 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Online Test-time Adaptation with Feature-Weight Cosine Alignment
May 12, 2024Online Test-Time Adaptation (OTTA) has emerged as an effective strategy to handle distributional shifts, allowing on-the-fly adaptation of pre-trained models to new target domains during inference, without the need for source data. We uncovered that the widely studied entropy minimization (EM) method for OTTA, suffers from noisy gradients due to ambiguity near decision boundaries and incorrect low-entropy predictions. To overcome these limitations, this paper introduces a novel cosine alignment optimization approach with a dual-objective loss function that refines the precision of class predictions and adaptability to novel domains. Specifically, our method optimizes the cosine similarity between feature vectors and class weight vectors, enhancing the precision of class predictions and the model's adaptability to novel domains. Our method outperforms state-of-the-art techniques and sets a new benchmark in multiple datasets, including CIFAR-10-C, CIFAR-100-C, ImageNet-C, Office-Home, and DomainNet datasets, demonstrating high accuracy and robustness against diverse corruptions and domain shifts.
Domain Generalization by Learning from Privileged Medical Imaging Information
Nov 10, 2023



Learning the ability to generalize knowledge between similar contexts is particularly important in medical imaging as data distributions can shift substantially from one hospital to another, or even from one machine to another. To strengthen generalization, most state-of-the-art techniques inject knowledge of the data distribution shifts by enforcing constraints on learned features or regularizing parameters. We offer an alternative approach: Learning from Privileged Medical Imaging Information (LPMII). We show that using some privileged information such as tumor shape or location leads to stronger domain generalization ability than current state-of-the-art techniques. This paper demonstrates that by using privileged information to predict the severity of intra-layer retinal fluid in optical coherence tomography scans, the classification accuracy of a deep learning model operating on out-of-distribution data improves from $0.911$ to $0.934$. This paper provides a strong starting point for using privileged information in other medical problems requiring generalization.
Single Domain Generalization via Normalised Cross-correlation Based Convolutions
Jul 12, 2023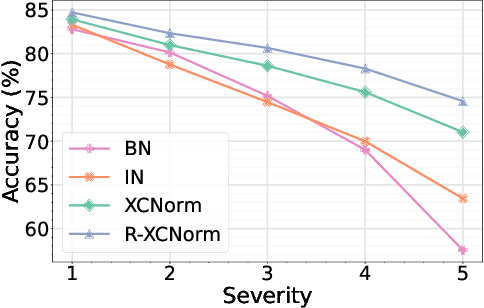
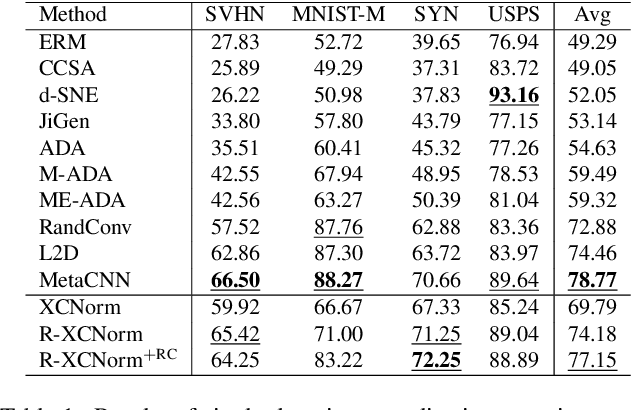
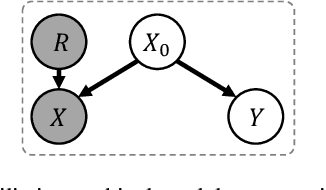

Deep learning techniques often perform poorly in the presence of domain shift, where the test data follows a different distribution than the training data. The most practically desirable approach to address this issue is Single Domain Generalization (S-DG), which aims to train robust models using data from a single source. Prior work on S-DG has primarily focused on using data augmentation techniques to generate diverse training data. In this paper, we explore an alternative approach by investigating the robustness of linear operators, such as convolution and dense layers commonly used in deep learning. We propose a novel operator called XCNorm that computes the normalized cross-correlation between weights and an input feature patch. This approach is invariant to both affine shifts and changes in energy within a local feature patch and eliminates the need for commonly used non-linear activation functions. We show that deep neural networks composed of this operator are robust to common semantic distribution shifts. Furthermore, our empirical results on single-domain generalization benchmarks demonstrate that our proposed technique performs comparably to the state-of-the-art methods.
