 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatentMove: Towards Complex Human Movement Video Generation
May 28, 2025Image-to-video (I2V) generation seeks to produce realistic motion sequences from a single reference image. Although recent methods exhibit strong temporal consistency, they often struggle when dealing with complex, non-repetitive human movements, leading to unnatural deformations. To tackle this issue, we present LatentMove, a DiT-based framework specifically tailored for highly dynamic human animation. Our architecture incorporates a conditional control branch and learnable face/body tokens to preserve consistency as well as fine-grained details across frames. We introduce Complex-Human-Videos (CHV), a dataset featuring diverse, challenging human motions designed to benchmark the robustness of I2V systems. We also introduce two metrics to assess the flow and silhouette consistency of generated videos with their ground truth. Experimental results indicate that LatentMove substantially improves human animation quality--particularly when handling rapid, intricate movements--thereby pushing the boundaries of I2V generation. The code, the CHV dataset, and the evaluation metrics will be available at https://github.com/ --.
Faster Image2Video Generation: A Closer Look at CLIP Image Embedding's Impact on Spatio-Temporal Cross-Attentions
Jul 27, 2024



This paper investigates the role of CLIP image embeddings within the Stable Video Diffusion (SVD) framework, focusing on their impact on video generation quality and computational efficiency. Our findings indicate that CLIP embeddings, while crucial for aesthetic quality, do not significantly contribute towards the subject and background consistency of video outputs. Moreover, the computationally expensive cross-attention mechanism can be effectively replaced by a simpler linear layer. This layer is computed only once at the first diffusion inference step, and its output is then cached and reused throughout the inference process, thereby enhancing efficiency while maintaining high-quality outputs. Building on these insights, we introduce the VCUT, a training-free approach optimized for efficiency within the SVD architecture. VCUT eliminates temporal cross-attention and replaces spatial cross-attention with a one-time computed linear layer, significantly reducing computational load. The implementation of VCUT leads to a reduction of up to 322T Multiple-Accumulate Operations (MACs) per video and a decrease in model parameters by up to 50M, achieving a 20% reduction in latency compared to the baseline. Our approach demonstrates that conditioning during the Semantic Binding stage is sufficient, eliminating the need for continuous computation across all inference steps and setting a new standard for efficient video generation.
RS-Reg: Probabilistic and Robust Certified Regression Through Randomized Smoothing
May 14, 2024



Randomized smoothing has shown promising certified robustness against adversaries in classification tasks. Despite such success with only zeroth-order access to base models, randomized smoothing has not been extended to a general form of regression. By defining robustness in regression tasks flexibly through probabilities, we demonstrate how to establish upper bounds on input data point perturbation (using the $\ell_2$ norm) for a user-specified probability of observing valid outputs. Furthermore, we showcase the asymptotic property of a basic averaging function in scenarios where the regression model operates without any constraint. We then derive a certified upper bound of the input perturbations when dealing with a family of regression models where the outputs are bounded. Our simulations verify the validity of the theoretical results and reveal the advantages and limitations of simple smoothing functions, i.e., averaging, in regression tasks. The code is publicly available at \url{https://github.com/arekavandi/Certified_Robust_Regression}.
Box It to Bind It: Unified Layout Control and Attribute Binding in T2I Diffusion Models
Feb 27, 2024



While latent diffusion models (LDMs) excel at creating imaginative images, they often lack precision in semantic fidelity and spatial control over where objects are generated. To address these deficiencies, we introduce the Box-it-to-Bind-it (B2B) module - a novel, training-free approach for improving spatial control and semantic accuracy in text-to-image (T2I) diffusion models. B2B targets three key challenges in T2I: catastrophic neglect, attribute binding, and layout guidance. The process encompasses two main steps: i) Object generation, which adjusts the latent encoding to guarantee object generation and directs it within specified bounding boxes, and ii) attribute binding, guaranteeing that generated objects adhere to their specified attributes in the prompt. B2B is designed as a compatible plug-and-play module for existing T2I models, markedly enhancing model performance in addressing the key challenges. We evaluate our technique using the established CompBench and TIFA score benchmarks, demonstrating significant performance improvements compared to existing methods. The source code will be made publicly available at https://github.com/nextaistudio/BoxIt2BindIt.
Towards Adaptive Subspace Detection in Heterogeneous Environment
Jan 23, 2024In this paper, we aim to take one step forward to the scenario where an adaptive subspace detection framework is required to detect subspace signals in non-stationary environments. Despite the fact that this scenario is more realistic, the existing studies in detection theory mostly rely on homogeneous, or partially homogeneous assumptions in the environments for their design process meaning that the covariance matrices of primary and secondary datasets are exactly the same or different up to a scale factor. In this study, we allow some partial information of the train covariance matrix to be shared with the primary dataset, but the covariance matrix in the primary set can be entirely different in the structure. This is particularly true in radar systems where the secondary set is collected in distinct spatial and time zones. We design a Generalized Likelihood Ratio Test (GLRT) based detector where the noise is multivariate Gaussian and the subspace interference is assumed to be known. The simulation results reveal the superiority of the proposed approach in comparison with conventional detectors for such a realistic and general scenario.
Transformers in Small Object Detection: A Benchmark and Survey of State-of-the-Art
Sep 10, 2023



