 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Robustness Certification for Vision-Language Models
Jun 17, 2026Vision-language models (VLMs) are now widely used in downstream tasks. However, real-world applications often expose VLMs to distribution shifts induced by semantic variation (e.g., shape, size, and style). Robustness certification determines if a model's prediction changes when transformations are applied to its input. While most certification frameworks study geometric or pixel-level transformations over inputs, this work proposes a novel framework that enables certifying VLM robustness under semantic-level transformations. Leveraging the open-vocabulary capability of VLMs, we use text prompts as semantic proxies to construct transformations parameterized by an extent that controls the degree of semantic variation. By characterizing the VLM decision boundary in closed form, our framework quantitatively certifies extent intervals for which the predicted class remains unchanged under the semantic transformation. Our framework is the first to certify VLM robustness under semantic-level variations without requiring additional data for each variation, making it practical to apply. Experiments on both synthetic and real-world data show that our framework enables certifying robustness under diverse semantic variations across scenarios.
Hearing the Unspoken: Language Model Priors for Acoustic Adversarial Attacks
Jun 05, 2026Automatic Speech Recognition (ASR) systems operating in real-time settings must process acoustic input under strict temporal constraints, where transcription decisions are inherently made on incomplete information. This causal constraint serves as an information bottleneck on attackers, significantly limiting attack performance. Our new Semantic Gambit attack breaks this causal limitation by augmenting the adversary with predictive context derived from a Large Language Model in real-time. Our experiments show that this form of augmentation can elevate the corpus-level Word Error Rate to 35.6% -- a three-fold increase over the current state-of-the-art. Ultimately, this work reveals how common, low-latency LLM tooling can be exploited to systematically subvert real-time ASR pipelines.
Position: Certified Robustness Does Not (Yet) Imply Model Security
Jun 16, 2025While certified robustness is widely promoted as a solution to adversarial examples in Artificial Intelligence systems, significant challenges remain before these techniques can be meaningfully deployed in real-world applications. We identify critical gaps in current research, including the paradox of detection without distinction, the lack of clear criteria for practitioners to evaluate certification schemes, and the potential security risks arising from users' expectations surrounding ``guaranteed" robustness claims. This position paper is a call to arms for the certification research community, proposing concrete steps to address these fundamental challenges and advance the field toward practical applicability.
Multi-level Certified Defense Against Poisoning Attacks in Offline Reinforcement Learning
May 27, 2025Similar to other machine learning frameworks, Offline Reinforcement Learning (RL) is shown to be vulnerable to poisoning attacks, due to its reliance on externally sourced datasets, a vulnerability that is exacerbated by its sequential nature. To mitigate the risks posed by RL poisoning, we extend certified defenses to provide larger guarantees against adversarial manipulation, ensuring robustness for both per-state actions, and the overall expected cumulative reward. Our approach leverages properties of Differential Privacy, in a manner that allows this work to span both continuous and discrete spaces, as well as stochastic and deterministic environments -- significantly expanding the scope and applicability of achievable guarantees. Empirical evaluations demonstrate that our approach ensures the performance drops to no more than $50\%$ with up to $7\%$ of the training data poisoned, significantly improving over the $0.008\%$ in prior work~\citep{wu_copa_2022}, while producing certified radii that is $5$ times larger as well. This highlights the potential of our framework to enhance safety and reliability in offline RL.
Fox in the Henhouse: Supply-Chain Backdoor Attacks Against Reinforcement Learning
May 26, 2025The current state-of-the-art backdoor attacks against Reinforcement Learning (RL) rely upon unrealistically permissive access models, that assume the attacker can read (or even write) the victim's policy parameters, observations, or rewards. In this work, we question whether such a strong assumption is required to launch backdoor attacks against RL. To answer this question, we propose the \underline{S}upply-\underline{C}h\underline{a}in \underline{B}ackdoor (SCAB) attack, which targets a common RL workflow: training agents using external agents that are provided separately or embedded within the environment. In contrast to prior works, our attack only relies on legitimate interactions of the RL agent with the supplied agents. Despite this limited access model, by poisoning a mere $3\%$ of training experiences, our attack can successfully activate over $90\%$ of triggered actions, reducing the average episodic return by $80\%$ for the victim. Our novel attack demonstrates that RL attacks are likely to become a reality under untrusted RL training supply-chains.