IT-RUDA: Information Theory Assisted Robust Unsupervised Domain Adaptation
Oct 24, 2022
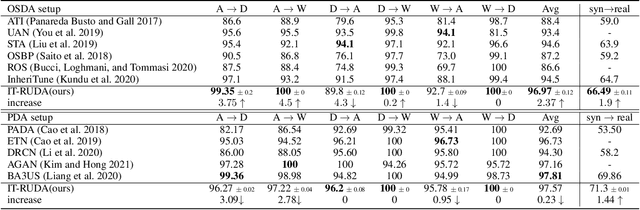

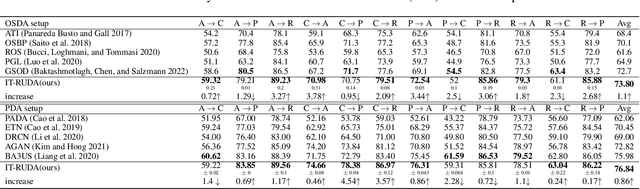
Distribution shift between train (source) and test (target) datasets is a common problem encountered in machine learning applications. One approach to resolve this issue is to use the Unsupervised Domain Adaptation (UDA) technique that carries out knowledge transfer from a label-rich source domain to an unlabeled target domain. Outliers that exist in either source or target datasets can introduce additional challenges when using UDA in practice. In this paper, $\alpha$-divergence is used as a measure to minimize the discrepancy between the source and target distributions while inheriting robustness, adjustable with a single parameter $\alpha$, as the prominent feature of this measure. Here, it is shown that the other well-known divergence-based UDA techniques can be derived as special cases of the proposed method. Furthermore, a theoretical upper bound is derived for the loss in the target domain in terms of the source loss and the initial $\alpha$-divergence between the two domains. The robustness of the proposed method is validated through testing on several benchmarked datasets in open-set and partial UDA setups where extra classes existing in target and source datasets are considered as outliers.
ITSA: An Information-Theoretic Approach to Automatic Shortcut Avoidance and Domain Generalization in Stereo Matching Networks
Jan 06, 2022

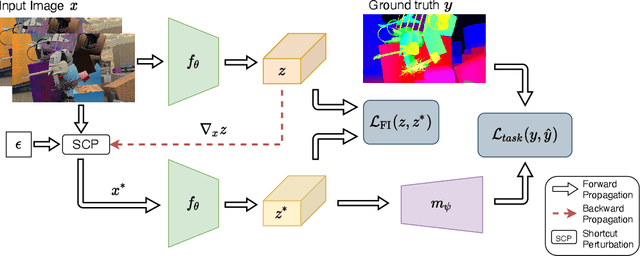
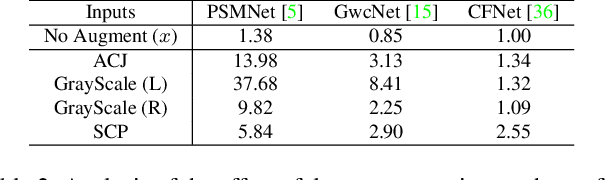
State-of-the-art stereo matching networks trained only on synthetic data often fail to generalize to more challenging real data domains. In this paper, we attempt to unfold an important factor that hinders the networks from generalizing across domains: through the lens of shortcut learning. We demonstrate that the learning of feature representations in stereo matching networks is heavily influenced by synthetic data artefacts (shortcut attributes). To mitigate this issue, we propose an Information-Theoretic Shortcut Avoidance~(ITSA) approach to automatically restrict shortcut-related information from being encoded into the feature representations. As a result, our proposed method learns robust and shortcut-invariant features by minimizing the sensitivity of latent features to input variations. To avoid the prohibitive computational cost of direct input sensitivity optimization, we propose an effective yet feasible algorithm to achieve robustness. We show that using this method, state-of-the-art stereo matching networks that are trained purely on synthetic data can effectively generalize to challenging and previously unseen real data scenarios. Importantly, the proposed method enhances the robustness of the synthetic trained networks to the point that they outperform their fine-tuned counterparts (on real data) for challenging out-of-domain stereo datasets.
