 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Multi-Target Tracking in Dynamic Environments: Distributed Control Methods Within the Random Finite Set Framework
Jan 25, 2024



Tracking multiple targets in dynamic environments using distributed sensor networks is a challenging problem that has received significant attention in recent years. In such scenarios, the network of sensors must coordinate their actions to estimate the locations and trajectories of multiple targets accurately. Multi-sensor control methods can improve the performance of these networks by enabling efficient utilization of resources and enhancing the accuracy of the estimated target states. This paper proposes two novel multi-sensor control methods that utilize the Random Finite Set (RFS) framework to address this problem. Our methods improve computational tractability and enable fully distributed control, making them suitable for real-time applications.
Single Domain Generalization via Normalised Cross-correlation Based Convolutions
Jul 12, 2023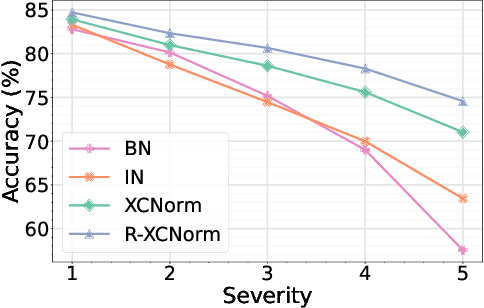
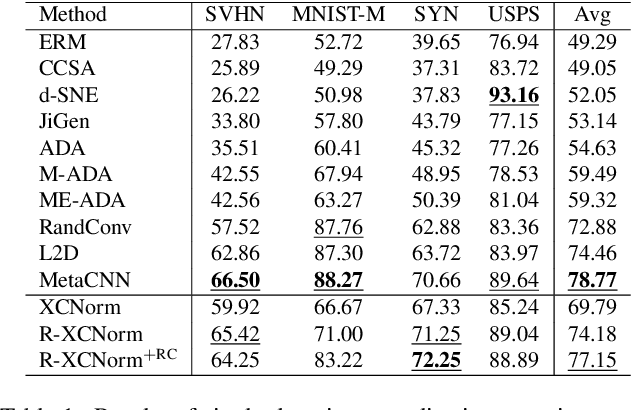

Deep learning techniques often perform poorly in the presence of domain shift, where the test data follows a different distribution than the training data. The most practically desirable approach to address this issue is Single Domain Generalization (S-DG), which aims to train robust models using data from a single source. Prior work on S-DG has primarily focused on using data augmentation techniques to generate diverse training data. In this paper, we explore an alternative approach by investigating the robustness of linear operators, such as convolution and dense layers commonly used in deep learning. We propose a novel operator called XCNorm that computes the normalized cross-correlation between weights and an input feature patch. This approach is invariant to both affine shifts and changes in energy within a local feature patch and eliminates the need for commonly used non-linear activation functions. We show that deep neural networks composed of this operator are robust to common semantic distribution shifts. Furthermore, our empirical results on single-domain generalization benchmarks demonstrate that our proposed technique performs comparably to the state-of-the-art methods.
