 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-process 3D Deviation Mapping and Defect Monitoring (3D-DM2) in High Production-rate Robotic Additive Manufacturing
Nov 06, 2025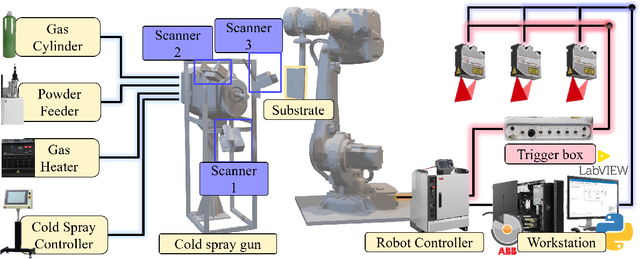
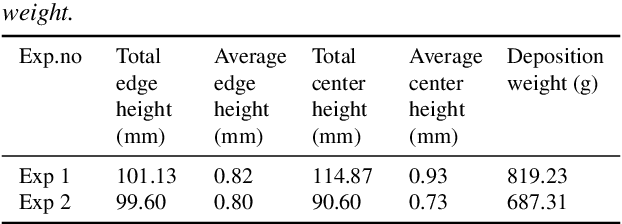

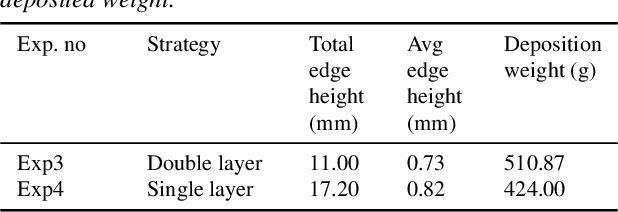
Additive manufacturing (AM) is an emerging digital manufacturing technology to produce complex and freeform objects through a layer-wise deposition. High deposition rate robotic AM (HDRRAM) processes, such as cold spray additive manufacturing (CSAM), offer significantly increased build speeds by delivering large volumes of material per unit time. However, maintaining shape accuracy remains a critical challenge, particularly due to process instabilities in current open-loop systems. Detecting these deviations as they occur is essential to prevent error propagation, ensure part quality, and minimize post-processing requirements. This study presents a real-time monitoring system to acquire and reconstruct the growing part and directly compares it with a near-net reference model to detect the shape deviation during the manufacturing process. The early identification of shape inconsistencies, followed by segmenting and tracking each deviation region, paves the way for timely intervention and compensation to achieve consistent part quality.
Enhanced Online Test-time Adaptation with Feature-Weight Cosine Alignment
May 12, 2024Online Test-Time Adaptation (OTTA) has emerged as an effective strategy to handle distributional shifts, allowing on-the-fly adaptation of pre-trained models to new target domains during inference, without the need for source data. We uncovered that the widely studied entropy minimization (EM) method for OTTA, suffers from noisy gradients due to ambiguity near decision boundaries and incorrect low-entropy predictions. To overcome these limitations, this paper introduces a novel cosine alignment optimization approach with a dual-objective loss function that refines the precision of class predictions and adaptability to novel domains. Specifically, our method optimizes the cosine similarity between feature vectors and class weight vectors, enhancing the precision of class predictions and the model's adaptability to novel domains. Our method outperforms state-of-the-art techniques and sets a new benchmark in multiple datasets, including CIFAR-10-C, CIFAR-100-C, ImageNet-C, Office-Home, and DomainNet datasets, demonstrating high accuracy and robustness against diverse corruptions and domain shifts.
Enhanced Multi-Target Tracking in Dynamic Environments: Distributed Control Methods Within the Random Finite Set Framework
Jan 25, 2024



Tracking multiple targets in dynamic environments using distributed sensor networks is a challenging problem that has received significant attention in recent years. In such scenarios, the network of sensors must coordinate their actions to estimate the locations and trajectories of multiple targets accurately. Multi-sensor control methods can improve the performance of these networks by enabling efficient utilization of resources and enhancing the accuracy of the estimated target states. This paper proposes two novel multi-sensor control methods that utilize the Random Finite Set (RFS) framework to address this problem. Our methods improve computational tractability and enable fully distributed control, making them suitable for real-time applications.
