 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchicalKV: A GPU Hash Table with Cache Semantics for Continuous Online Embedding Storage
Mar 17, 2026Traditional GPU hash tables preserve every inserted key -- a dictionary assumption that wastes scarce High Bandwidth Memory (HBM) when embedding tables routinely exceed single-GPU capacity. We challenge this assumption with cache semantics, where policy-driven eviction is a first-class operation. We introduce HierarchicalKV (HKV), the first general-purpose GPU hash table library whose normal full-capacity operating contract is cache-semantic: each full-bucket upsert (update-or-insert) is resolved in place by eviction or admission rejection rather than by rehashing or capacity-induced failure. HKV co-designs four core mechanisms -- cache-line-aligned buckets, in-line score-driven upsert, score-based dynamic dual-bucket selection, and triple-group concurrency -- and uses tiered key-value separation as a scaling enabler beyond HBM. On an NVIDIA H100 NVL GPU, HKV achieves up to 3.9 billion key-value pairs per second (B-KV/s) find throughput, stable across load factors 0.50-1.00 (<5% variation), and delivers 1.4x higher find throughput than WarpCore (the strongest dictionary-semantic GPU baseline at lambda=0.50) and up to 2.6-9.4x over indirection-based GPU baselines. Since its open-source release in October 2022, HKV has been integrated into multiple open-source recommendation frameworks.
Omni-LIVO: Robust RGB-Colored Multi-Camera Visual-Inertial-LiDAR Odometry via Photometric Migration and ESIKF Fusion
Sep 19, 2025



Wide field-of-view (FoV) LiDAR sensors provide dense geometry across large environments, but most existing LiDAR-inertial-visual odometry (LIVO) systems rely on a single camera, leading to limited spatial coverage and degraded robustness. We present Omni-LIVO, the first tightly coupled multi-camera LIVO system that bridges the FoV mismatch between wide-angle LiDAR and conventional cameras. Omni-LIVO introduces a Cross-View direct tracking strategy that maintains photometric consistency across non-overlapping views, and extends the Error-State Iterated Kalman Filter (ESIKF) with multi-view updates and adaptive covariance weighting. The system is evaluated on public benchmarks and our custom dataset, showing improved accuracy and robustness over state-of-the-art LIVO, LIO, and visual-inertial baselines. Code and dataset will be released upon publication.
Multi-level Certified Defense Against Poisoning Attacks in Offline Reinforcement Learning
May 27, 2025Similar to other machine learning frameworks, Offline Reinforcement Learning (RL) is shown to be vulnerable to poisoning attacks, due to its reliance on externally sourced datasets, a vulnerability that is exacerbated by its sequential nature. To mitigate the risks posed by RL poisoning, we extend certified defenses to provide larger guarantees against adversarial manipulation, ensuring robustness for both per-state actions, and the overall expected cumulative reward. Our approach leverages properties of Differential Privacy, in a manner that allows this work to span both continuous and discrete spaces, as well as stochastic and deterministic environments -- significantly expanding the scope and applicability of achievable guarantees. Empirical evaluations demonstrate that our approach ensures the performance drops to no more than $50\%$ with up to $7\%$ of the training data poisoned, significantly improving over the $0.008\%$ in prior work~\citep{wu_copa_2022}, while producing certified radii that is $5$ times larger as well. This highlights the potential of our framework to enhance safety and reliability in offline RL.
Fox in the Henhouse: Supply-Chain Backdoor Attacks Against Reinforcement Learning
May 26, 2025The current state-of-the-art backdoor attacks against Reinforcement Learning (RL) rely upon unrealistically permissive access models, that assume the attacker can read (or even write) the victim's policy parameters, observations, or rewards. In this work, we question whether such a strong assumption is required to launch backdoor attacks against RL. To answer this question, we propose the \underline{S}upply-\underline{C}h\underline{a}in \underline{B}ackdoor (SCAB) attack, which targets a common RL workflow: training agents using external agents that are provided separately or embedded within the environment. In contrast to prior works, our attack only relies on legitimate interactions of the RL agent with the supplied agents. Despite this limited access model, by poisoning a mere $3\%$ of training experiences, our attack can successfully activate over $90\%$ of triggered actions, reducing the average episodic return by $80\%$ for the victim. Our novel attack demonstrates that RL attacks are likely to become a reality under untrusted RL training supply-chains.