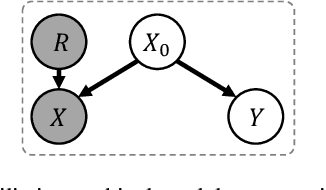
IT-RUDA: Information Theory Assisted Robust Unsupervised Domain Adaptation
Oct 24, 2022
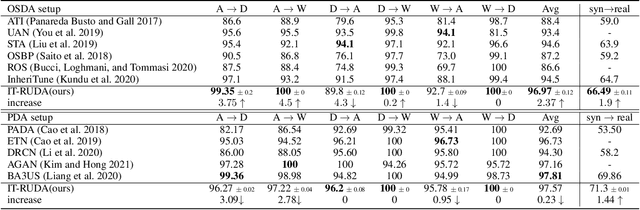

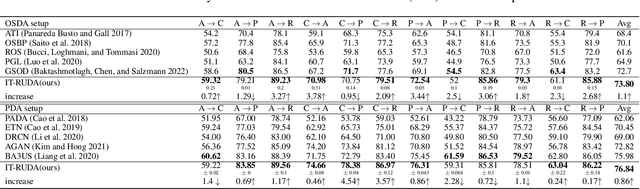
Distribution shift between train (source) and test (target) datasets is a common problem encountered in machine learning applications. One approach to resolve this issue is to use the Unsupervised Domain Adaptation (UDA) technique that carries out knowledge transfer from a label-rich source domain to an unlabeled target domain. Outliers that exist in either source or target datasets can introduce additional challenges when using UDA in practice. In this paper, $\alpha$-divergence is used as a measure to minimize the discrepancy between the source and target distributions while inheriting robustness, adjustable with a single parameter $\alpha$, as the prominent feature of this measure. Here, it is shown that the other well-known divergence-based UDA techniques can be derived as special cases of the proposed method. Furthermore, a theoretical upper bound is derived for the loss in the target domain in terms of the source loss and the initial $\alpha$-divergence between the two domains. The robustness of the proposed method is validated through testing on several benchmarked datasets in open-set and partial UDA setups where extra classes existing in target and source datasets are considered as outliers.
Interaction-Aware Labeled Multi-Bernoulli Filter
Apr 19, 2022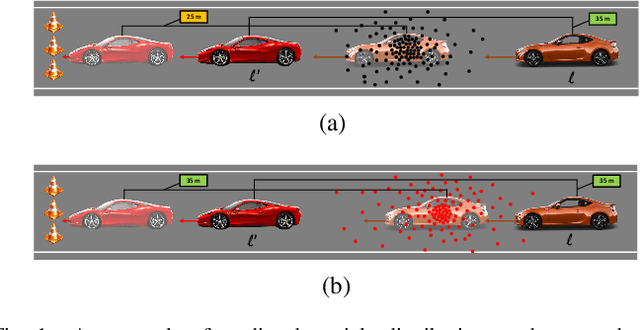
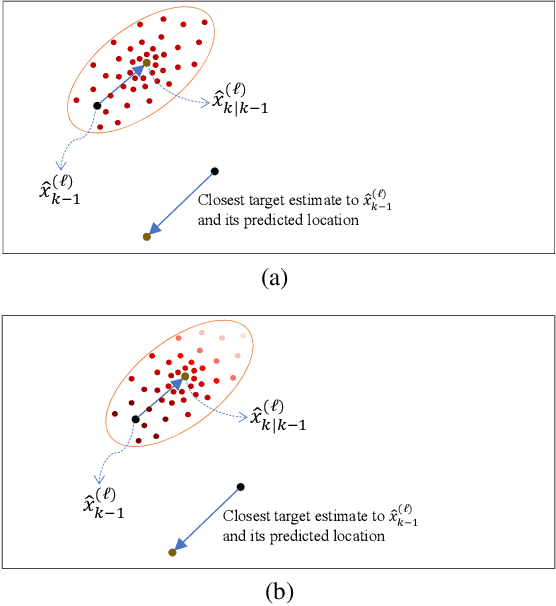
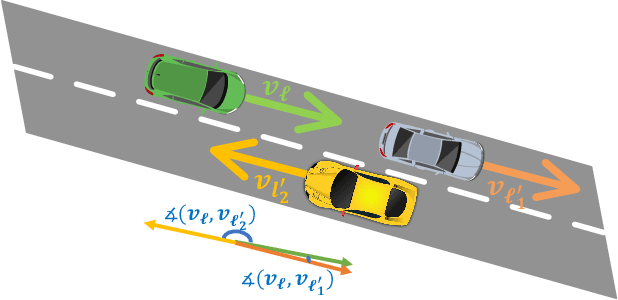
Tracking multiple objects through time is an important part of an intelligent transportation system. Random finite set (RFS)-based filters are one of the emerging techniques for tracking multiple objects. In multi-object tracking (MOT), a common assumption is that each object is moving independent of its surroundings. But in many real-world applications, target objects interact with one another and the environment. Such interactions, when considered for tracking, are usually modeled by an interactive motion model which is application specific. In this paper, we present a novel approach to incorporate target interactions within the prediction step of an RFS-based multi-target filter, i.e. labeled multi-Bernoulli (LMB) filter. The method has been developed for two practical applications of tracking a coordinated swarm and vehicles. The method has been tested for a complex vehicle tracking dataset and compared with the LMB filter through the OSPA and OSPA$^{(2)}$ metrics. The results demonstrate that the proposed interaction-aware method depicts considerable performance enhancement over the LMB filter in terms of the selected metrics.