Single Domain Generalization via Normalised Cross-correlation Based Convolutions
Jul 12, 2023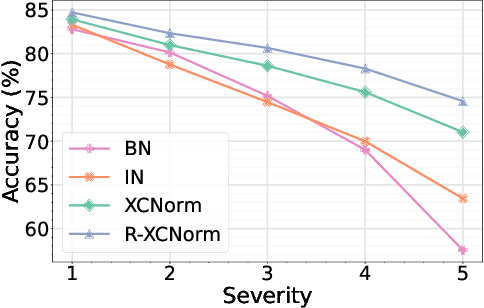
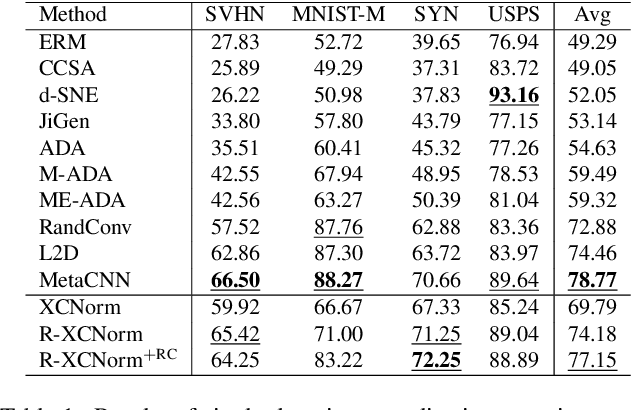
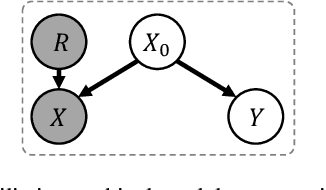

Deep learning techniques often perform poorly in the presence of domain shift, where the test data follows a different distribution than the training data. The most practically desirable approach to address this issue is Single Domain Generalization (S-DG), which aims to train robust models using data from a single source. Prior work on S-DG has primarily focused on using data augmentation techniques to generate diverse training data. In this paper, we explore an alternative approach by investigating the robustness of linear operators, such as convolution and dense layers commonly used in deep learning. We propose a novel operator called XCNorm that computes the normalized cross-correlation between weights and an input feature patch. This approach is invariant to both affine shifts and changes in energy within a local feature patch and eliminates the need for commonly used non-linear activation functions. We show that deep neural networks composed of this operator are robust to common semantic distribution shifts. Furthermore, our empirical results on single-domain generalization benchmarks demonstrate that our proposed technique performs comparably to the state-of-the-art methods.
IT-RUDA: Information Theory Assisted Robust Unsupervised Domain Adaptation
Oct 24, 2022
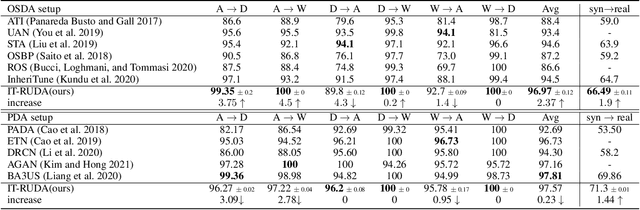

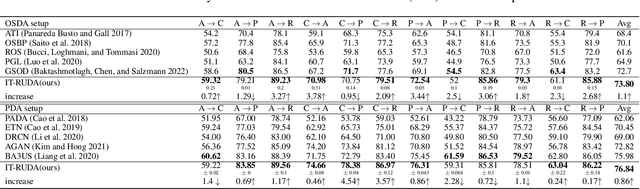
Distribution shift between train (source) and test (target) datasets is a common problem encountered in machine learning applications. One approach to resolve this issue is to use the Unsupervised Domain Adaptation (UDA) technique that carries out knowledge transfer from a label-rich source domain to an unlabeled target domain. Outliers that exist in either source or target datasets can introduce additional challenges when using UDA in practice. In this paper, $\alpha$-divergence is used as a measure to minimize the discrepancy between the source and target distributions while inheriting robustness, adjustable with a single parameter $\alpha$, as the prominent feature of this measure. Here, it is shown that the other well-known divergence-based UDA techniques can be derived as special cases of the proposed method. Furthermore, a theoretical upper bound is derived for the loss in the target domain in terms of the source loss and the initial $\alpha$-divergence between the two domains. The robustness of the proposed method is validated through testing on several benchmarked datasets in open-set and partial UDA setups where extra classes existing in target and source datasets are considered as outliers.