It's Simplex! Disaggregating Measures to Improve Certified Robustness
Sep 20, 2023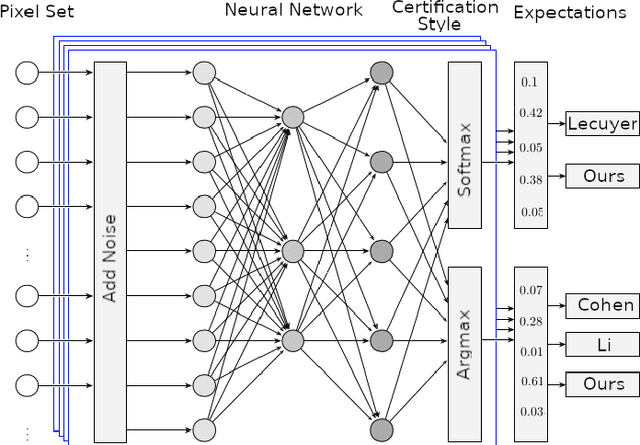
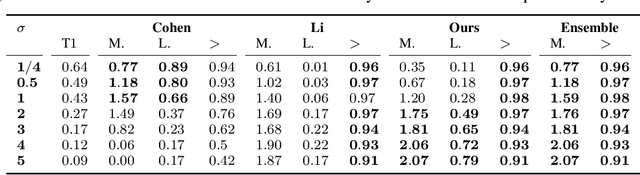
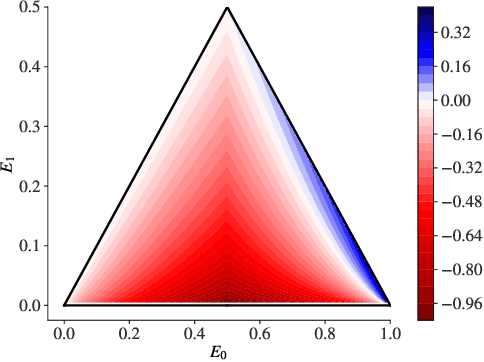
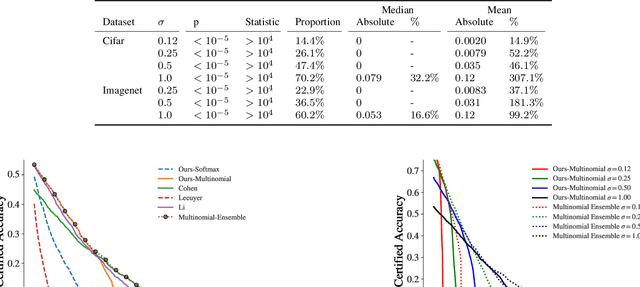
Certified robustness circumvents the fragility of defences against adversarial attacks, by endowing model predictions with guarantees of class invariance for attacks up to a calculated size. While there is value in these certifications, the techniques through which we assess their performance do not present a proper accounting of their strengths and weaknesses, as their analysis has eschewed consideration of performance over individual samples in favour of aggregated measures. By considering the potential output space of certified models, this work presents two distinct approaches to improve the analysis of certification mechanisms, that allow for both dataset-independent and dataset-dependent measures of certification performance. Embracing such a perspective uncovers new certification approaches, which have the potential to more than double the achievable radius of certification, relative to current state-of-the-art. Empirical evaluation verifies that our new approach can certify $9\%$ more samples at noise scale $\sigma = 1$, with greater relative improvements observed as the difficulty of the predictive task increases.
Enhancing the Antidote: Improved Pointwise Certifications against Poisoning Attacks
Aug 15, 2023

Poisoning attacks can disproportionately influence model behaviour by making small changes to the training corpus. While defences against specific poisoning attacks do exist, they in general do not provide any guarantees, leaving them potentially countered by novel attacks. In contrast, by examining worst-case behaviours Certified Defences make it possible to provide guarantees of the robustness of a sample against adversarial attacks modifying a finite number of training samples, known as pointwise certification. We achieve this by exploiting both Differential Privacy and the Sampled Gaussian Mechanism to ensure the invariance of prediction for each testing instance against finite numbers of poisoned examples. In doing so, our model provides guarantees of adversarial robustness that are more than twice as large as those provided by prior certifications.
MEMD-ABSA: A Multi-Element Multi-Domain Dataset for Aspect-Based Sentiment Analysis
Jun 29, 2023



Aspect-based sentiment analysis is a long-standing research interest in the field of opinion mining, and in recent years, researchers have gradually shifted their focus from simple ABSA subtasks to end-to-end multi-element ABSA tasks. However, the datasets currently used in the research are limited to individual elements of specific tasks, usually focusing on in-domain settings, ignoring implicit aspects and opinions, and with a small data scale. To address these issues, we propose a large-scale Multi-Element Multi-Domain dataset (MEMD) that covers the four elements across five domains, including nearly 20,000 review sentences and 30,000 quadruples annotated with explicit and implicit aspects and opinions for ABSA research. Meanwhile, we evaluate generative and non-generative baselines on multiple ABSA subtasks under the open domain setting, and the results show that open domain ABSA as well as mining implicit aspects and opinions remain ongoing challenges to be addressed. The datasets are publicly released at \url{https://github.com/NUSTM/MEMD-ABSA}.