ITSA: An Information-Theoretic Approach to Automatic Shortcut Avoidance and Domain Generalization in Stereo Matching Networks
Jan 06, 2022

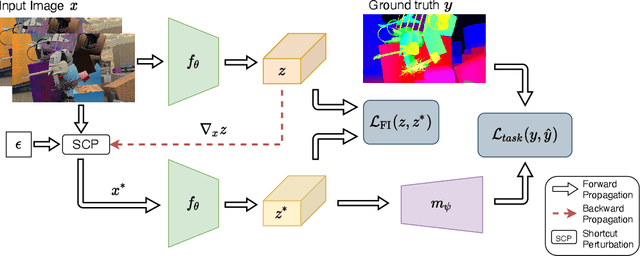
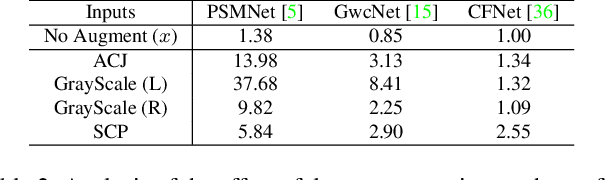
State-of-the-art stereo matching networks trained only on synthetic data often fail to generalize to more challenging real data domains. In this paper, we attempt to unfold an important factor that hinders the networks from generalizing across domains: through the lens of shortcut learning. We demonstrate that the learning of feature representations in stereo matching networks is heavily influenced by synthetic data artefacts (shortcut attributes). To mitigate this issue, we propose an Information-Theoretic Shortcut Avoidance~(ITSA) approach to automatically restrict shortcut-related information from being encoded into the feature representations. As a result, our proposed method learns robust and shortcut-invariant features by minimizing the sensitivity of latent features to input variations. To avoid the prohibitive computational cost of direct input sensitivity optimization, we propose an effective yet feasible algorithm to achieve robustness. We show that using this method, state-of-the-art stereo matching networks that are trained purely on synthetic data can effectively generalize to challenging and previously unseen real data scenarios. Importantly, the proposed method enhances the robustness of the synthetic trained networks to the point that they outperform their fine-tuned counterparts (on real data) for challenging out-of-domain stereo datasets.