Distributed Complementary Fusion for Connected Vehicles
Sep 09, 2022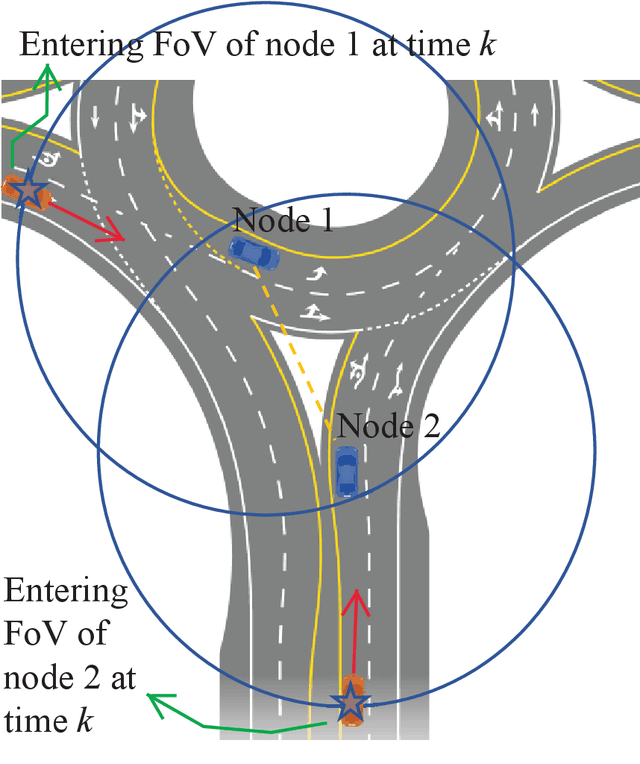
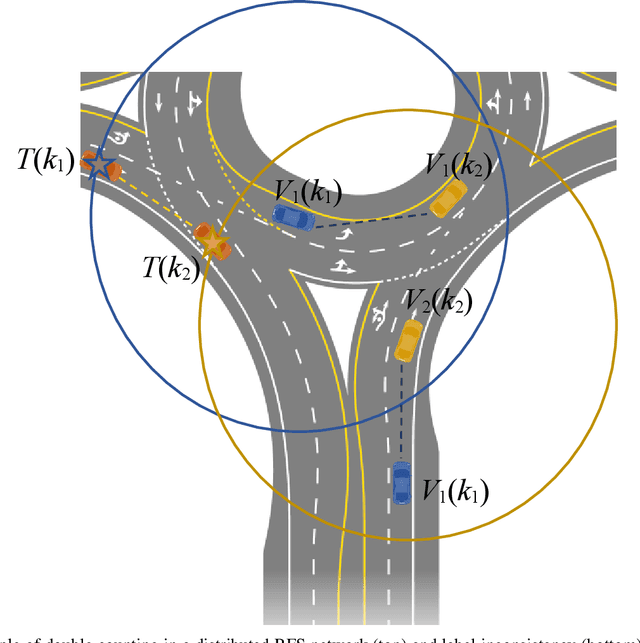
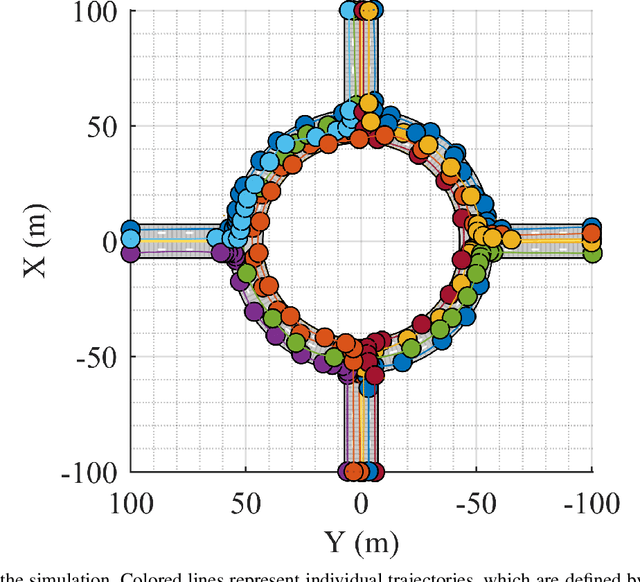
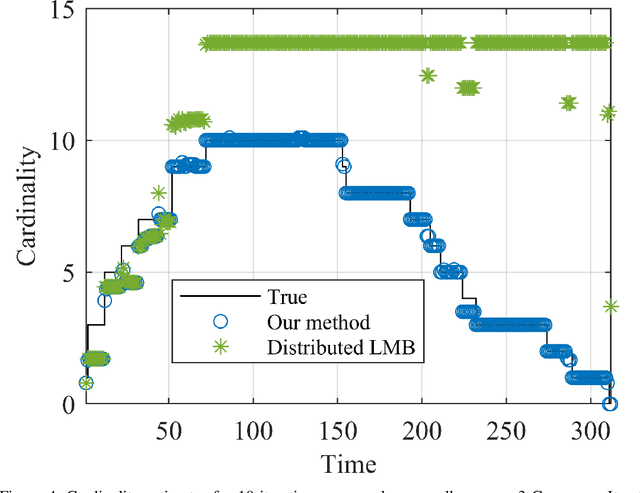
We present a random finite set-based method for achieving comprehensive situation awareness by each vehicle in a distributed vehicle network. Our solution is designed for labeled multi-Bernoulli filters running in each vehicle. It involves complementary fusion of sensor information locally running through consensus iterations. We introduce a novel label merging algorithm to eliminate double counting. We also extend the label space to incorporate sensor identities. This helps to overcome label inconsistencies. We show that the proposed algorithm is able to outperform the standard LMB filter using a distributed complementary approach with limited fields of view.