Maximum Consensus by Weighted Influences of Monotone Boolean Functions
Dec 10, 2021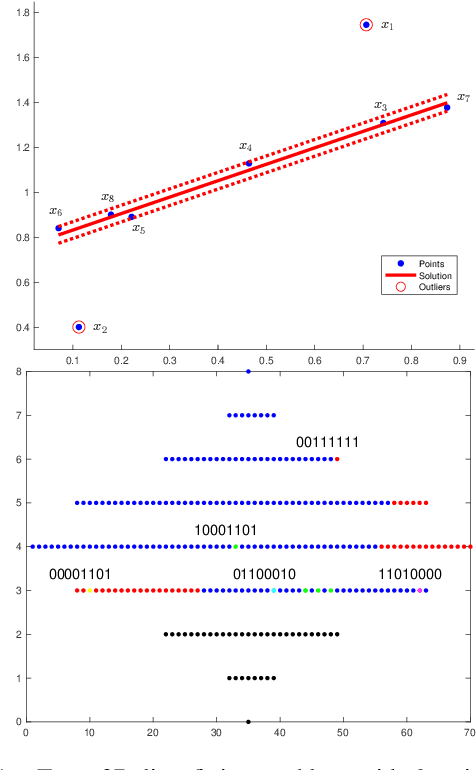
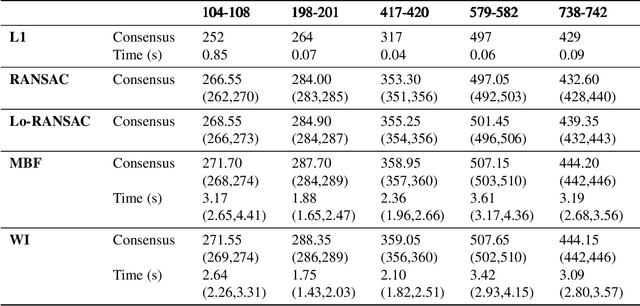
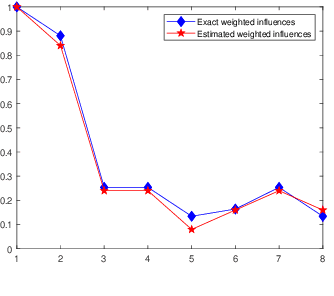
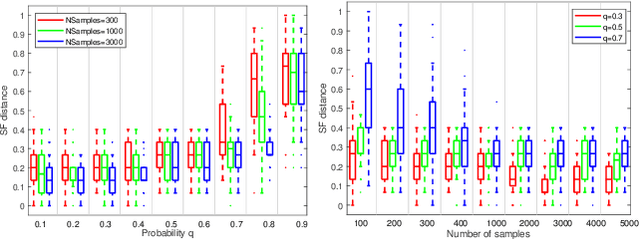
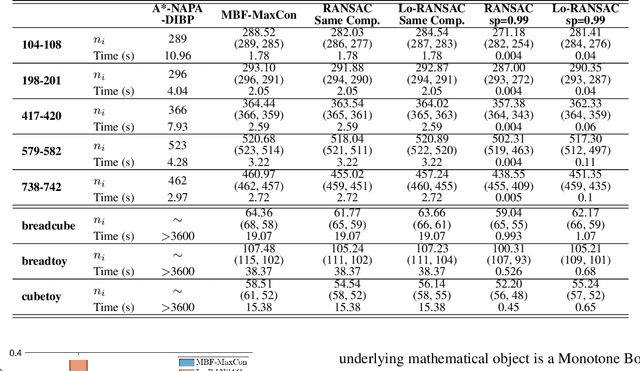
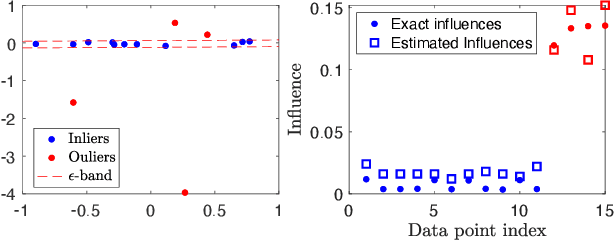
Robust model fitting is a fundamental problem in computer vision: used to pre-process raw data in the presence of outliers. Maximisation of Consensus (MaxCon) is one of the most popular robust criteria and widely used. Recently (Tennakoon et al. CVPR2021), a connection has been made between MaxCon and estimation of influences of a Monotone Boolean function. Equipping the Boolean cube with different measures and adopting different sampling strategies (two sides of the same coin) can have differing effects: which leads to the current study. This paper studies the concept of weighted influences for solving MaxCon. In particular, we study endowing the Boolean cube with the Bernoulli measure and performing biased (as opposed to uniform) sampling. Theoretically, we prove the weighted influences, under this measure, of points belonging to larger structures are smaller than those of points belonging to smaller structures in general. We also consider another "natural" family of sampling/weighting strategies, sampling with uniform measure concentrated on a particular (Hamming) level of the cube. Based on weighted sampling, we modify the algorithm of Tennakoon et al., and test on