It's Simplex! Disaggregating Measures to Improve Certified Robustness
Sep 20, 2023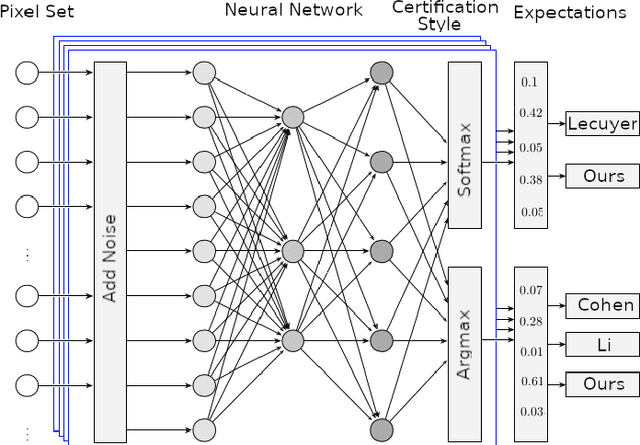
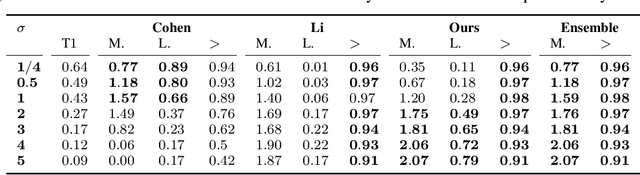
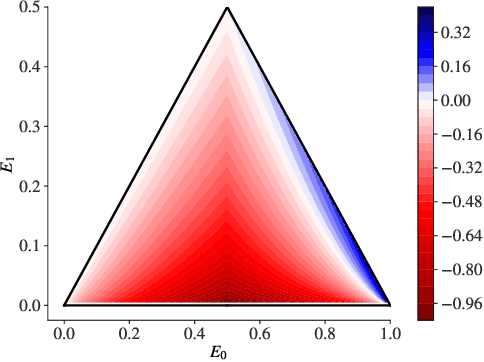
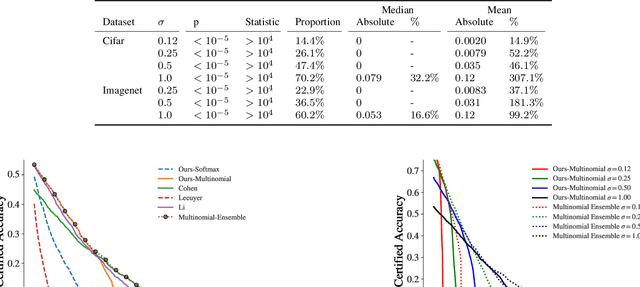
Certified robustness circumvents the fragility of defences against adversarial attacks, by endowing model predictions with guarantees of class invariance for attacks up to a calculated size. While there is value in these certifications, the techniques through which we assess their performance do not present a proper accounting of their strengths and weaknesses, as their analysis has eschewed consideration of performance over individual samples in favour of aggregated measures. By considering the potential output space of certified models, this work presents two distinct approaches to improve the analysis of certification mechanisms, that allow for both dataset-independent and dataset-dependent measures of certification performance. Embracing such a perspective uncovers new certification approaches, which have the potential to more than double the achievable radius of certification, relative to current state-of-the-art. Empirical evaluation verifies that our new approach can certify $9\%$ more samples at noise scale $\sigma = 1$, with greater relative improvements observed as the difficulty of the predictive task increases.
Enhancing the Antidote: Improved Pointwise Certifications against Poisoning Attacks
Aug 15, 2023

Poisoning attacks can disproportionately influence model behaviour by making small changes to the training corpus. While defences against specific poisoning attacks do exist, they in general do not provide any guarantees, leaving them potentially countered by novel attacks. In contrast, by examining worst-case behaviours Certified Defences make it possible to provide guarantees of the robustness of a sample against adversarial attacks modifying a finite number of training samples, known as pointwise certification. We achieve this by exploiting both Differential Privacy and the Sampled Gaussian Mechanism to ensure the invariance of prediction for each testing instance against finite numbers of poisoned examples. In doing so, our model provides guarantees of adversarial robustness that are more than twice as large as those provided by prior certifications.