Interaction-Aware Labeled Multi-Bernoulli Filter
Apr 19, 2022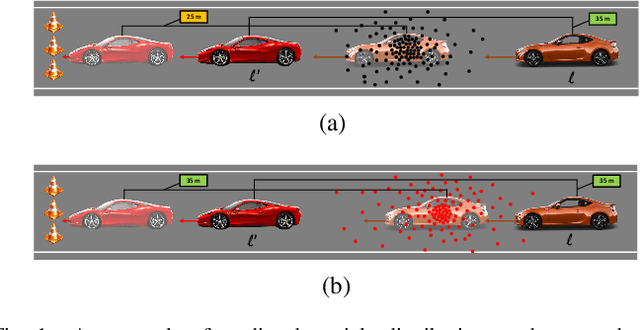
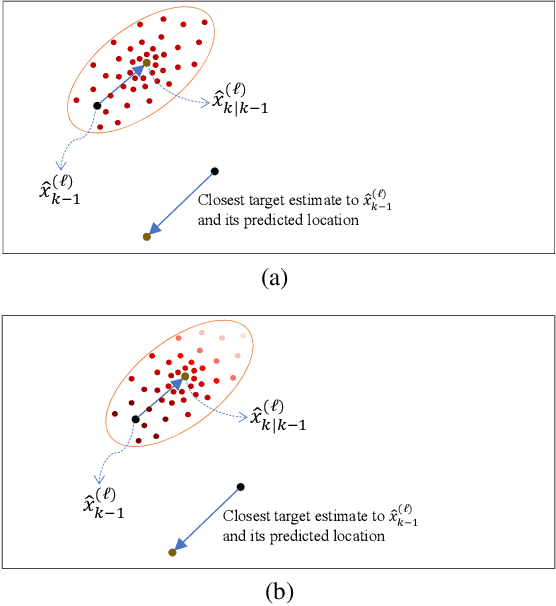
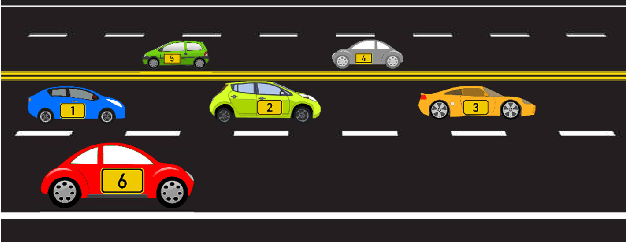
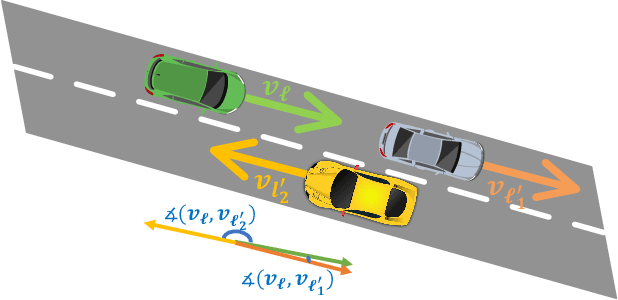
Tracking multiple objects through time is an important part of an intelligent transportation system. Random finite set (RFS)-based filters are one of the emerging techniques for tracking multiple objects. In multi-object tracking (MOT), a common assumption is that each object is moving independent of its surroundings. But in many real-world applications, target objects interact with one another and the environment. Such interactions, when considered for tracking, are usually modeled by an interactive motion model which is application specific. In this paper, we present a novel approach to incorporate target interactions within the prediction step of an RFS-based multi-target filter, i.e. labeled multi-Bernoulli (LMB) filter. The method has been developed for two practical applications of tracking a coordinated swarm and vehicles. The method has been tested for a complex vehicle tracking dataset and compared with the LMB filter through the OSPA and OSPA$^{(2)}$ metrics. The results demonstrate that the proposed interaction-aware method depicts considerable performance enhancement over the LMB filter in terms of the selected metrics.
