The two components work together to achieve effective factor learning. Extensive experiments on real-world datasets demonstrate IEDR's effectiveness in learning disentangled factors and significantly improving recommendation accuracy by up to 4% in NDCG.
Be Persistent: Towards a Unified Solution for Mitigating Shortcuts in Deep Learning
Feb 17, 2024
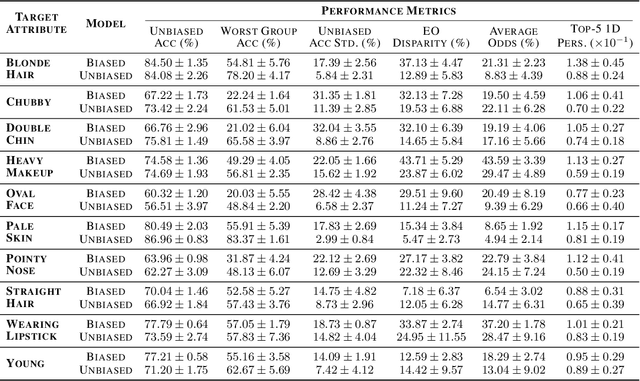
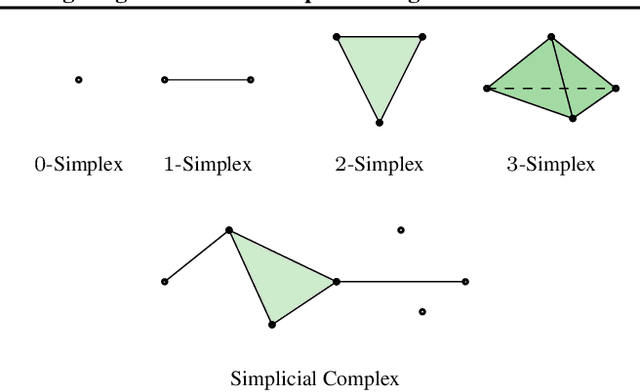
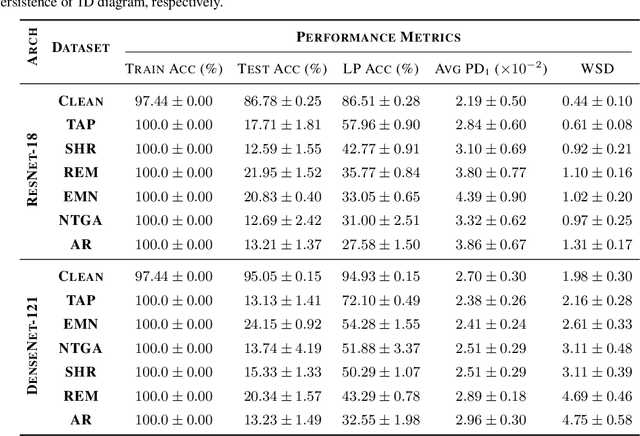
Deep neural networks (DNNs) are vulnerable to shortcut learning: rather than learning the intended task, they tend to draw inconclusive relationships between their inputs and outputs. Shortcut learning is ubiquitous among many failure cases of neural networks, and traces of this phenomenon can be seen in their generalizability issues, domain shift, adversarial vulnerability, and even bias towards majority groups. In this paper, we argue that this commonality in the cause of various DNN issues creates a significant opportunity that should be leveraged to find a unified solution for shortcut learning. To this end, we outline the recent advances in topological data analysis~(TDA), and persistent homology~(PH) in particular, to sketch a unified roadmap for detecting shortcuts in deep learning. We demonstrate our arguments by investigating the topological features of computational graphs in DNNs using two cases of unlearnable examples and bias in decision-making as our test studies. Our analysis of these two failure cases of DNNs reveals that finding a unified solution for shortcut learning in DNNs is not out of reach, and TDA can play a significant role in forming such a framework.
