 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVAutoNet: Fast and Accurate 360$^{\circ}$ 3D Visual Perception For Self Driving
Mar 30, 2023

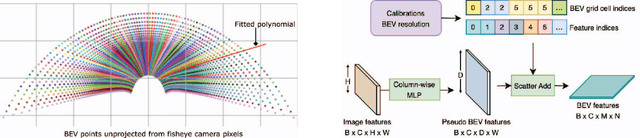

Robust real-time perception of 3D world is essential to the autonomous vehicle. We introduce an end-to-end surround camera perception system for self-driving. Our perception system is a novel multi-task, multi-camera network which takes a variable set of time-synced camera images as input and produces a rich collection of 3D signals such as sizes, orientations, locations of obstacles, parking spaces and free-spaces, etc. Our perception network is modular and end-to-end: 1) the outputs can be consumed directly by downstream modules without any post-processing such as clustering and fusion -- improving speed of model deployment and in-car testing 2) the whole network training is done in one single stage -- improving speed of model improvement and iterations. The network is well designed to have high accuracy while running at 53 fps on NVIDIA Orin SoC (system-on-a-chip). The network is robust to sensor mounting variations (within some tolerances) and can be quickly customized for different vehicle types via efficient model fine-tuning thanks of its capability of taking calibration parameters as additional inputs during training and testing. Most importantly, our network has been successfully deployed and being tested on real roads.
Fast Semantic-Assisted Outlier Removal for Large-scale Point Cloud Registration
Feb 21, 2022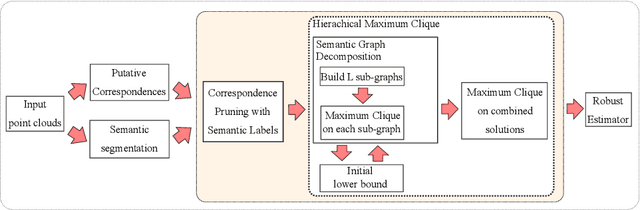
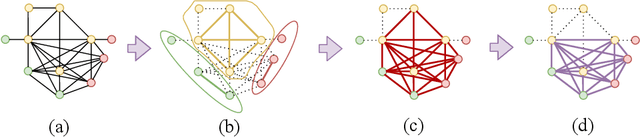

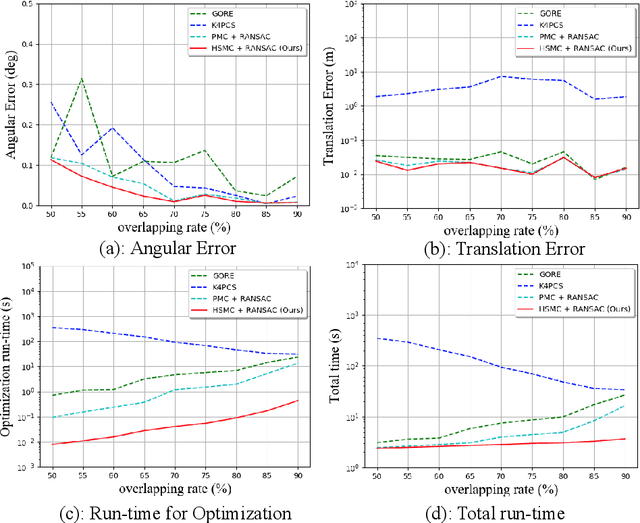
With current trends in sensors (cheaper, more volume of data) and applications (increasing affordability for new tasks, new ideas in what 3D data could be useful for); there is corresponding increasing interest in the ability to automatically, reliably, and cheaply, register together individual point clouds. The volume of data to handle, and still elusive need to have the registration occur fully reliably and fully automatically, mean there is a need to innovate further. One largely untapped area of innovation is that of exploiting the {\em semantic information} of the points in question. Points on a tree should match points on a tree, for example, and not points on car. Moreover, such a natural restriction is clearly human-like - a human would generally quickly eliminate candidate regions for matching based on semantics. Employing semantic information is not only efficient but natural. It is also timely - due to the recent advances in semantic classification capabilities. This paper advances this theme by demonstrating that state of the art registration techniques, in particular ones that rely on "preservation of length under rigid motion" as an underlying matching consistency constraint, can be augmented with semantic information. Semantic identity is of course also preserved under rigid-motion, but also under wider motions present in a scene. We demonstrate that not only the potential obstacle of cost of semantic segmentation, and the potential obstacle of the unreliability of semantic segmentation; are both no impediment to achieving both speed and accuracy in fully automatic registration of large scale point clouds.