Anomaly Detection of Defect using Energy of Point Pattern Features within Random Finite Set Framework
Aug 27, 2021
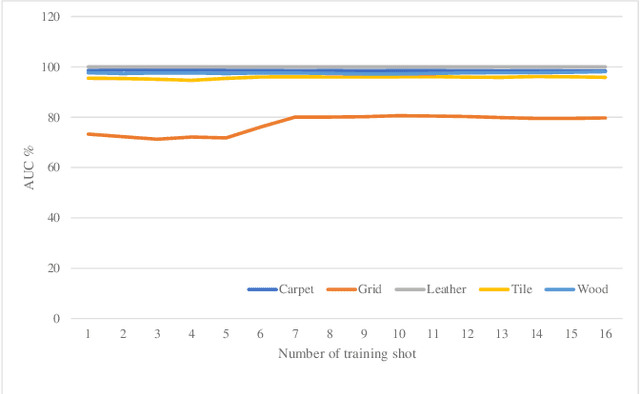
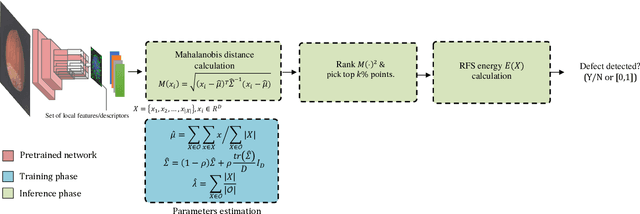

In this paper, we propose an efficient approach for industrial defect detection that is modeled based on anomaly detection using point pattern data. Most recent works use \textit{global features} for feature extraction to summarize image content. However, global features are not robust against lighting and viewpoint changes and do not describe the image's geometrical information to be fully utilized in the manufacturing industry. To the best of our knowledge, we are the first to propose using transfer learning of local/point pattern features to overcome these limitations and capture geometrical information of the image regions. We model these local/point pattern features as a random finite set (RFS). In addition we propose RFS energy, in contrast to RFS likelihood as anomaly score. The similarity distribution of point pattern features of the normal sample has been modeled as a multivariate Gaussian. Parameters learning of the proposed RFS energy does not require any heavy computation. We evaluate the proposed approach on the MVTec AD dataset, a multi-object defect detection dataset. Experimental results show the outstanding performance of our proposed approach compared to the state-of-the-art methods, and the proposed RFS energy outperforms the state-of-the-art in the few shot learning settings.
Robust Pooling through the Data Mode
Jun 21, 2021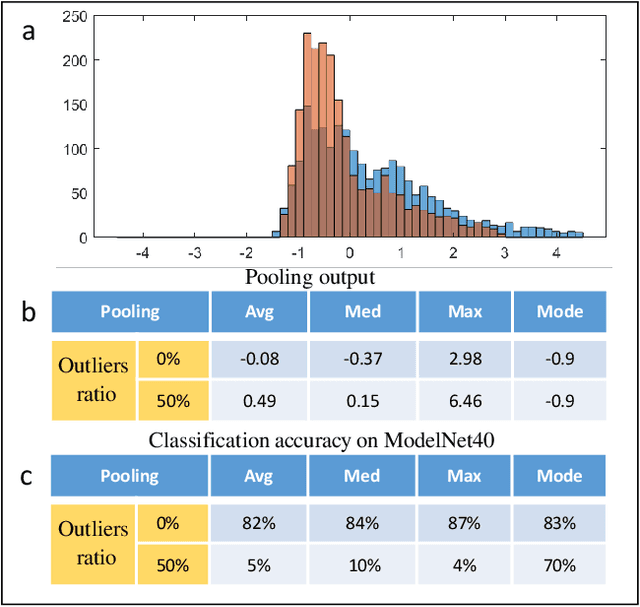
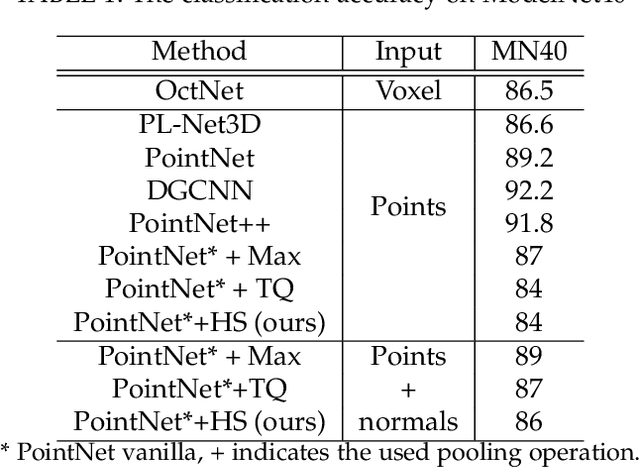
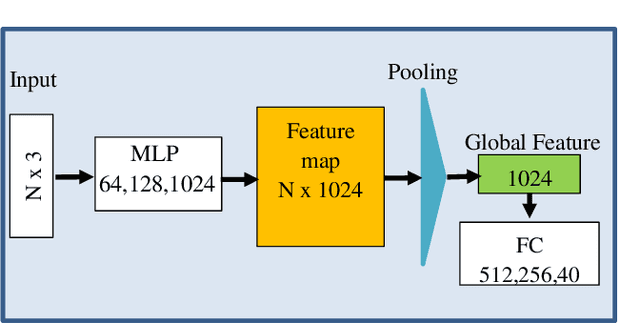
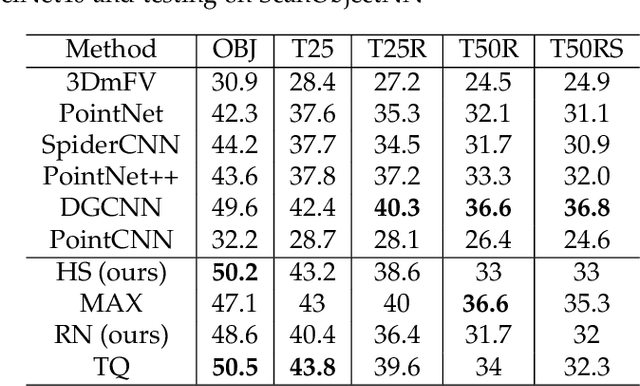