It's Simplex! Disaggregating Measures to Improve Certified Robustness
Sep 20, 2023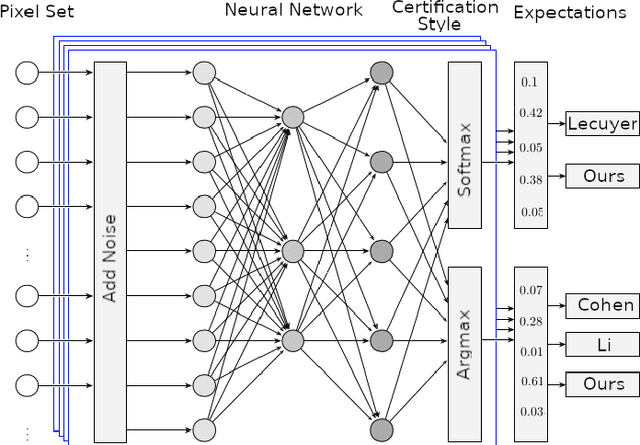
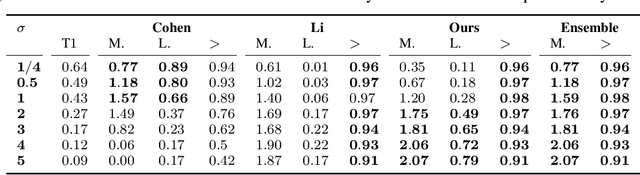
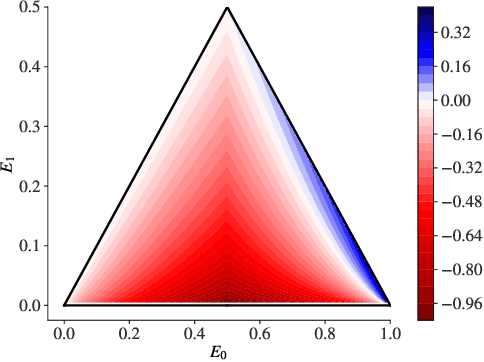
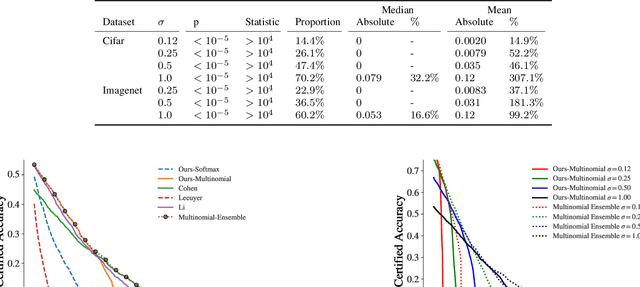
Certified robustness circumvents the fragility of defences against adversarial attacks, by endowing model predictions with guarantees of class invariance for attacks up to a calculated size. While there is value in these certifications, the techniques through which we assess their performance do not present a proper accounting of their strengths and weaknesses, as their analysis has eschewed consideration of performance over individual samples in favour of aggregated measures. By considering the potential output space of certified models, this work presents two distinct approaches to improve the analysis of certification mechanisms, that allow for both dataset-independent and dataset-dependent measures of certification performance. Embracing such a perspective uncovers new certification approaches, which have the potential to more than double the achievable radius of certification, relative to current state-of-the-art. Empirical evaluation verifies that our new approach can certify $9\%$ more samples at noise scale $\sigma = 1$, with greater relative improvements observed as the difficulty of the predictive task increases.
Enhancing the Antidote: Improved Pointwise Certifications against Poisoning Attacks
Aug 15, 2023

Poisoning attacks can disproportionately influence model behaviour by making small changes to the training corpus. While defences against specific poisoning attacks do exist, they in general do not provide any guarantees, leaving them potentially countered by novel attacks. In contrast, by examining worst-case behaviours Certified Defences make it possible to provide guarantees of the robustness of a sample against adversarial attacks modifying a finite number of training samples, known as pointwise certification. We achieve this by exploiting both Differential Privacy and the Sampled Gaussian Mechanism to ensure the invariance of prediction for each testing instance against finite numbers of poisoned examples. In doing so, our model provides guarantees of adversarial robustness that are more than twice as large as those provided by prior certifications.