Maximum Consensus by Weighted Influences of Monotone Boolean Functions
Dec 10, 2021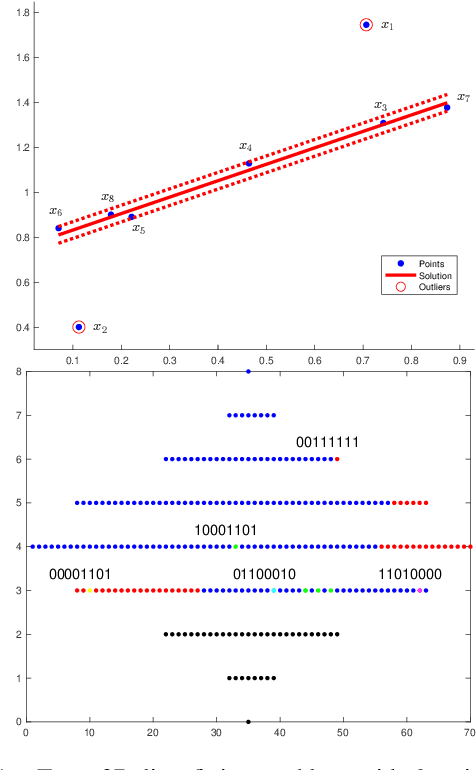
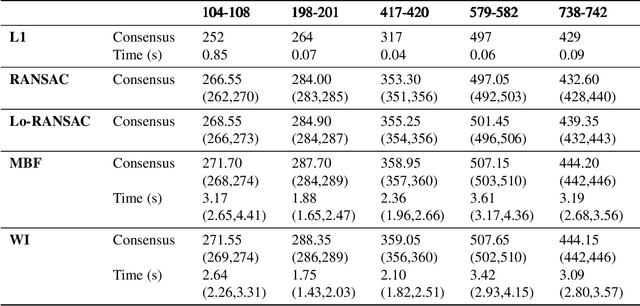
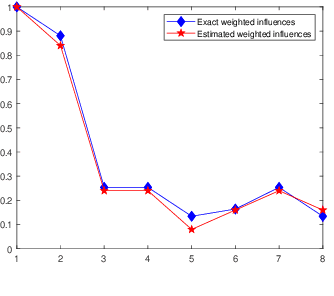
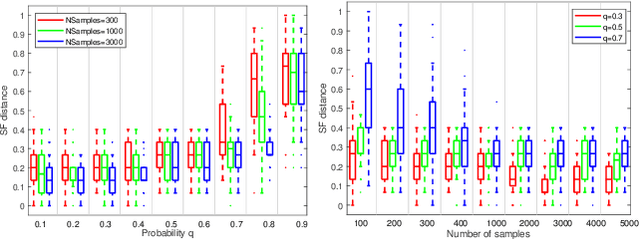
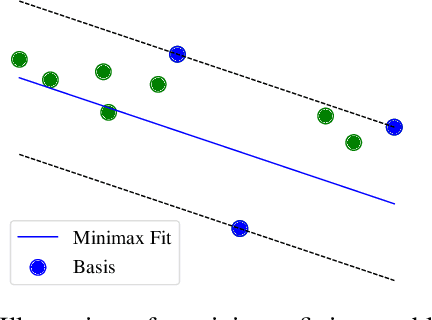
Robust model fitting is a fundamental problem in computer vision: used to pre-process raw data in the presence of outliers. Maximisation of Consensus (MaxCon) is one of the most popular robust criteria and widely used. Recently (Tennakoon et al. CVPR2021), a connection has been made between MaxCon and estimation of influences of a Monotone Boolean function. Equipping the Boolean cube with different measures and adopting different sampling strategies (two sides of the same coin) can have differing effects: which leads to the current study. This paper studies the concept of weighted influences for solving MaxCon. In particular, we study endowing the Boolean cube with the Bernoulli measure and performing biased (as opposed to uniform) sampling. Theoretically, we prove the weighted influences, under this measure, of points belonging to larger structures are smaller than those of points belonging to smaller structures in general. We also consider another "natural" family of sampling/weighting strategies, sampling with uniform measure concentrated on a particular (Hamming) level of the cube. Based on weighted sampling, we modify the algorithm of Tennakoon et al., and test on both synthetic and real datasets. This paper is not promoting a new approach per se, but rather studying the issue of weighted sampling. Accordingly, we are not claiming to have produced a superior algorithm: rather we show some modest gains of Bernoulli sampling, and we illuminate some of the interactions between structure in data and weighted sampling.