both synthetic and real datasets. This paper is not promoting a new approach per se, but rather studying the issue of weighted sampling. Accordingly, we are not claiming to have produced a superior algorithm: rather we show some modest gains of Bernoulli sampling, and we illuminate some of the interactions between structure in data and weighted sampling.
Robust Pooling through the Data Mode
Jun 21, 2021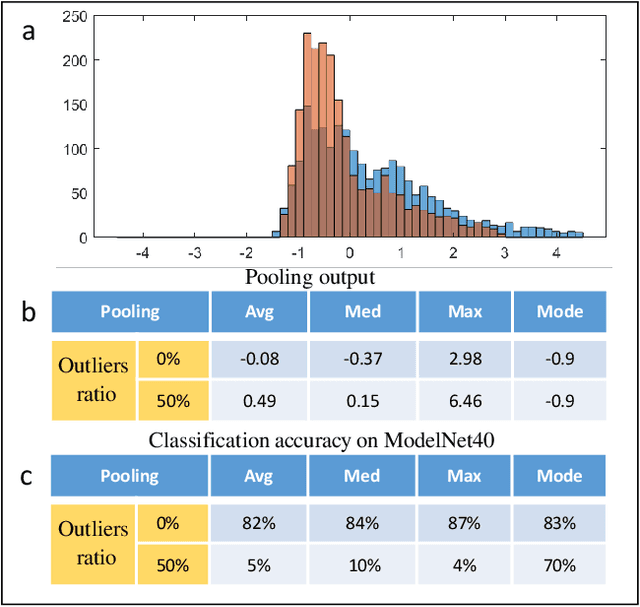
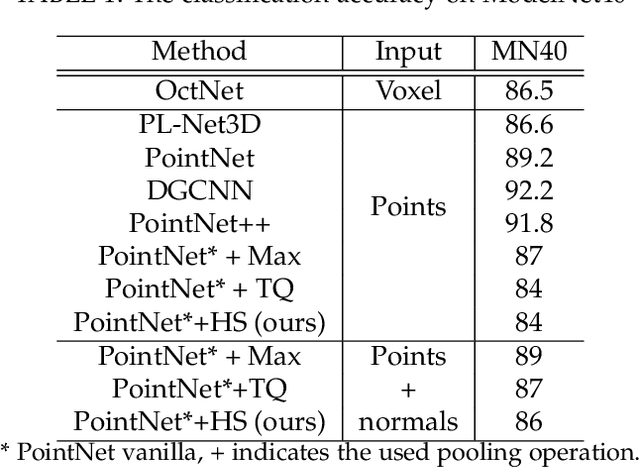
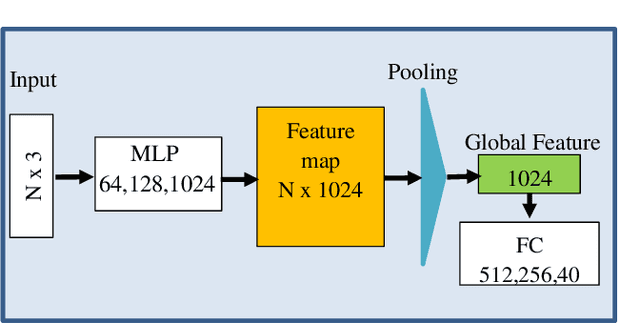
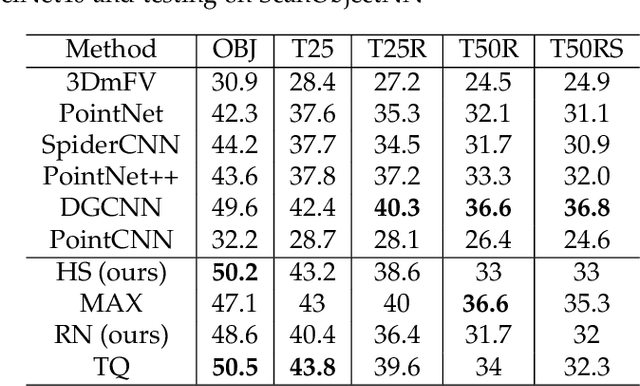
The task of learning from point cloud data is always challenging due to the often occurrence of noise and outliers in the data. Such data inaccuracies can significantly influence the performance of state-of-the-art deep learning networks and their ability to classify or segment objects. While there are some robust deep learning approaches, they are computationally too expensive for real-time applications. This paper proposes a deep learning solution that includes a novel robust pooling layer which greatly enhances network robustness and performs significantly faster than state-of-the-art approaches. The proposed pooling layer looks for data a mode/cluster using two methods, RANSAC, and histogram, as clusters are indicative of models. We tested the pooling layer into frameworks such as Point-based and graph-based neural networks, and the tests showed enhanced robustness as compared to robust state-of-the-art methods.