Towards quantum enhanced adversarial robustness in machine learning
Jun 22, 2023Machine learning algorithms are powerful tools for data driven tasks such as image classification and feature detection, however their vulnerability to adversarial examples - input samples manipulated to fool the algorithm - remains a serious challenge. The integration of machine learning with quantum computing has the potential to yield tools offering not only better accuracy and computational efficiency, but also superior robustness against adversarial attacks. Indeed, recent work has employed quantum mechanical phenomena to defend against adversarial attacks, spurring the rapid development of the field of quantum adversarial machine learning (QAML) and potentially yielding a new source of quantum advantage. Despite promising early results, there remain challenges towards building robust real-world QAML tools. In this review we discuss recent progress in QAML and identify key challenges. We also suggest future research directions which could determine the route to practicality for QAML approaches as quantum computing hardware scales up and noise levels are reduced.
* 10 Pages, 4 Figures
Exploiting Certified Defences to Attack Randomised Smoothing
Feb 09, 2023In guaranteeing that no adversarial examples exist within a bounded region, certification mechanisms play an important role in neural network robustness. Concerningly, this work demonstrates that the certification mechanisms themselves introduce a new, heretofore undiscovered attack surface, that can be exploited by attackers to construct smaller adversarial perturbations. While these attacks exist outside the certification region in no way invalidate certifications, minimising a perturbation's norm significantly increases the level of difficulty associated with attack detection. In comparison to baseline attacks, our new framework yields smaller perturbations more than twice as frequently as any other approach, resulting in an up to $34 \%$ reduction in the median perturbation norm. That this approach also requires $90 \%$ less computational time than approaches like PGD. That these reductions are possible suggests that exploiting this new attack vector would allow attackers to more frequently construct hard to detect adversarial attacks, by exploiting the very systems designed to defend deployed models.