Indoor Semantic Scene Understanding using Multi-modality Fusion
Aug 17, 2021
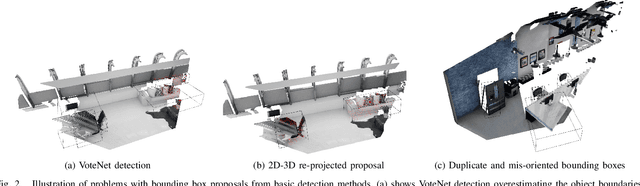

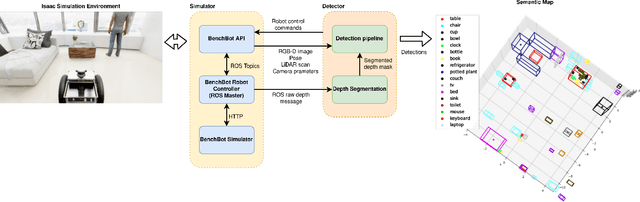
Seamless Human-Robot Interaction is the ultimate goal of developing service robotic systems. For this, the robotic agents have to understand their surroundings to better complete a given task. Semantic scene understanding allows a robotic agent to extract semantic knowledge about the objects in the environment. In this work, we present a semantic scene understanding pipeline that fuses 2D and 3D detection branches to generate a semantic map of the environment. The 2D mask proposals from state-of-the-art 2D detectors are inverse-projected to the 3D space and combined with 3D detections from point segmentation networks. Unlike previous works that were evaluated on collected datasets, we test our pipeline on an active photo-realistic robotic environment - BenchBot. Our novelty includes rectification of 3D proposals using projected 2D detections and modality fusion based on object size. This work is done as part of the Robotic Vision Scene Understanding Challenge (RVSU). The performance evaluation demonstrates that our pipeline has improved on baseline methods without significant computational bottleneck.
Unsupervised Learning for Robust Fitting:A Reinforcement Learning Approach
Mar 05, 2021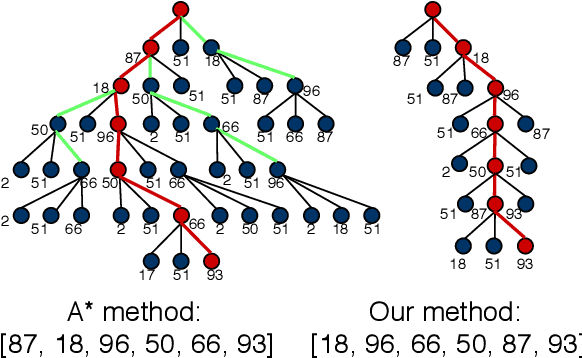
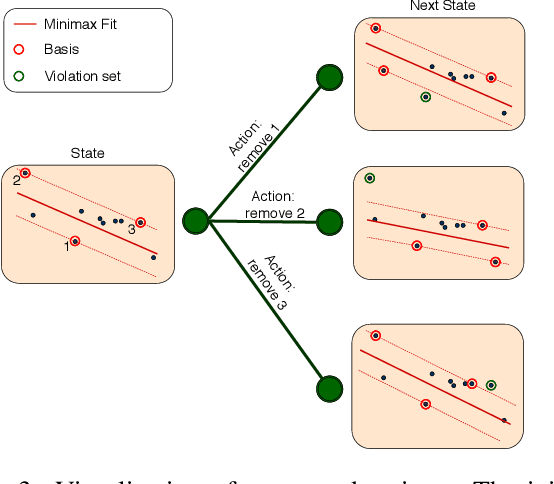
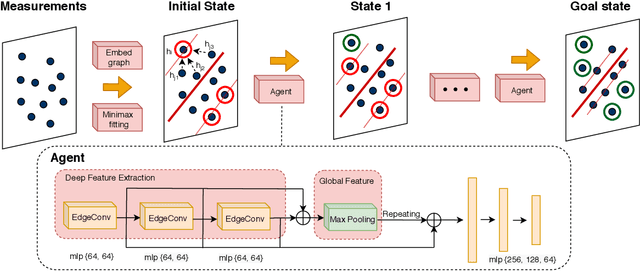
Robust model fitting is a core algorithm in a large number of computer vision applications. Solving this problem efficiently for datasets highly contaminated with outliers is, however, still challenging due to the underlying computational complexity. Recent literature has focused on learning-based algorithms. However, most approaches are supervised which require a large amount of labelled training data. In this paper, we introduce a novel unsupervised learning framework that learns to directly solve robust model fitting. Unlike other methods, our work is agnostic to the underlying input features, and can be easily generalized to a wide variety of LP-type problems with quasi-convex residuals. We empirically show that our method outperforms existing unsupervised learning approaches, and achieves competitive results compared to traditional methods on several important computer vision problems.