ITSA: An Information-Theoretic Approach to Automatic Shortcut Avoidance and Domain Generalization in Stereo Matching Networks
Jan 06, 2022

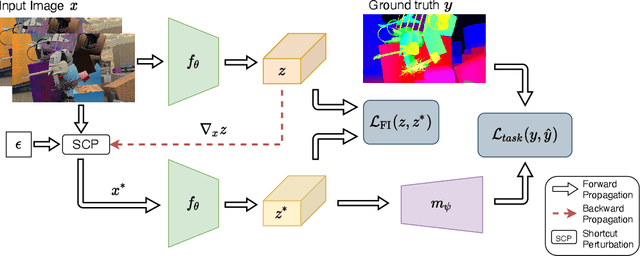
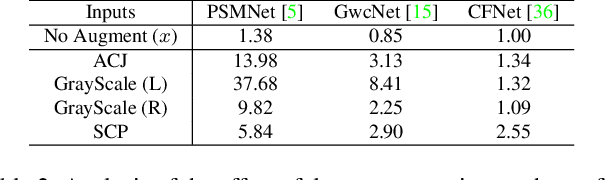
State-of-the-art stereo matching networks trained only on synthetic data often fail to generalize to more challenging real data domains. In this paper, we attempt to unfold an important factor that hinders the networks from generalizing across domains: through the lens of shortcut learning. We demonstrate that the learning of feature representations in stereo matching networks is heavily influenced by synthetic data artefacts (shortcut attributes). To mitigate this issue, we propose an Information-Theoretic Shortcut Avoidance~(ITSA) approach to automatically restrict shortcut-related information from being encoded into the feature representations. As a result, our proposed method learns robust and shortcut-invariant features by minimizing the sensitivity of latent features to input variations. To avoid the prohibitive computational cost of direct input sensitivity optimization, we propose an effective yet feasible algorithm to achieve robustness. We show that using this method, state-of-the-art stereo matching networks that are trained purely on synthetic data can effectively generalize to challenging and previously unseen real data scenarios. Importantly, the proposed method enhances the robustness of the synthetic trained networks to the point that they outperform their fine-tuned counterparts (on real data) for challenging out-of-domain stereo datasets.
Maximum Consensus by Weighted Influences of Monotone Boolean Functions
Dec 10, 2021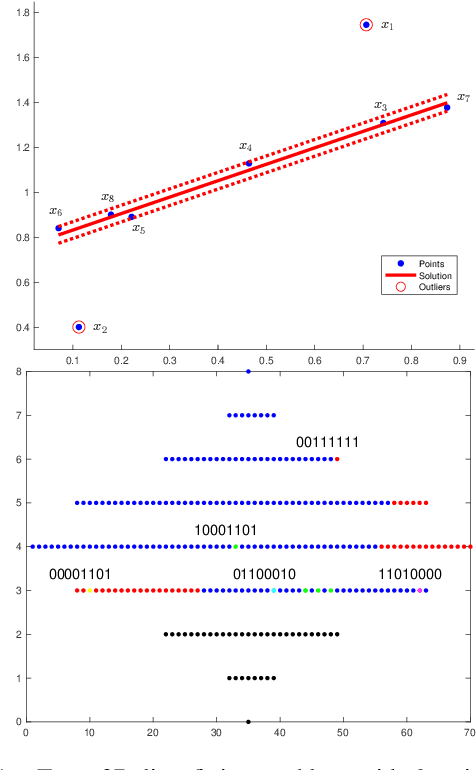
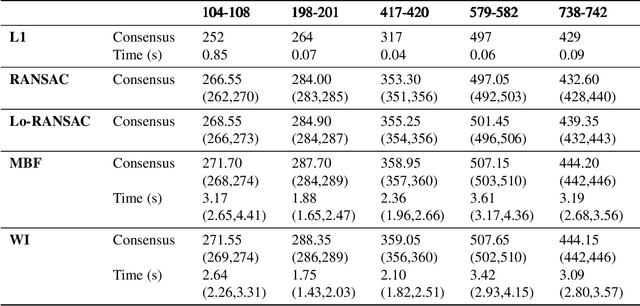
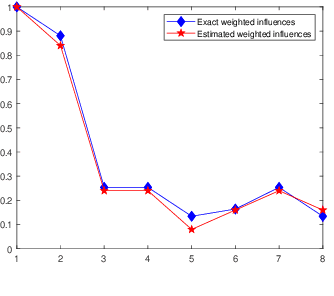
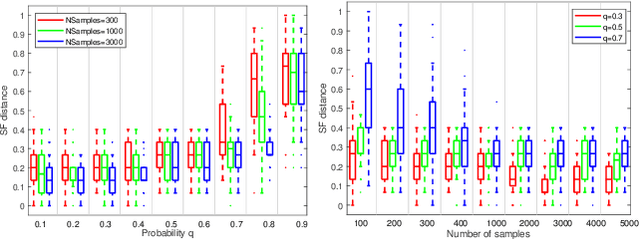
Robust model fitting is a fundamental problem in computer vision: used to pre-process raw data in the presence of outliers. Maximisation of Consensus (MaxCon) is one of the most popular robust criteria and widely used. Recently (Tennakoon et al. CVPR2021), a connection has been made between MaxCon and estimation of influences of a Monotone Boolean function. Equipping the Boolean cube with different measures and adopting different sampling strategies (two sides of the same coin) can have differing effects: which leads to the current study. This paper studies the concept of weighted influences for