Hybrid Quantum-Classical Generative Adversarial Network for High Resolution Image Generation
Dec 22, 2022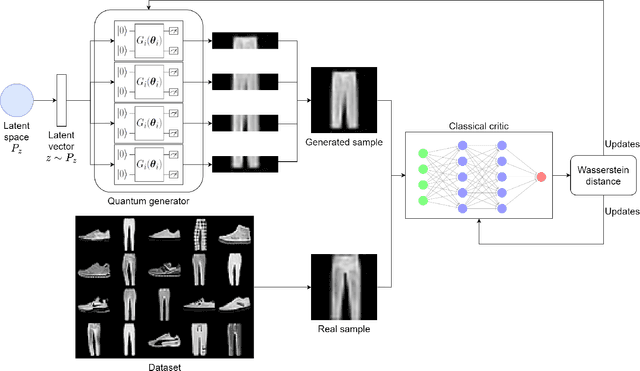
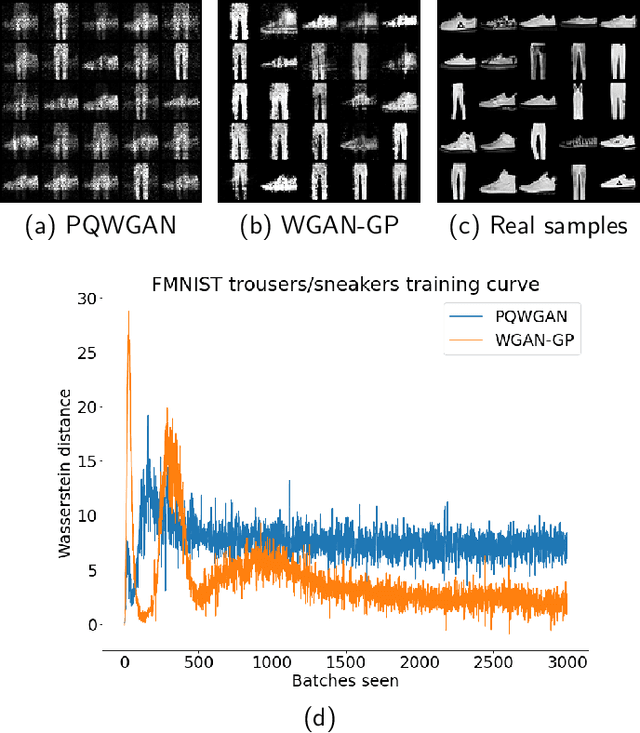
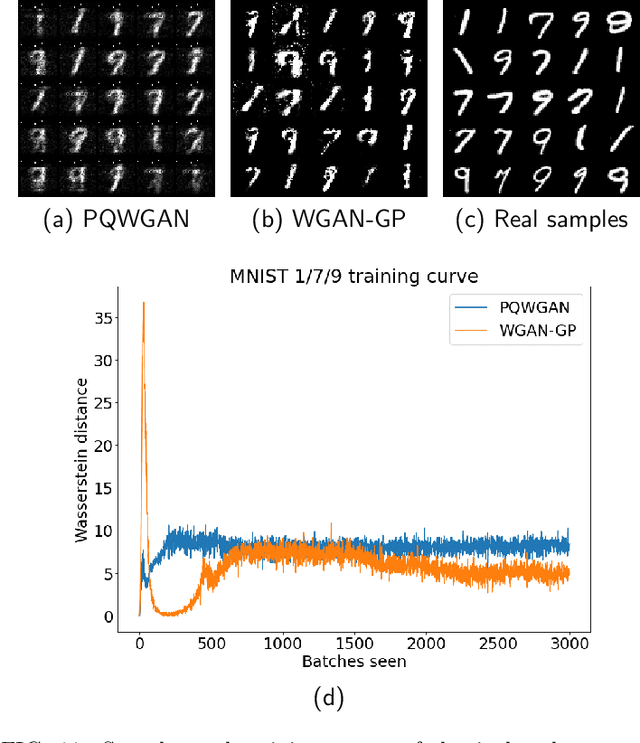
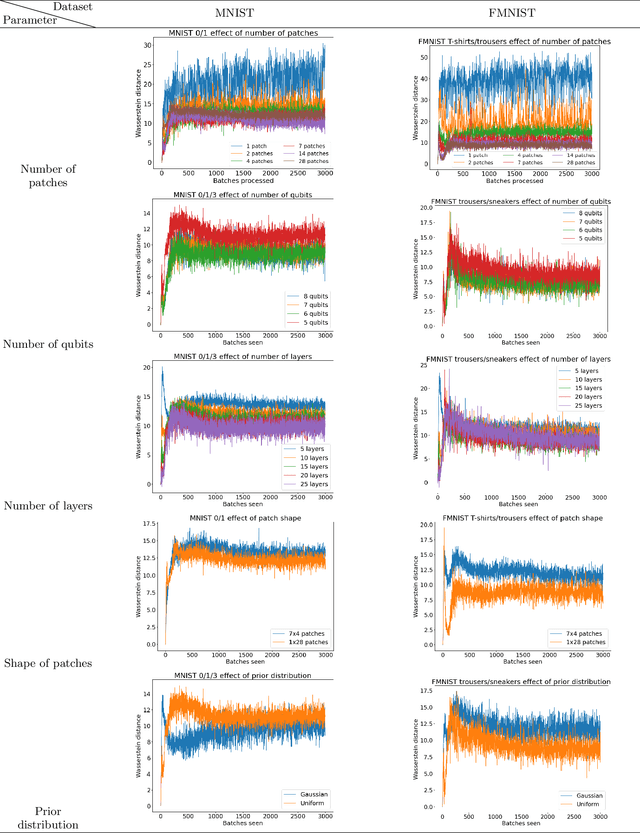
Quantum machine learning (QML) has received increasing attention due to its potential to outperform classical machine learning methods in various problems. A subclass of QML methods is quantum generative adversarial networks (QGANs) which have been studied as a quantum counterpart of classical GANs widely used in image manipulation and generation tasks. The existing work on QGANs is still limited to small-scale proof-of-concept examples based on images with significant down-scaling. Here we integrate classical and quantum techniques to propose a new hybrid quantum-classical GAN framework. We demonstrate its superior learning capabilities by generating $28 \times 28$ pixels grey-scale images without dimensionality reduction or classical pre/post-processing on multiple classes of the standard MNIST and Fashion MNIST datasets, which achieves comparable results to classical frameworks with 3 orders of magnitude less trainable generator parameters. To gain further insight into the working of our hybrid approach, we systematically explore the impact of its parameter space by varying the number of qubits, the size of image patches, the number of layers in the generator, the shape of the patches and the choice of prior distribution. Our results show that increasing the quantum generator size generally improves the learning capability of the network. The developed framework provides a foundation for future design of QGANs with optimal parameter set tailored for complex image generation tasks.