The task of learning from point cloud data is always challenging due to the often occurrence of noise and outliers in the data. Such data inaccuracies can significantly influence the performance of state-of-the-art deep learning networks and their ability to classify or segment objects. While there are some robust deep learning approaches, they are computationally too expensive for real-time applications. This paper proposes a deep learning solution that includes a novel robust pooling layer which greatly enhances network robustness and performs significantly faster than state-of-the-art approaches. The proposed pooling layer looks for data a mode/cluster using two methods, RANSAC, and histogram, as clusters are indicative of models. We tested the pooling layer into frameworks such as Point-based and graph-based neural networks, and the tests showed enhanced robustness as compared to robust state-of-the-art methods.
Evaluation of Point Pattern Features for Anomaly Detection of Defect within Random Finite Set Framework
Feb 03, 2021


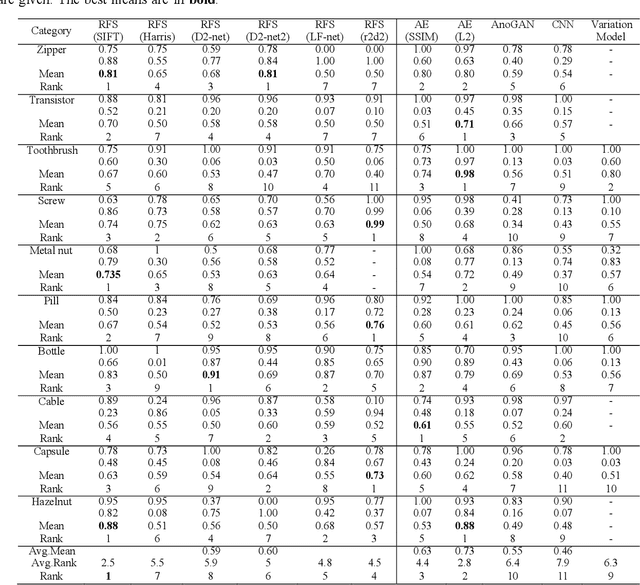
Defect detection in the manufacturing industry is of utmost importance for product quality inspection. Recently, optical defect detection has been investigated as an anomaly detection using different deep learning methods. However, the recent works do not explore the use of point pattern features, such as SIFT for anomaly detection using the recently developed set-based methods. In this paper, we present an evaluation of different point pattern feature detectors and descriptors for defect detection application. The evaluation is performed within the random finite set framework. Handcrafted point pattern features, such as SIFT as well as deep features are used in this evaluation. Random finite set-based defect detection is compared with state-of-the-arts anomaly detection methods. The results show that using point pattern features, such as SIFT as data points for random finite set-based anomaly detection achieves the most consistent defect detection accuracy on the MVTec-AD dataset.
