 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerteNet -- A Multi-Context Hybrid CNN Transformer for Accurate Vertebral Landmark Localization in Lateral Spine DXA Images
Feb 04, 2025



Lateral Spine Image (LSI) analysis is important for medical diagnosis, treatment planning, and detailed spinal health assessments. Although modalities like Computed Tomography and Digital X-ray Imaging are commonly used, Dual Energy X-ray Absorptiometry (DXA) is often preferred due to lower radiation exposure, seamless capture, and cost-effectiveness. Accurate Vertebral Landmark Localization (VLL) on LSIs is important to detect spinal conditions like kyphosis and lordosis, as well as assessing Abdominal Aortic Calcification (AAC) using Inter-Vertebral Guides (IVGs). Nonetheless, few automated VLL methodologies have concentrated on DXA LSIs. We present VerteNet, a hybrid CNN-Transformer model featuring a novel dual-resolution attention mechanism in self and cross-attention domains, referred to as Dual Resolution Self-Attention (DRSA) and Dual Resolution Cross-Attention (DRCA). These mechanisms capture the diverse frequencies in DXA images by operating at two different feature map resolutions. Additionally, we design a Multi-Context Feature Fusion Block (MCFB) that efficiently integrates the features using DRSA and DRCA. We train VerteNet on 620 DXA LSIs from various machines and achieve superior results compared to existing methods. We also design an algorithm that utilizes VerteNet's predictions in estimating the Region of Interest (ROI) to detect potential abdominal aorta cropping, where inadequate soft tissue hinders calcification assessment. Additionally, we present a small proof-of-concept study to show that IVGs generated from VLL information can improve inter-reader correlation in AAC scoring, addressing two key areas of disagreement in expert AAC-24 scoring: IVG placement and quality control for full abdominal aorta assessment. The code for this work can be found at https://github.com/zaidilyas89/VerteNet.
GLMHA A Guided Low-rank Multi-Head Self-Attention for Efficient Image Restoration and Spectral Reconstruction
Oct 01, 2024



Image restoration and spectral reconstruction are longstanding computer vision tasks. Currently, CNN-transformer hybrid models provide state-of-the-art performance for these tasks. The key common ingredient in the architectural designs of these models is Channel-wise Self-Attention (CSA). We first show that CSA is an overall low-rank operation. Then, we propose an instance-Guided Low-rank Multi-Head selfattention (GLMHA) to replace the CSA for a considerable computational gain while closely retaining the original model performance. Unique to the proposed GLMHA is its ability to provide computational gain for both short and long input sequences. In particular, the gain is in terms of both Floating Point Operations (FLOPs) and parameter count reduction. This is in contrast to the existing popular computational complexity reduction techniques, e.g., Linformer, Performer, and Reformer, for whom FLOPs overpower the efficient design tricks for the shorter input sequences. Moreover, parameter reduction remains unaccounted for in the existing methods.We perform an extensive evaluation for the tasks of spectral reconstruction from RGB images, spectral reconstruction from snapshot compressive imaging, motion deblurring, and image deraining by enhancing the best-performing models with our GLMHA. Our results show up to a 7.7 Giga FLOPs reduction with 370K fewer parameters required to closely retain the original performance of the best-performing models that employ CSA.
AACLiteNet: A Lightweight Model for Detection of Fine-Grained Abdominal Aortic Calcification
Sep 25, 2024



Cardiovascular Diseases (CVDs) are the leading cause of death worldwide, taking 17.9 million lives annually. Abdominal Aortic Calcification (AAC) is an established marker for CVD, which can be observed in lateral view Vertebral Fracture Assessment (VFA) scans, usually done for vertebral fracture detection. Early detection of AAC may help reduce the risk of developing clinical CVDs by encouraging preventive measures. Manual analysis of VFA scans for AAC measurement is time consuming and requires trained human assessors. Recently, efforts have been made to automate the process, however, the proposed models are either low in accuracy, lack granular level score prediction, or are too heavy in terms of inference time and memory footprint. Considering all these shortcomings of existing algorithms, we propose 'AACLiteNet', a lightweight deep learning model that predicts both cumulative and granular level AAC scores with high accuracy, and also has a low memory footprint, and computation cost (Floating Point Operations (FLOPs)). The AACLiteNet achieves a significantly improved one-vs-rest average accuracy of 85.94% as compared to the previous best 81.98%, with 19.88 times less computational cost and 2.26 times less memory footprint, making it implementable on portable computing devices.
StratXplore: Strategic Novelty-seeking and Instruction-aligned Exploration for Vision and Language Navigation
Sep 09, 2024