Benchmarking Adversarially Robust Quantum Machine Learning at Scale
Nov 23, 2022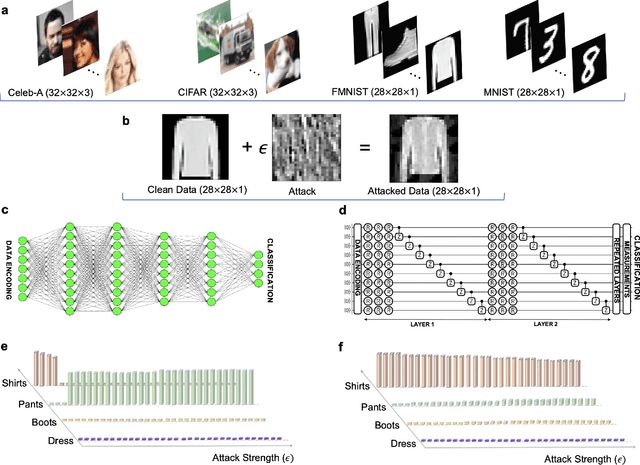
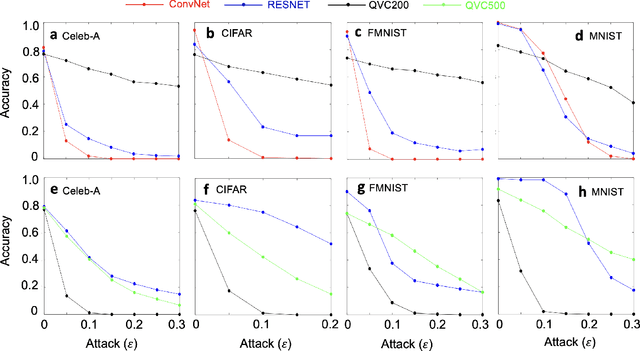

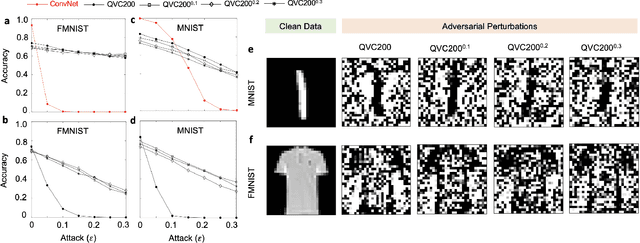
Machine learning (ML) methods such as artificial neural networks are rapidly becoming ubiquitous in modern science, technology and industry. Despite their accuracy and sophistication, neural networks can be easily fooled by carefully designed malicious inputs known as adversarial attacks. While such vulnerabilities remain a serious challenge for classical neural networks, the extent of their existence is not fully understood in the quantum ML setting. In this work, we benchmark the robustness of quantum ML networks, such as quantum variational classifiers (QVC), at scale by performing rigorous training for both simple and complex image datasets and through a variety of high-end adversarial attacks. Our results show that QVCs offer a notably enhanced robustness against classical adversarial attacks by learning features which are not detected by the classical neural networks, indicating a possible quantum advantage for ML tasks. Contrarily, and remarkably, the converse is not true, with attacks on quantum networks also capable of deceiving classical neural networks. By combining quantum and classical network outcomes, we propose a novel adversarial attack detection technology. Traditionally quantum advantage in ML systems has been sought through increased accuracy or algorithmic speed-up, but our work has revealed the potential for a new kind of quantum advantage through superior robustness of ML models, whose practical realisation will address serious security concerns and reliability issues of ML algorithms employed in a myriad of applications including autonomous vehicles, cybersecurity, and surveillance robotic systems.