Long Range Stereo Matching by Learning Depth and Disparity
Sep 10, 2020
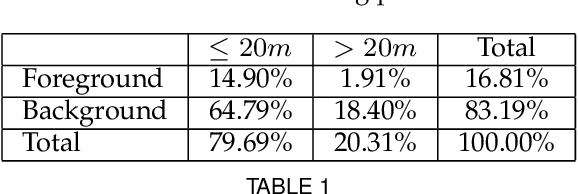
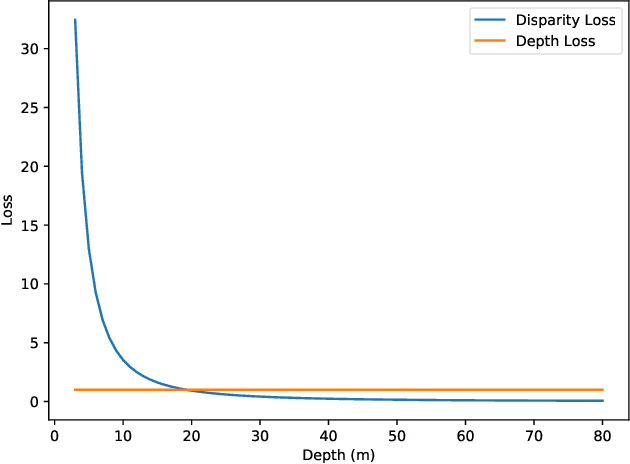
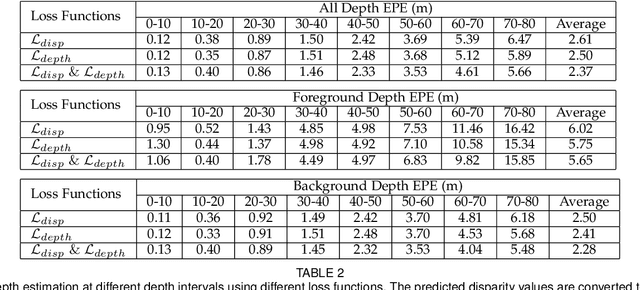
Stereo matching generally involves computation of pixel correspondences and estimation of disparities between rectified image pairs. In many applications including simultaneous localization and mapping (SLAM) and 3D object detection, disparity is particularly needed to calculate depth values. While many recent stereo matching solutions focus on delivering a neural network model that provides better matching and aggregation, little attention has been given to the problems of having bias in training data or selected loss function. As the performance of supervised learning networks largely depends on the properties of training data and its loss function, we will show that by simply allowing the neural network to be aware of a bias, its performance improves. We also demonstrate the existence of bias in both the popular KITTI 2015 stereo dataset and the commonly used smooth L1 loss function. Our solution has two components: The loss is depth-based and has two different parts for foreground and background pixels. The combination of those allows the stereo matching network to evenly focus on all pixels and mitigate the potential of over-fitting caused by the bias. The efficacy of our approach is demonstrated by an extensive set of experiments and benchmarking those against the state-of-the-art results. In particular, our results show that the proposed loss function is very effective for the estimation of depth and disparity for objects at distances beyond 50 meters, which represents the frontier for the emerging applications of the passive vision in building autonomous navigation systems.