Embodied navigation requires robots to understand and interact with the environment based on given tasks. Vision-Language Navigation (VLN) is an embodied navigation task, where a robot navigates within a previously seen and unseen environment, based on linguistic instruction and visual inputs. VLN agents need access to both local and global action spaces; former for immediate decision making and the latter for recovering from navigational mistakes. Prior VLN agents rely only on instruction-viewpoint alignment for local and global decision making and back-track to a previously visited viewpoint, if the instruction and its current viewpoint mismatches. These methods are prone to mistakes, due to the complexity of the instruction and partial observability of the environment. We posit that, back-tracking is sub-optimal and agent that is aware of its mistakes can recover efficiently. For optimal recovery, exploration should be extended to unexplored viewpoints (or frontiers). The optimal frontier is a recently observed but unexplored viewpoint that aligns with the instruction and is novel. We introduce a memory-based and mistake-aware path planning strategy for VLN agents, called \textit{StratXplore}, that presents global and local action planning to select the optimal frontier for path correction. The proposed method collects all past actions and viewpoint features during navigation and then selects the optimal frontier suitable for recovery. Experimental results show this simple yet effective strategy improves the success rate on two VLN datasets with different task complexities.
Spatially-Aware Speaker for Vision-and-Language Navigation Instruction Generation
Sep 09, 2024



Embodied AI aims to develop robots that can \textit{understand} and execute human language instructions, as well as communicate in natural languages. On this front, we study the task of generating highly detailed navigational instructions for the embodied robots to follow. Although recent studies have demonstrated significant leaps in the generation of step-by-step instructions from sequences of images, the generated instructions lack variety in terms of their referral to objects and landmarks. Existing speaker models learn strategies to evade the evaluation metrics and obtain higher scores even for low-quality sentences. In this work, we propose SAS (Spatially-Aware Speaker), an instruction generator or \textit{Speaker} model that utilises both structural and semantic knowledge of the environment to produce richer instructions. For training, we employ a reward learning method in an adversarial setting to avoid systematic bias introduced by language evaluation metrics. Empirically, our method outperforms existing instruction generation models, evaluated using standard metrics. Our code is available at \url{https://github.com/gmuraleekrishna/SAS}.
Segment Any Object Model : Real-to-Simulation Fine-Tuning Strategy for Multi-Class Multi-Instance Segmentation
Mar 16, 2024



