 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearing the Unspoken: Language Model Priors for Acoustic Adversarial Attacks
Jun 05, 2026Automatic Speech Recognition (ASR) systems operating in real-time settings must process acoustic input under strict temporal constraints, where transcription decisions are inherently made on incomplete information. This causal constraint serves as an information bottleneck on attackers, significantly limiting attack performance. Our new Semantic Gambit attack breaks this causal limitation by augmenting the adversary with predictive context derived from a Large Language Model in real-time. Our experiments show that this form of augmentation can elevate the corpus-level Word Error Rate to 35.6% -- a three-fold increase over the current state-of-the-art. Ultimately, this work reveals how common, low-latency LLM tooling can be exploited to systematically subvert real-time ASR pipelines.
Multilingual Unlearning in LLMs: Transfer, Dynamics, and Reversibility
Jun 02, 2026Large language models (LLMs) can memorize sensitive facts, motivating unlearning methods that remove targeted knowledge without costly retraining. However, unlearning research remains heavily English-centric. We study multilingual unlearning by extending the TOFU benchmark to five languages, and fine-tune, unlearn, and query our models with different permutations of languages. We find that unlearning transfer, the ability of an unlearned model to "forget" facts in languages other than the unlearning language, is highly variable: e.g., it is strongest between languages sharing scripts and families, and we show that the unlearning language predicts which query languages are most likely to yield the strongest transfer. Layer-wise analysis reveals that unlearning leaves the shared cross-lingual latent space largely intact in early layers, instead operating primarily in later decoding layers. This suggests that unlearning does not truly erase knowledge, but rather induces superficial suppression. Exploiting this structure, a single inference-time steering direction reverses much of this suppression across languages, recovering 50% (Qwen) and 90% (Gemma) of the unlearned knowledge.
Semantic-aware Adversarial Fine-tuning for CLIP
Feb 12, 2026Recent studies have shown that CLIP model's adversarial robustness in zero-shot classification tasks can be enhanced by adversarially fine-tuning its image encoder with adversarial examples (AEs), which are generated by minimizing the cosine similarity between images and a hand-crafted template (e.g., ''A photo of a {label}''). However, it has been shown that the cosine similarity between a single image and a single hand-crafted template is insufficient to measure the similarity for image-text pairs. Building on this, in this paper, we find that the AEs generated using cosine similarity may fail to fool CLIP when the similarity metric is replaced with semantically enriched alternatives, making the image encoder fine-tuned with these AEs less robust. To overcome this issue, we first propose a semantic-ensemble attack to generate semantic-aware AEs by minimizing the average similarity between the original image and an ensemble of refined textual descriptions. These descriptions are initially generated by a foundation model to capture core semantic features beyond hand-crafted templates and are then refined to reduce hallucinations. To this end, we propose Semantic-aware Adversarial Fine-Tuning (SAFT), which fine-tunes CLIP's image encoder with semantic-aware AEs. Extensive experiments show that SAFT outperforms current methods, achieving substantial improvements in zero-shot adversarial robustness across 16 datasets. Our code is available at: https://github.com/tmlr-group/SAFT.
Where is the Watermark? Interpretable Watermark Detection at the Block Level
Dec 17, 2025Recent advances in generative AI have enabled the creation of highly realistic digital content, raising concerns around authenticity, ownership, and misuse. While watermarking has become an increasingly important mechanism to trace and protect digital media, most existing image watermarking schemes operate as black boxes, producing global detection scores without offering any insight into how or where the watermark is present. This lack of transparency impacts user trust and makes it difficult to interpret the impact of tampering. In this paper, we present a post-hoc image watermarking method that combines localised embedding with region-level interpretability. Our approach embeds watermark signals in the discrete wavelet transform domain using a statistical block-wise strategy. This allows us to generate detection maps that reveal which regions of an image are likely watermarked or altered. We show that our method achieves strong robustness against common image transformations while remaining sensitive to semantic manipulations. At the same time, the watermark remains highly imperceptible. Compared to prior post-hoc methods, our approach offers more interpretable detection while retaining competitive robustness. For example, our watermarks are robust to cropping up to half the image.
AdaptDel: Adaptable Deletion Rate Randomized Smoothing for Certified Robustness
Nov 12, 2025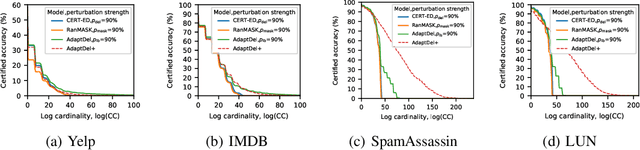
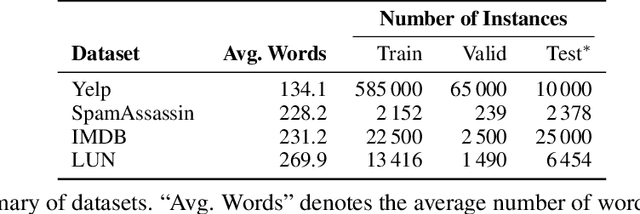
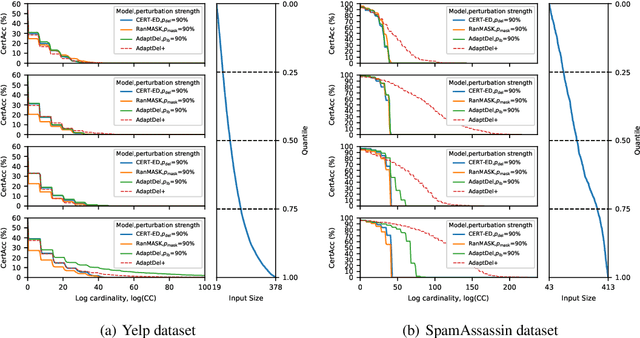
We consider the problem of certified robustness for sequence classification against edit distance perturbations. Naturally occurring inputs of varying lengths (e.g., sentences in natural language processing tasks) present a challenge to current methods that employ fixed-rate deletion mechanisms and lead to suboptimal performance. To this end, we introduce AdaptDel methods with adaptable deletion rates that dynamically adjust based on input properties. We extend the theoretical framework of randomized smoothing to variable-rate deletion, ensuring sound certification with respect to edit distance. We achieve strong empirical results in natural language tasks, observing up to 30 orders of magnitude improvement to median cardinality of the certified region, over state-of-the-art certifications.