Achieving Domain Robustness in Stereo Matching Networks by Removing Shortcut Learning
Jun 15, 2021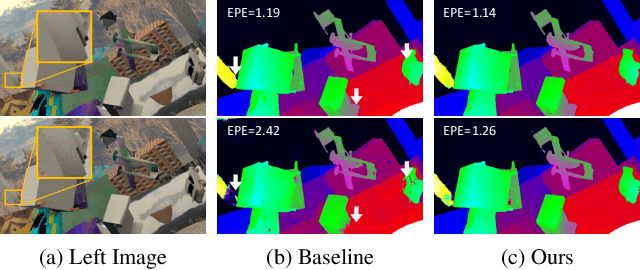


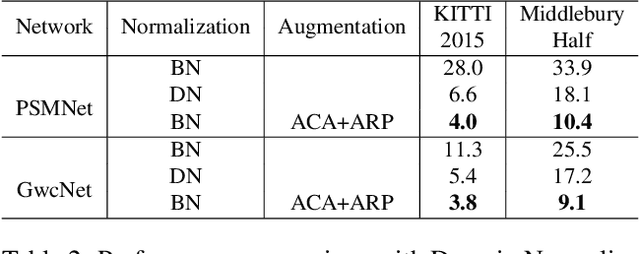
Learning-based stereo matching and depth estimation networks currently excel on public benchmarks with impressive results. However, state-of-the-art networks often fail to generalize from synthetic imagery to more challenging real data domains. This paper is an attempt to uncover hidden secrets of achieving domain robustness and in particular, discovering the important ingredients of generalization success of stereo matching networks by analyzing the effect of synthetic image learning on real data performance. We provide evidence that demonstrates that learning of features in the synthetic domain by a stereo matching network is heavily influenced by two "shortcuts" presented in the synthetic data: (1) identical local statistics (RGB colour features) between matching pixels in the synthetic stereo images and (2) lack of realism in synthetic textures on 3D objects simulated in game engines. We will show that by removing such shortcuts, we can achieve domain robustness in the state-of-the-art stereo matching frameworks and produce a remarkable performance on multiple realistic datasets, despite the fact that the networks were trained on synthetic data, only. Our experimental results point to the fact that eliminating shortcuts from the synthetic data is key to achieve domain-invariant generalization between synthetic and real data domains.