Failure-tolerant Distributed Learning for Anomaly Detection in Wireless Networks
Mar 23, 2023



The analysis of distributed techniques is often focused upon their efficiency, without considering their robustness (or lack thereof). Such a consideration is particularly important when devices or central servers can fail, which can potentially cripple distributed systems. When such failures arise in wireless communications networks, important services that they use/provide (like anomaly detection) can be left inoperable and can result in a cascade of security problems. In this paper, we present a novel method to address these risks by combining both flat- and star-topologies, combining the performance and reliability benefits of both. We refer to this method as "Tol-FL", due to its increased failure-tolerance as compared to the technique of Federated Learning. Our approach both limits device failure risks while outperforming prior methods by up to 8% in terms of anomaly detection AUROC in a range of realistic settings that consider client as well as server failure, all while reducing communication costs. This performance demonstrates that Tol-FL is a highly suitable method for distributed model training for anomaly detection, especially in the domain of wireless networks.
Exploiting Certified Defences to Attack Randomised Smoothing
Feb 09, 2023In guaranteeing that no adversarial examples exist within a bounded region, certification mechanisms play an important role in neural network robustness. Concerningly, this work demonstrates that the certification mechanisms themselves introduce a new, heretofore undiscovered attack surface, that can be exploited by attackers to construct smaller adversarial perturbations. While these attacks exist outside the certification region in no way invalidate certifications, minimising a perturbation's norm significantly increases the level of difficulty associated with attack detection. In comparison to baseline attacks, our new framework yields smaller perturbations more than twice as frequently as any other approach, resulting in an up to $34 \%$ reduction in the median perturbation norm. That this approach also requires $90 \%$ less computational time than approaches like PGD. That these reductions are possible suggests that exploiting this new attack vector would allow attackers to more frequently construct hard to detect adversarial attacks, by exploiting the very systems designed to defend deployed models.
Double Bubble, Toil and Trouble: Enhancing Certified Robustness through Transitivity
Oct 12, 2022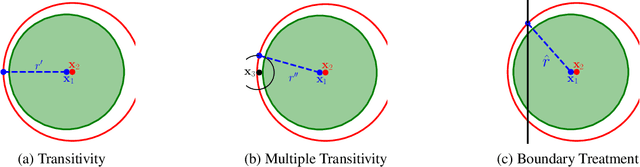
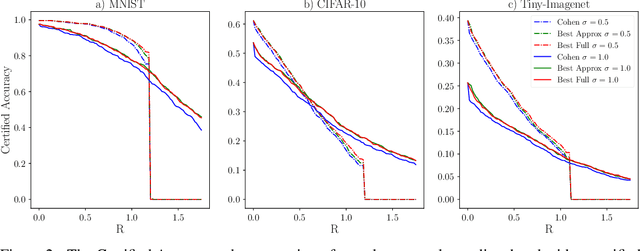
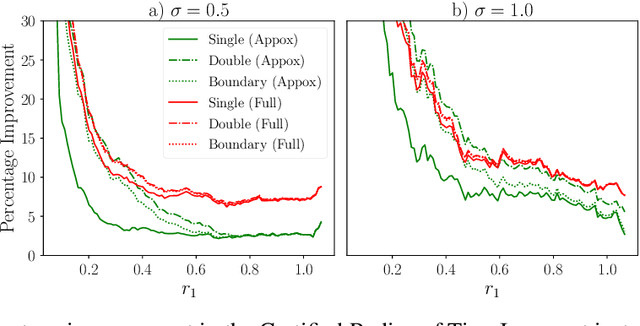
In response to subtle adversarial examples flipping classifications of neural network models, recent research has promoted certified robustness as a solution. There, invariance of predictions to all norm-bounded attacks is achieved through randomised smoothing of network inputs. Today's state-of-the-art certifications make optimal use of the class output scores at the input instance under test: no better radius of certification (under the $L_2$ norm) is possible given only these score. However, it is an open question as to whether such lower bounds can be improved using local information around the instance under test. In this work, we demonstrate how today's "optimal" certificates can be improved by exploiting both the transitivity of certifications, and the geometry of the input space, giving rise to what we term Geometrically-Informed Certified Robustness. By considering the smallest distance to points on the boundary of a set of certifications this approach improves certifications for more than $80\%$ of Tiny-Imagenet instances, yielding an on average $5 \%$ increase in the associated certification. When incorporating training time processes that enhance the certified radius, our technique shows even more promising results, with a uniform $4$ percentage point increase in the achieved certified radius.