Transformers have rapidly gained popularity in computer vision, especially in the field of object recognition and detection. Upon examining the outcomes of state-of-the-art object detection methods, we noticed that transformers consistently outperformed well-established CNN-based detectors in almost every video or image dataset. While transformer-based approaches remain at the forefront of small object detection (SOD) techniques, this paper aims to explore the performance benefits offered by such extensive networks and identify potential reasons for their SOD superiority. Small objects have been identified as one of the most challenging object types in detection frameworks due to their low visibility. We aim to investigate potential strategies that could enhance transformers' performance in SOD. This survey presents a taxonomy of over 60 research studies on developed transformers for the task of SOD, spanning the years 2020 to 2023. These studies encompass a variety of detection applications, including small object detection in generic images, aerial images, medical images, active millimeter images, underwater images, and videos. We also compile and present a list of 12 large-scale datasets suitable for SOD that were overlooked in previous studies and compare the performance of the reviewed studies using popular metrics such as mean Average Precision (mAP), Frames Per Second (FPS), number of parameters, and more. Researchers can keep track of newer studies on our web page, which is available at \url{https://github.com/arekavandi/Transformer-SOD}.
Analysis and Evaluation of Explainable Artificial Intelligence on Suicide Risk Assessment
Mar 09, 2023This study investigates the effectiveness of Explainable Artificial Intelligence (XAI) techniques in predicting suicide risks and identifying the dominant causes for such behaviours. Data augmentation techniques and ML models are utilized to predict the associated risk. Furthermore, SHapley Additive exPlanations (SHAP) and correlation analysis are used to rank the importance of variables in predictions. Experimental results indicate that Decision Tree (DT), Random Forest (RF) and eXtreme Gradient Boosting (XGBoost) models achieve the best results while DT has the best performance with an accuracy of 95:23% and an Area Under Curve (AUC) of 0.95. As per SHAP results, anger problems, depression, and social isolation are the leading variables in predicting the risk of suicide, and patients with good incomes, respected occupations, and university education have the least risk. Results demonstrate the effectiveness of machine learning and XAI framework for suicide risk prediction, and they can assist psychiatrists in understanding complex human behaviours and can also assist in reliable clinical decision-making.
IT-RUDA: Information Theory Assisted Robust Unsupervised Domain Adaptation
Oct 24, 2022
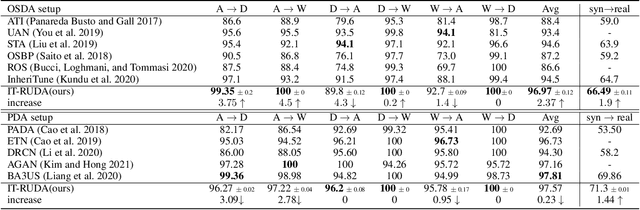

