 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Online Test-time Adaptation with Feature-Weight Cosine Alignment
May 12, 2024Online Test-Time Adaptation (OTTA) has emerged as an effective strategy to handle distributional shifts, allowing on-the-fly adaptation of pre-trained models to new target domains during inference, without the need for source data. We uncovered that the widely studied entropy minimization (EM) method for OTTA, suffers from noisy gradients due to ambiguity near decision boundaries and incorrect low-entropy predictions. To overcome these limitations, this paper introduces a novel cosine alignment optimization approach with a dual-objective loss function that refines the precision of class predictions and adaptability to novel domains. Specifically, our method optimizes the cosine similarity between feature vectors and class weight vectors, enhancing the precision of class predictions and the model's adaptability to novel domains. Our method outperforms state-of-the-art techniques and sets a new benchmark in multiple datasets, including CIFAR-10-C, CIFAR-100-C, ImageNet-C, Office-Home, and DomainNet datasets, demonstrating high accuracy and robustness against diverse corruptions and domain shifts.
Single Domain Generalization via Normalised Cross-correlation Based Convolutions
Jul 12, 2023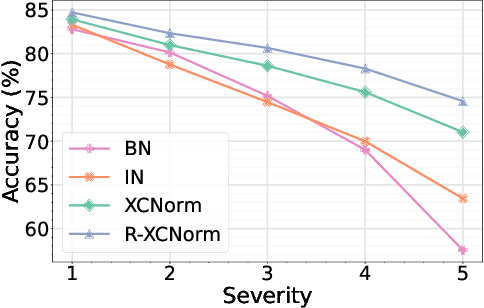
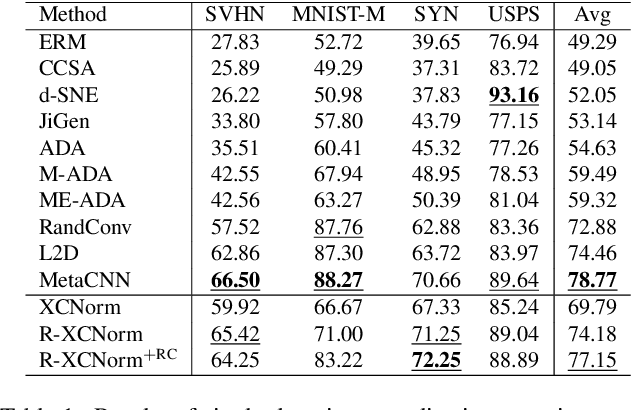
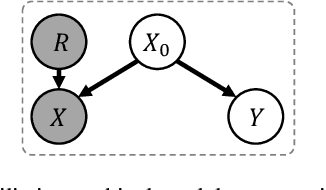

Deep learning techniques often perform poorly in the presence of domain shift, where the test data follows a different distribution than the training data. The most practically desirable approach to address this issue is Single Domain Generalization (S-DG), which aims to train robust models using data from a single source. Prior work on S-DG has primarily focused on using data augmentation techniques to generate diverse training data. In this paper, we explore an alternative approach by investigating the robustness of linear operators, such as convolution and dense layers commonly used in deep learning. We propose a novel operator called XCNorm that computes the normalized cross-correlation between weights and an input feature patch. This approach is invariant to both affine shifts and changes in energy within a local feature patch and eliminates the need for commonly used non-linear activation functions. We show that deep neural networks composed of this operator are robust to common semantic distribution shifts. Furthermore, our empirical results on single-domain generalization benchmarks demonstrate that our proposed technique performs comparably to the state-of-the-art methods.
ITSA: An Information-Theoretic Approach to Automatic Shortcut Avoidance and Domain Generalization in Stereo Matching Networks
Jan 06, 2022

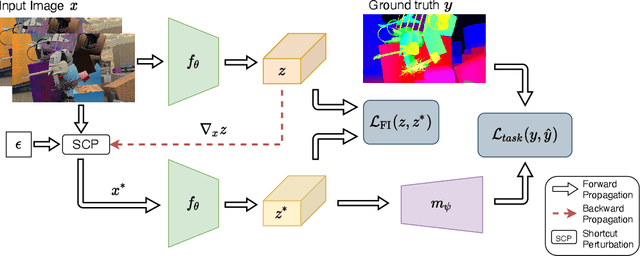
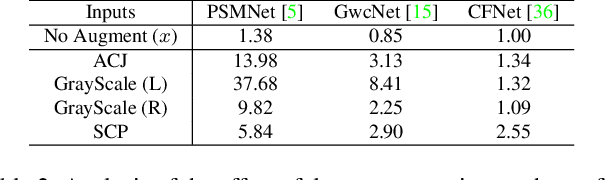
State-of-the-art stereo matching networks trained only on synthetic data often fail to generalize to more challenging real data domains. In this paper, we attempt to unfold an important factor that hinders the networks from generalizing across domains: through the lens of shortcut learning. We demonstrate that the learning of feature representations in stereo matching networks is heavily influenced by synthetic data artefacts (shortcut attributes). To mitigate this issue, we propose an Information-Theoretic Shortcut Avoidance~(ITSA) approach to automatically restrict shortcut-related information from being encoded into the feature representations. As a result, our proposed method learns robust and shortcut-invariant features by minimizing the sensitivity of latent features to input variations. To avoid the prohibitive computational cost of direct input sensitivity optimization, we propose an effective yet feasible algorithm to achieve robustness. We show that using this method, state-of-the-art stereo matching networks that are trained purely on synthetic data can effectively generalize to challenging and previously unseen real data scenarios. Importantly, the proposed method enhances the robustness of the synthetic trained networks to the point that they outperform their fine-tuned counterparts (on real data) for challenging out-of-domain stereo datasets.
Achieving Domain Robustness in Stereo Matching Networks by Removing Shortcut Learning
Jun 15, 2021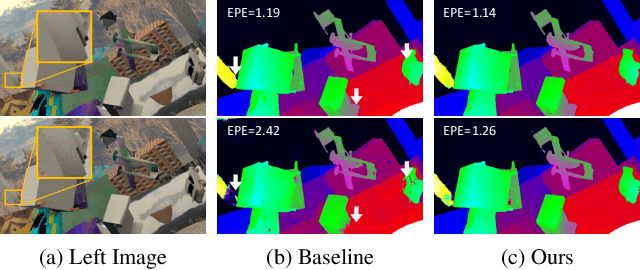