Consensus Maximisation Using Influences of Monotone Boolean Functions
Mar 06, 2021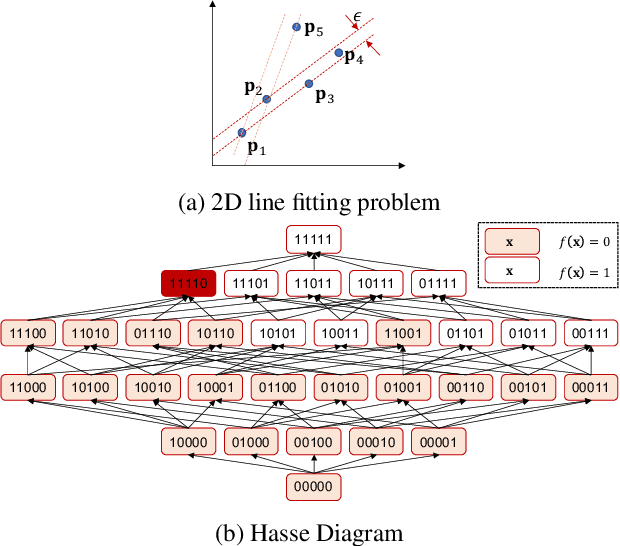
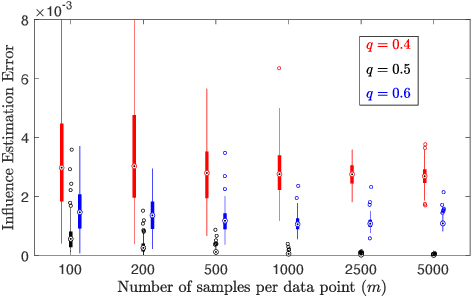
Consensus maximisation (MaxCon), which is widely used for robust fitting in computer vision, aims to find the largest subset of data that fits the model within some tolerance level. In this paper, we outline the connection between MaxCon problem and the abstract problem of finding the maximum upper zero of a Monotone Boolean Function (MBF) defined over the Boolean Cube. Then, we link the concept of influences (in a MBF) to the concept of outlier (in MaxCon) and show that influences of points belonging to the largest structure in data would generally be smaller under certain conditions. Based on this observation, we present an iterative algorithm to perform consensus maximisation. Results for both synthetic and real visual data experiments show that the MBF based algorithm is capable of generating a near optimal solution relatively quickly. This is particularly important where there are large number of outliers (gross or pseudo) in the observed data.
Rotation Averaging with Attention Graph Neural Networks
Oct 14, 2020

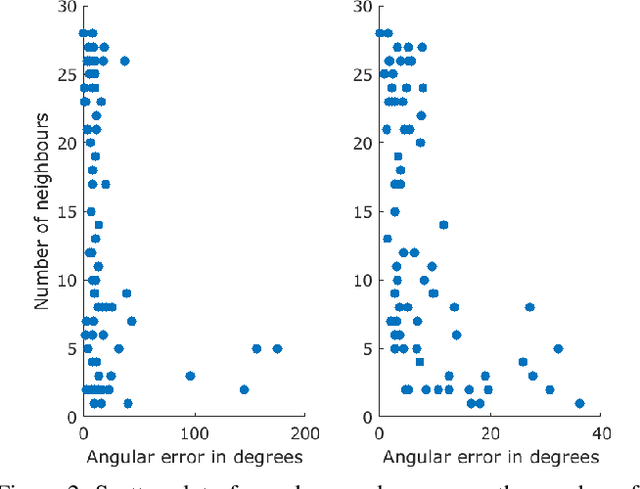

In this paper we propose a real-time and robust solution to large-scale multiple rotation averaging. Until recently, Multiple rotation averaging problem had been solved using conventional iterative optimization algorithms. Such methods employed robust cost functions that were chosen based on assumptions made about the sensor noise and outlier distribution. In practice, these assumptions do not always fit real datasets very well. A recent work showed that the noise distribution could be learnt using a graph neural network. This solution required a second network for outlier detection and removal as the averaging network was sensitive to a poor initialization. In this paper we propose a single-stage graph neural network that can robustly perform rotation averaging in the presence of noise and outliers. Our method uses all observations, suppressing outliers effects through the use of weighted averaging and an attention mechanism within the network design. The result is a network that is faster, more robust and can be trained with less samples than the previous neural approach, ultimately outperforming conventional iterative algorithms in accuracy and in inference times.