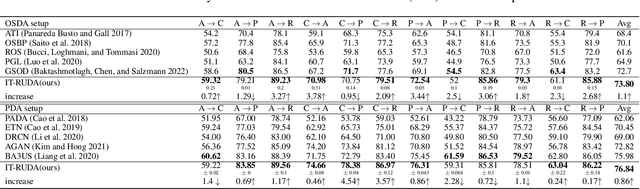
Distribution shift between train (source) and test (target) datasets is a common problem encountered in machine learning applications. One approach to resolve this issue is to use the Unsupervised Domain Adaptation (UDA) technique that carries out knowledge transfer from a label-rich source domain to an unlabeled target domain. Outliers that exist in either source or target datasets can introduce additional challenges when using UDA in practice. In this paper, $\alpha$-divergence is used as a measure to minimize the discrepancy between the source and target distributions while inheriting robustness, adjustable with a single parameter $\alpha$, as the prominent feature of this measure. Here, it is shown that the other well-known divergence-based UDA techniques can be derived as special cases of the proposed method. Furthermore, a theoretical upper bound is derived for the loss in the target domain in terms of the source loss and the initial $\alpha$-divergence between the two domains. The robustness of the proposed method is validated through testing on several benchmarked datasets in open-set and partial UDA setups where extra classes existing in target and source datasets are considered as outliers.
A Guide to Image and Video based Small Object Detection using Deep Learning : Case Study of Maritime Surveillance
Jul 26, 2022
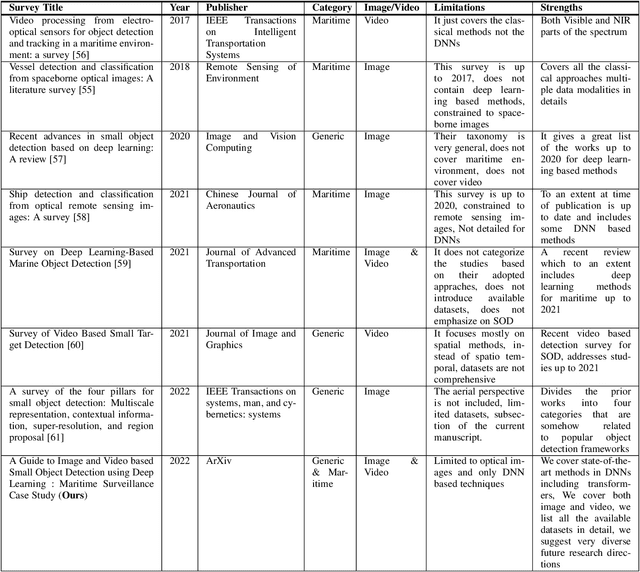
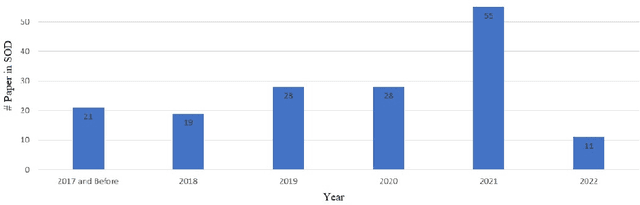
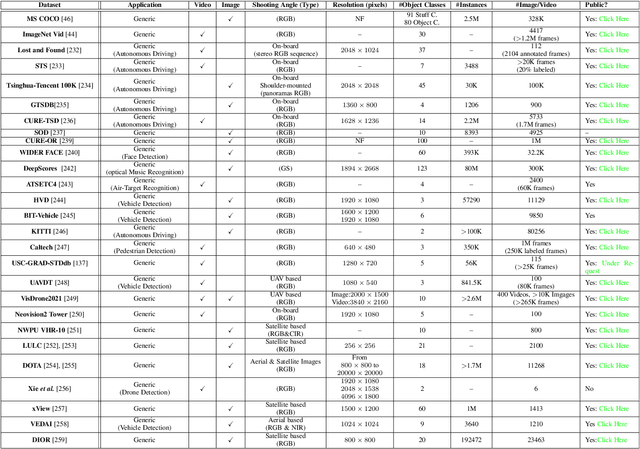
Small object detection (SOD) in optical images and videos is a challenging problem that even state-of-the-art generic object detection methods fail to accurately localize and identify such objects. Typically, small objects appear in real-world due to large camera-object distance. Because small objects occupy only a small area in the input image (e.g., less than 10%), the information extracted from such a small area is not always rich enough to support decision making. Multidisciplinary strategies are being developed by researchers working at the interface of deep learning and computer vision to enhance the performance of SOD deep learning based methods. In this paper, we provide a comprehensive review of over 160 research papers published between 2017 and 2022 in order to survey this growing subject. This paper summarizes the existing literature and provide a taxonomy that illustrates the broad picture of current research. We investigate how to improve the performance of small object detection in maritime environments, where increasing performance is critical. By establishing a connection between generic and maritime SOD research, future directions have been identified. In addition, the popular datasets that have been used for SOD for generic and maritime applications are discussed, and also well-known evaluation metrics for the state-of-the-art methods on some of the datasets are provided.