Multi-class multi-instance segmentation is the task of identifying masks for multiple object classes and multiple instances of the same class within an image. The foundational Segment Anything Model (SAM) is designed for promptable multi-class multi-instance segmentation but tends to output part or sub-part masks in the "everything" mode for various real-world applications. Whole object segmentation masks play a crucial role for indoor scene understanding, especially in robotics applications. We propose a new domain invariant Real-to-Simulation (Real-Sim) fine-tuning strategy for SAM. We use object images and ground truth data collected from Ai2Thor simulator during fine-tuning (real-to-sim). To allow our Segment Any Object Model (SAOM) to work in the "everything" mode, we propose the novel nearest neighbour assignment method, updating point embeddings for each ground-truth mask. SAOM is evaluated on our own dataset collected from Ai2Thor simulator. SAOM significantly improves on SAM, with a 28% increase in mIoU and a 25% increase in mAcc for 54 frequently-seen indoor object classes. Moreover, our Real-to-Simulation fine-tuning strategy demonstrates promising generalization performance in real environments without being trained on the real-world data (sim-to-real). The dataset and the code will be released after publication.
What Is Near?: Room Locality Learning for Enhanced Robot Vision-Language-Navigation in Indoor Living Environments
Sep 10, 2023Humans use their knowledge of common house layouts obtained from previous experiences to predict nearby rooms while navigating in new environments. This greatly helps them navigate previously unseen environments and locate their target room. To provide layout prior knowledge to navigational agents based on common human living spaces, we propose WIN (\textit{W}hat \textit{I}s \textit{N}ear), a commonsense learning model for Vision Language Navigation (VLN) tasks. VLN requires an agent to traverse indoor environments based on descriptive navigational instructions. Unlike existing layout learning works, WIN predicts the local neighborhood map based on prior knowledge of living spaces and current observation, operating on an imagined global map of the entire environment. The model infers neighborhood regions based on visual cues of current observations, navigational history, and layout common sense. We show that local-global planning based on locality knowledge and predicting the indoor layout allows the agent to efficiently select the appropriate action. Specifically, we devised a cross-modal transformer that utilizes this locality prior for decision-making in addition to visual inputs and instructions. Experimental results show that locality learning using WIN provides better generalizability compared to classical VLN agents in unseen environments. Our model performs favorably on standard VLN metrics, with Success Rate 68\% and Success weighted by Path Length 63\% in unseen environments.
SCOL: Supervised Contrastive Ordinal Loss for Abdominal Aortic Calcification Scoring on Vertebral Fracture Assessment Scans
Jul 22, 2023Abdominal Aortic Calcification (AAC) is a known marker of asymptomatic Atherosclerotic Cardiovascular Diseases (ASCVDs). AAC can be observed on Vertebral Fracture Assessment (VFA) scans acquired using Dual-Energy X-ray Absorptiometry (DXA) machines. Thus, the automatic quantification of AAC on VFA DXA scans may be used to screen for CVD risks, allowing early interventions. In this research, we formulate the quantification of AAC as an ordinal regression problem. We propose a novel Supervised Contrastive Ordinal Loss (SCOL) by incorporating a label-dependent distance metric with existing supervised contrastive loss to leverage the ordinal information inherent in discrete AAC regression labels. We develop a Dual-encoder Contrastive Ordinal Learning (DCOL) framework that learns the contrastive ordinal representation at global and local levels to improve the feature separability and class diversity in latent space among the AAC-24 genera. We evaluate the performance of the proposed framework using two clinical VFA DXA scan datasets and compare our work with state-of-the-art methods. Furthermore, for predicted AAC scores, we provide a clinical analysis to predict the future risk of a Major Acute Cardiovascular Event (MACE). Our results demonstrate that this learning enhances inter-class separability and strengthens intra-class consistency, which results in predicting the high-risk AAC classes with high sensitivity and high accuracy.
Single Domain Generalization via Normalised Cross-correlation Based Convolutions
Jul 12, 2023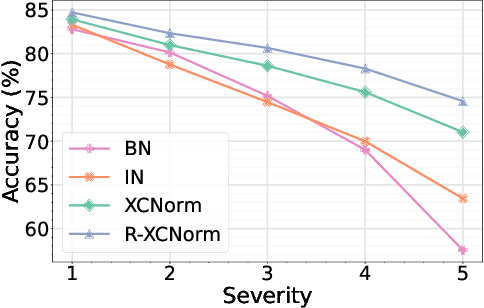
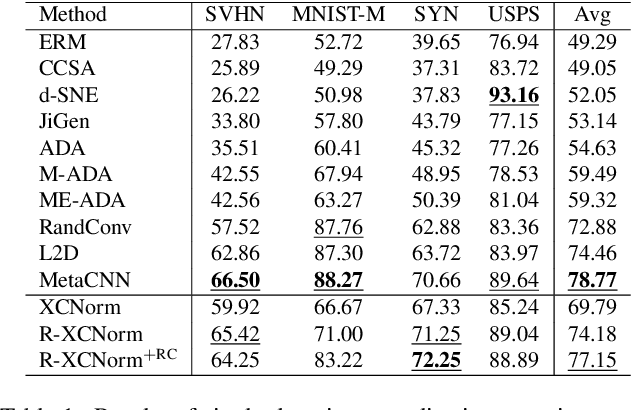