Robust Object Classification Approach using Spherical Harmonics
Sep 02, 2020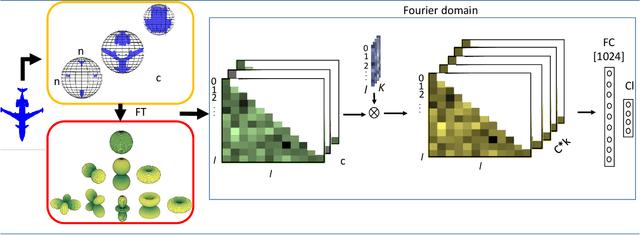
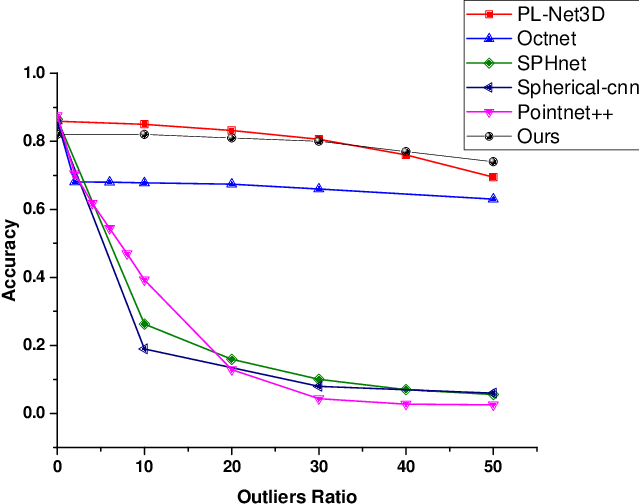
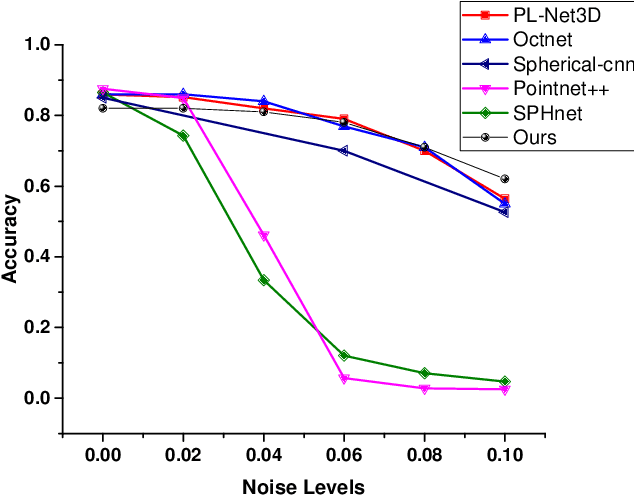
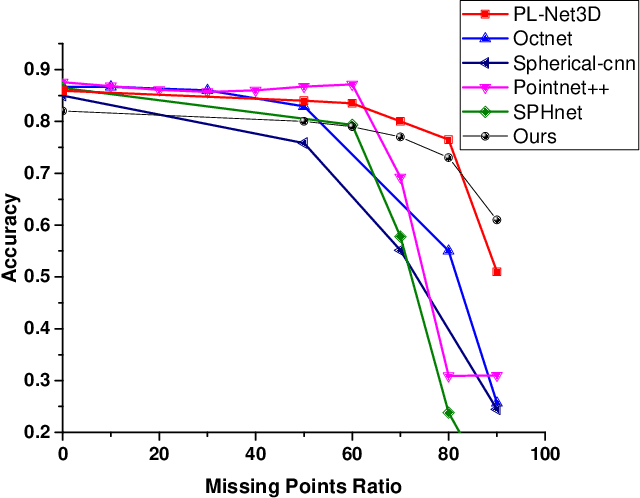
In this paper, we present a robust spherical harmonics approach for the classification of point cloud-based objects. Spherical harmonics have been used for classification over the years, with several frameworks existing in the literature. These approaches use variety of spherical harmonics based descriptors to classify objects. We first investigated these frameworks robustness against data augmentation, such as outliers and noise, as it has not been studied before. Then we propose a spherical convolution neural network framework for robust object classification. The proposed framework uses the voxel grid of concentric spheres to learn features over the unit ball. Our proposed model learn features that are less sensitive to data augmentation due to the selected sampling strategy and the designed convolution operation. We tested our proposed model against several types of data augmentation, such as noise and outliers. Our results show that the proposed model outperforms the state of art networks in terms of robustness to data augmentation.