 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's Simplex! Disaggregating Measures to Improve Certified Robustness
Paper and Code
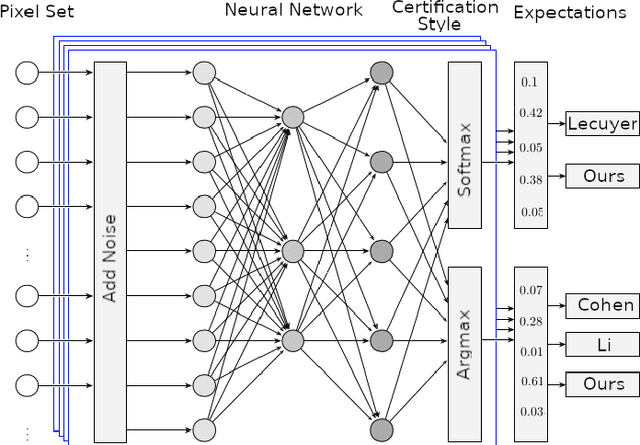
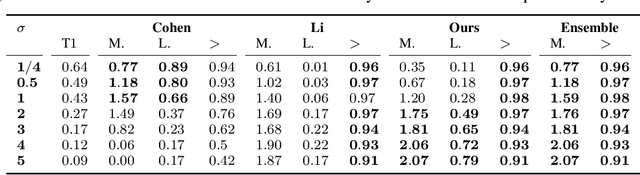
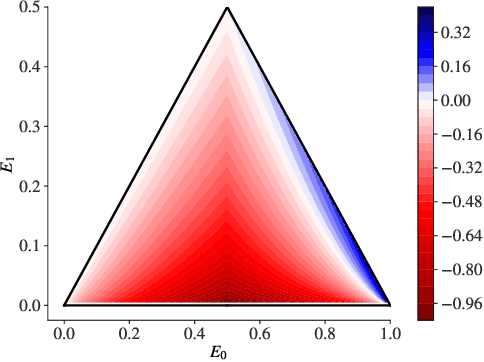
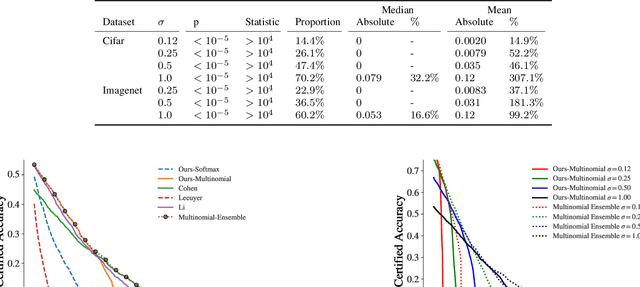
Certified robustness circumvents the fragility of defences against adversarial attacks, by endowing model predictions with guarantees of class invariance for attacks up to a calculated size. While there is value in these certifications, the techniques through which we assess their performance do not present a proper accounting of their strengths and weaknesses, as their analysis has eschewed consideration of performance over individual samples in favour of aggregated measures. By considering the potential output space of certified models, this work presents two distinct approaches to improve the analysis of certification mechanisms, that allow for both dataset-independent and dataset-dependent measures of certification performance. Embracing such a perspective uncovers new certification approaches, which have the potential to more than double the achievable radius of certification, relative to current state-of-the-art. Empirical evaluation verifies that our new approach can certify $9\%$ more samples at noise scale $\sigma = 1$, with greater relative improvements observed as the difficulty of the predictive task increases.