Position: Certified Robustness Does Not (Yet) Imply Model Security
Jun 16, 2025While certified robustness is widely promoted as a solution to adversarial examples in Artificial Intelligence systems, significant challenges remain before these techniques can be meaningfully deployed in real-world applications. We identify critical gaps in current research, including the paradox of detection without distinction, the lack of clear criteria for practitioners to evaluate certification schemes, and the potential security risks arising from users' expectations surrounding ``guaranteed" robustness claims. This position paper is a call to arms for the certification research community, proposing concrete steps to address these fundamental challenges and advance the field toward practical applicability.
Multi-level Certified Defense Against Poisoning Attacks in Offline Reinforcement Learning
May 27, 2025Similar to other machine learning frameworks, Offline Reinforcement Learning (RL) is shown to be vulnerable to poisoning attacks, due to its reliance on externally sourced datasets, a vulnerability that is exacerbated by its sequential nature. To mitigate the risks posed by RL poisoning, we extend certified defenses to provide larger guarantees against adversarial manipulation, ensuring robustness for both per-state actions, and the overall expected cumulative reward. Our approach leverages properties of Differential Privacy, in a manner that allows this work to span both continuous and discrete spaces, as well as stochastic and deterministic environments -- significantly expanding the scope and applicability of achievable guarantees. Empirical evaluations demonstrate that our approach ensures the performance drops to no more than $50\%$ with up to $7\%$ of the training data poisoned, significantly improving over the $0.008\%$ in prior work~\citep{wu_copa_2022}, while producing certified radii that is $5$ times larger as well. This highlights the potential of our framework to enhance safety and reliability in offline RL.
Fox in the Henhouse: Supply-Chain Backdoor Attacks Against Reinforcement Learning
May 26, 2025The current state-of-the-art backdoor attacks against Reinforcement Learning (RL) rely upon unrealistically permissive access models, that assume the attacker can read (or even write) the victim's policy parameters, observations, or rewards. In this work, we question whether such a strong assumption is required to launch backdoor attacks against RL. To answer this question, we propose the \underline{S}upply-\underline{C}h\underline{a}in \underline{B}ackdoor (SCAB) attack, which targets a common RL workflow: training agents using external agents that are provided separately or embedded within the environment. In contrast to prior works, our attack only relies on legitimate interactions of the RL agent with the supplied agents. Despite this limited access model, by poisoning a mere $3\%$ of training experiences, our attack can successfully activate over $90\%$ of triggered actions, reducing the average episodic return by $80\%$ for the victim. Our novel attack demonstrates that RL attacks are likely to become a reality under untrusted RL training supply-chains.
DDAD: A Two-pronged Adversarial Defense Based on Distributional Discrepancy
Mar 04, 2025Statistical adversarial data detection (SADD) detects whether an upcoming batch contains adversarial examples (AEs) by measuring the distributional discrepancies between clean examples (CEs) and AEs. In this paper, we reveal the potential strength of SADD-based methods by theoretically showing that minimizing distributional discrepancy can help reduce the expected loss on AEs. Nevertheless, despite these advantages, SADD-based methods have a potential limitation: they discard inputs that are detected as AEs, leading to the loss of clean information within those inputs. To address this limitation, we propose a two-pronged adversarial defense method, named Distributional-Discrepancy-based Adversarial Defense (DDAD). In the training phase, DDAD first optimizes the test power of the maximum mean discrepancy (MMD) to derive MMD-OPT, and then trains a denoiser by minimizing the MMD-OPT between CEs and AEs. In the inference phase, DDAD first leverages MMD-OPT to differentiate CEs and AEs, and then applies a two-pronged process: (1) directly feeding the detected CEs into the classifier, and (2) removing noise from the detected AEs by the distributional-discrepancy-based denoiser. Extensive experiments show that DDAD outperforms current state-of-the-art (SOTA) defense methods by notably improving clean and robust accuracy on CIFAR-10 and ImageNet-1K against adaptive white-box attacks.
CERT-ED: Certifiably Robust Text Classification for Edit Distance
Aug 01, 2024With the growing integration of AI in daily life, ensuring the robustness of systems to inference-time attacks is crucial. Among the approaches for certifying robustness to such adversarial examples, randomized smoothing has emerged as highly promising due to its nature as a wrapper around arbitrary black-box models. Previous work on randomized smoothing in natural language processing has primarily focused on specific subsets of edit distance operations, such as synonym substitution or word insertion, without exploring the certification of all edit operations. In this paper, we adapt Randomized Deletion (Huang et al., 2023) and propose, CERTified Edit Distance defense (CERT-ED) for natural language classification. Through comprehensive experiments, we demonstrate that CERT-ED outperforms the existing Hamming distance method RanMASK (Zeng et al., 2023) in 4 out of 5 datasets in terms of both accuracy and the cardinality of the certificate. By covering various threat models, including 5 direct and 5 transfer attacks, our method improves empirical robustness in 38 out of 50 settings.