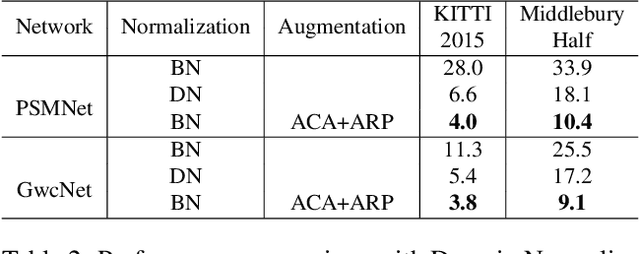
Learning-based stereo matching and depth estimation networks currently excel on public benchmarks with impressive results. However, state-of-the-art networks often fail to generalize from synthetic imagery to more challenging real data domains. This paper is an attempt to uncover hidden secrets of achieving domain robustness and in particular, discovering the important ingredients of generalization success of stereo matching networks by analyzing the effect of synthetic image learning on real data performance. We provide evidence that demonstrates that learning of features in the synthetic domain by a stereo matching network is heavily influenced by two "shortcuts" presented in the synthetic data: (1) identical local statistics (RGB colour features) between matching pixels in the synthetic stereo images and (2) lack of realism in synthetic textures on 3D objects simulated in game engines. We will show that by removing such shortcuts, we can achieve domain robustness in the state-of-the-art stereo matching frameworks and produce a remarkable performance on multiple realistic datasets, despite the fact that the networks were trained on synthetic data, only. Our experimental results point to the fact that eliminating shortcuts from the synthetic data is key to achieve domain-invariant generalization between synthetic and real data domains.
Long Range Stereo Matching by Learning Depth and Disparity
Sep 10, 2020
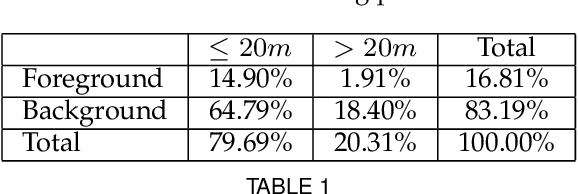
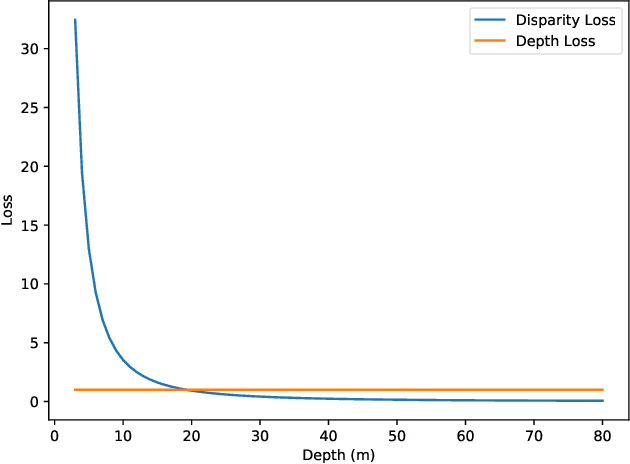
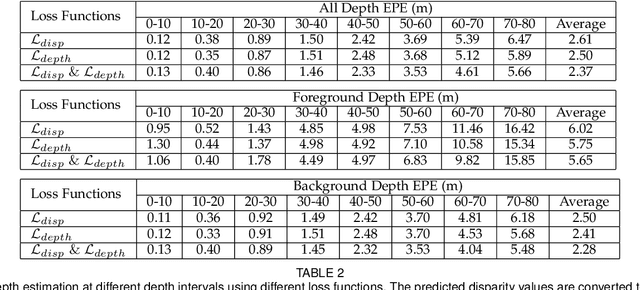
Stereo matching generally involves computation of pixel correspondences and estimation of disparities between rectified image pairs. In many applications including simultaneous localization and mapping (SLAM) and 3D object detection, disparity is particularly needed to calculate depth values. While many recent stereo matching solutions focus on delivering a neural network model that provides better matching and aggregation, little attention has been given to the problems of having bias in training data or selected loss function. As the performance of supervised learning networks largely depends on the properties of training data and its loss function, we will show that by simply allowing the neural network to be aware of a bias, its performance improves. We also demonstrate the existence of bias in both the popular KITTI 2015 stereo dataset and the commonly used smooth L1 loss function. Our solution has two components: The loss is depth-based and has two different parts for foreground and background pixels. The combination of those allows the stereo matching network to evenly focus on all pixels and mitigate the potential of over-fitting caused by the bias. The efficacy of our approach is demonstrated by an extensive set of experiments and benchmarking those against the state-of-the-art results. In particular, our results show that the proposed loss function is very effective for the estimation of depth and disparity for objects at distances beyond 50 meters, which represents the frontier for the emerging applications of the passive vision in building autonomous navigation systems.