solving MaxCon. In particular, we study endowing the Boolean cube with the Bernoulli measure and performing biased (as opposed to uniform) sampling. Theoretically, we prove the weighted influences, under this measure, of points belonging to larger structures are smaller than those of points belonging to smaller structures in general. We also consider another "natural" family of sampling/weighting strategies, sampling with uniform measure concentrated on a particular (Hamming) level of the cube. Based on weighted sampling, we modify the algorithm of Tennakoon et al., and test on both synthetic and real datasets. This paper is not promoting a new approach per se, but rather studying the issue of weighted sampling. Accordingly, we are not claiming to have produced a superior algorithm: rather we show some modest gains of Bernoulli sampling, and we illuminate some of the interactions between structure in data and weighted sampling.
Anomaly Detection of Defect using Energy of Point Pattern Features within Random Finite Set Framework
Aug 27, 2021
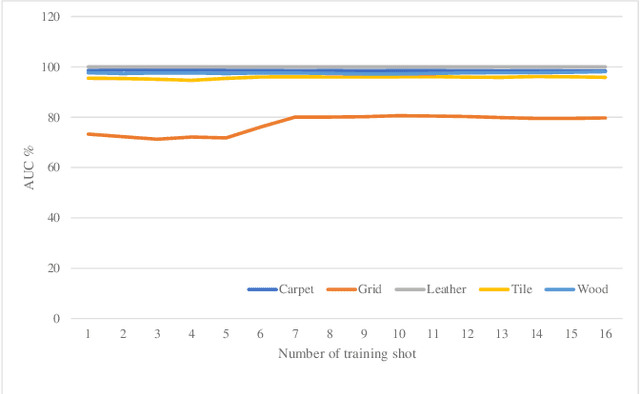
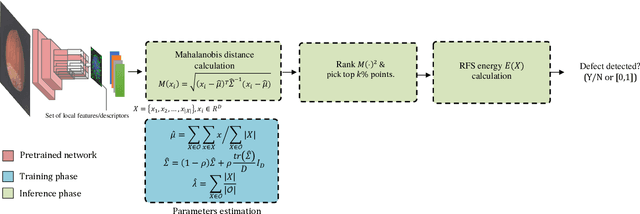

In this paper, we propose an efficient approach for industrial defect detection that is modeled based on anomaly detection using point pattern data. Most recent works use \textit{global features} for feature extraction to summarize image content. However, global features are not robust against lighting and viewpoint changes and do not describe the image's geometrical information to be fully utilized in the manufacturing industry. To the best of our knowledge, we are the first to propose using transfer learning of local/point pattern features to overcome these limitations and capture geometrical information of the image regions. We model these local/point pattern features as a random finite set (RFS). In addition we propose RFS energy, in contrast to RFS likelihood as anomaly score. The similarity distribution of point pattern features of the normal sample has been modeled as a multivariate Gaussian. Parameters learning of the proposed RFS energy does not require any heavy computation. We evaluate the proposed approach on the MVTec AD dataset, a multi-object defect detection dataset. Experimental results show the outstanding performance of our proposed approach compared to the state-of-the-art methods, and the proposed RFS energy outperforms the state-of-the-art in the few shot learning settings.