Deep learning techniques often perform poorly in the presence of domain shift, where the test data follows a different distribution than the training data. The most practically desirable approach to address this issue is Single Domain Generalization (S-DG), which aims to train robust models using data from a single source. Prior work on S-DG has primarily focused on using data augmentation techniques to generate diverse training data. In this paper, we explore an alternative approach by investigating the robustness of linear operators, such as convolution and dense layers commonly used in deep learning. We propose a novel operator called XCNorm that computes the normalized cross-correlation between weights and an input feature patch. This approach is invariant to both affine shifts and changes in energy within a local feature patch and eliminates the need for commonly used non-linear activation functions. We show that deep neural networks composed of this operator are robust to common semantic distribution shifts. Furthermore, our empirical results on single-domain generalization benchmarks demonstrate that our proposed technique performs comparably to the state-of-the-art methods.
Fast Semantic-Assisted Outlier Removal for Large-scale Point Cloud Registration
Feb 21, 2022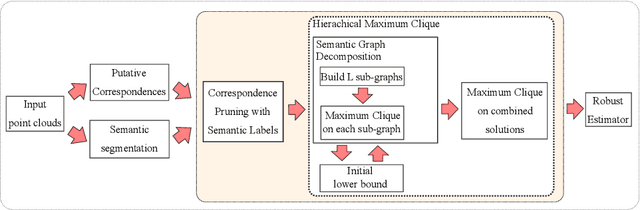
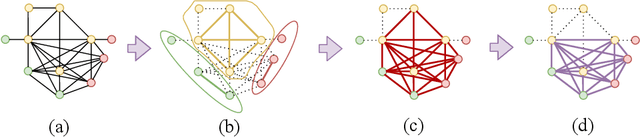

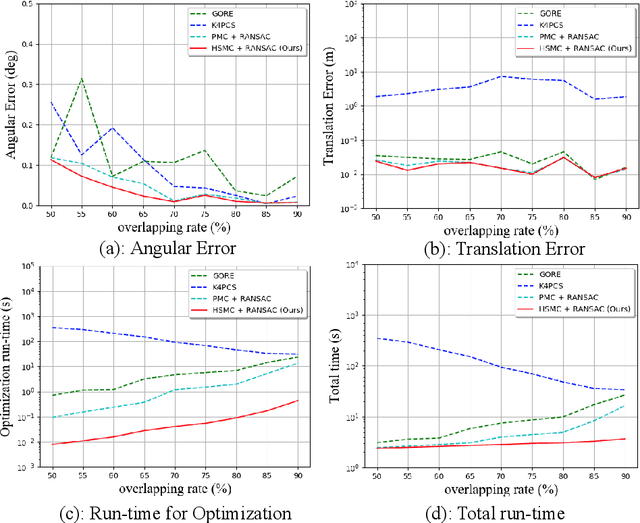
With current trends in sensors (cheaper, more volume of data) and applications (increasing affordability for new tasks, new ideas in what 3D data could be useful for); there is corresponding increasing interest in the ability to automatically, reliably, and cheaply, register together individual point clouds. The volume of data to handle, and still elusive need to have the registration occur fully reliably and fully automatically, mean there is a need to innovate further. One largely untapped area of innovation is that of exploiting the {\em semantic information} of the points in question. Points on a tree should match points on a tree, for example, and not points on car. Moreover, such a natural restriction is clearly human-like - a human would generally quickly eliminate candidate regions for matching based on semantics. Employing semantic information is not only efficient but natural. It is also timely - due to the recent advances in semantic classification capabilities. This paper advances this theme by demonstrating that state of the art registration techniques, in particular ones that rely on "preservation of length under rigid motion" as an underlying matching consistency constraint, can be augmented with semantic information. Semantic identity is of course also preserved under rigid-motion, but also under wider motions present in a scene. We demonstrate that not only the potential obstacle of cost of semantic segmentation, and the potential obstacle of the unreliability of semantic segmentation; are both no impediment to achieving both speed and accuracy in fully automatic registration of large scale point clouds.