Dual Residual Attention Network for Image Denoising
May 07, 2023



In image denoising, deep convolutional neural networks (CNNs) can obtain favorable performance on removing spatially invariant noise. However, many of these networks cannot perform well on removing the real noise (i.e. spatially variant noise) generated during image acquisition or transmission, which severely sets back their application in practical image denoising tasks. Instead of continuously increasing the network depth, many researchers have revealed that expanding the width of networks can also be a useful way to improve model performance. It also has been verified that feature filtering can promote the learning ability of the models. Therefore, in this paper, we propose a novel Dual-branch Residual Attention Network (DRANet) for image denoising, which has both the merits of a wide model architecture and attention-guided feature learning. The proposed DRANet includes two different parallel branches, which can capture complementary features to enhance the learning ability of the model. We designed a new residual attention block (RAB) and a novel hybrid dilated residual attention block (HDRAB) for the upper and the lower branches, respectively. The RAB and HDRAB can capture rich local features through multiple skip connections between different convolutional layers, and the unimportant features are dropped by the residual attention modules. Meanwhile, the long skip connections in each branch, and the global feature fusion between the two parallel branches can capture the global features as well. Moreover, the proposed DRANet uses downsampling operations and dilated convolutions to increase the size of the receptive field, which can enable DRANet to capture more image context information. Extensive experiments demonstrate that compared with other state-of-the-art denoising methods, our DRANet can produce competitive denoising performance both on synthetic and real-world noise removal.
Exploiting Certified Defences to Attack Randomised Smoothing
Feb 09, 2023In guaranteeing that no adversarial examples exist within a bounded region, certification mechanisms play an important role in neural network robustness. Concerningly, this work demonstrates that the certification mechanisms themselves introduce a new, heretofore undiscovered attack surface, that can be exploited by attackers to construct smaller adversarial perturbations. While these attacks exist outside the certification region in no way invalidate certifications, minimising a perturbation's norm significantly increases the level of difficulty associated with attack detection. In comparison to baseline attacks, our new framework yields smaller perturbations more than twice as frequently as any other approach, resulting in an up to $34 \%$ reduction in the median perturbation norm. That this approach also requires $90 \%$ less computational time than approaches like PGD. That these reductions are possible suggests that exploiting this new attack vector would allow attackers to more frequently construct hard to detect adversarial attacks, by exploiting the very systems designed to defend deployed models.
Double Bubble, Toil and Trouble: Enhancing Certified Robustness through Transitivity
Oct 12, 2022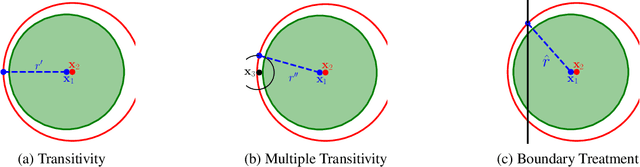
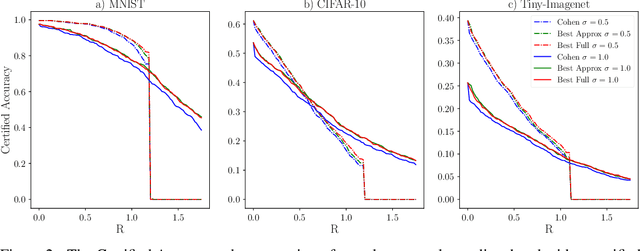
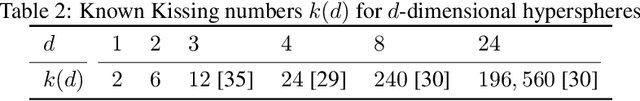
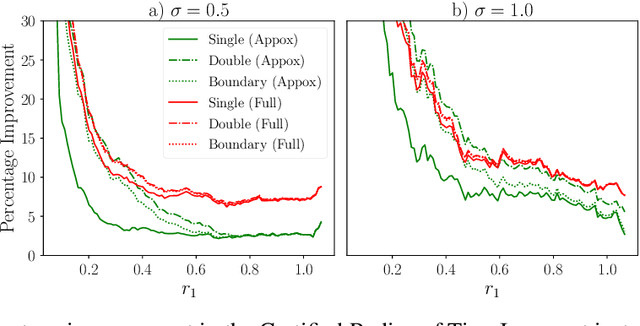
In response to subtle adversarial examples flipping classifications of neural network models, recent research has promoted certified robustness as a solution. There, invariance of predictions to all norm-bounded attacks is achieved through randomised smoothing of network inputs. Today's state-of-the-art certifications make optimal use of the class output scores at the input instance under test: no better radius of certification (under the $L_2$ norm) is possible given only these score. However, it is an open question as to whether such lower bounds can be improved using local information around the instance under test. In this work, we demonstrate how today's "optimal" certificates can be improved by exploiting both the transitivity of certifications, and the geometry of the input space, giving rise to what we term Geometrically-Informed Certified Robustness. By considering the smallest distance to points on the boundary of a set of certifications this approach improves certifications for more than $80\%$ of Tiny-Imagenet instances, yielding an on average $5 \%$ increase in the associated certification. When incorporating training time processes that enhance the certified radius, our technique shows even more promising results, with a uniform $4$ percentage point increase in the achieved certified radius.