 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Foundation Models for Domain Generalisable Cross-View Localisation in Planetary Ground-Aerial Robotic Teams
Jan 14, 2026Accurate localisation in planetary robotics enables the advanced autonomy required to support the increased scale and scope of future missions. The successes of the Ingenuity helicopter and multiple planetary orbiters lay the groundwork for future missions that use ground-aerial robotic teams. In this paper, we consider rovers using machine learning to localise themselves in a local aerial map using limited field-of-view monocular ground-view RGB images as input. A key consideration for machine learning methods is that real space data with ground-truth position labels suitable for training is scarce. In this work, we propose a novel method of localising rovers in an aerial map using cross-view-localising dual-encoder deep neural networks. We leverage semantic segmentation with vision foundation models and high volume synthetic data to bridge the domain gap to real images. We also contribute a new cross-view dataset of real-world rover trajectories with corresponding ground-truth localisation data captured in a planetary analogue facility, plus a high volume dataset of analogous synthetic image pairs. Using particle filters for state estimation with the cross-view networks allows accurate position estimation over simple and complex trajectories based on sequences of ground-view images.
SceneEdited: A City-Scale Benchmark for 3D HD Map Updating via Image-Guided Change Detection
Nov 19, 2025



Accurate, up-to-date High-Definition (HD) maps are critical for urban planning, infrastructure monitoring, and autonomous navigation. However, these maps quickly become outdated as environments evolve, creating a need for robust methods that not only detect changes but also incorporate them into updated 3D representations. While change detection techniques have advanced significantly, there remains a clear gap between detecting changes and actually updating 3D maps, particularly when relying on 2D image-based change detection. To address this gap, we introduce SceneEdited, the first city-scale dataset explicitly designed to support research on HD map maintenance through 3D point cloud updating. SceneEdited contains over 800 up-to-date scenes covering 73 km of driving and approximate 3 $\text{km}^2$ of urban area, with more than 23,000 synthesized object changes created both manually and automatically across 2000+ out-of-date versions, simulating realistic urban modifications such as missing roadside infrastructure, buildings, overpasses, and utility poles. Each scene includes calibrated RGB images, LiDAR scans, and detailed change masks for training and evaluation. We also provide baseline methods using a foundational image-based structure-from-motion pipeline for updating outdated scenes, as well as a comprehensive toolkit supporting scalability, trackability, and portability for future dataset expansion and unification of out-of-date object annotations. Both the dataset and the toolkit are publicly available at https://github.com/ChadLin9596/ScenePoint-ETK, establising a standardized benchmark for 3D map updating research.
Quantum-enhanced Computer Vision: Going Beyond Classical Algorithms
Oct 08, 2025Quantum-enhanced Computer Vision (QeCV) is a new research field at the intersection of computer vision, optimisation theory, machine learning and quantum computing. It has high potential to transform how visual signals are processed and interpreted with the help of quantum computing that leverages quantum-mechanical effects in computations inaccessible to classical (i.e. non-quantum) computers. In scenarios where existing non-quantum methods cannot find a solution in a reasonable time or compute only approximate solutions, quantum computers can provide, among others, advantages in terms of better time scalability for multiple problem classes. Parametrised quantum circuits can also become, in the long term, a considerable alternative to classical neural networks in computer vision. However, specialised and fundamentally new algorithms must be developed to enable compatibility with quantum hardware and unveil the potential of quantum computational paradigms in computer vision. This survey contributes to the existing literature on QeCV with a holistic review of this research field. It is designed as a quantum computing reference for the computer vision community, targeting computer vision students, scientists and readers with related backgrounds who want to familiarise themselves with QeCV. We provide a comprehensive introduction to QeCV, its specifics, and methodologies for formulations compatible with quantum hardware and QeCV methods, leveraging two main quantum computational paradigms, i.e. gate-based quantum computing and quantum annealing. We elaborate on the operational principles of quantum computers and the available tools to access, program and simulate them in the context of QeCV. Finally, we review existing quantum computing tools and learning materials and discuss aspects related to publishing and reviewing QeCV papers, open challenges and potential social implications.
Finding Outliers in a Haystack: Anomaly Detection for Large Pointcloud Scenes
Aug 25, 2025LiDAR scanning in outdoor scenes acquires accurate distance measurements over wide areas, producing large-scale point clouds. Application examples for this data include robotics, automotive vehicles, and land surveillance. During such applications, outlier objects from outside the training data will inevitably appear. Our research contributes a novel approach to open-set segmentation, leveraging the learnings of object defect-detection research. We also draw on the Mamba architecture's strong performance in utilising long-range dependencies and scalability to large data. Combining both, we create a reconstruction based approach for the task of outdoor scene open-set segmentation. We show that our approach improves performance not only when applied to our our own open-set segmentation method, but also when applied to existing methods. Furthermore we contribute a Mamba based architecture which is competitive with existing voxel-convolution based methods on challenging, large-scale pointclouds.
Event-based Star Tracking under Spacecraft Jitter: the e-STURT Dataset
May 19, 2025Jitter degrades a spacecraft's fine-pointing ability required for optical communication, earth observation, and space domain awareness. Development of jitter estimation and compensation algorithms requires high-fidelity sensor observations representative of on-board jitter. In this work, we present the Event-based Star Tracking Under Jitter (e-STURT) dataset -- the first event camera based dataset of star observations under controlled jitter conditions. Specialized hardware employed for the dataset emulates an event-camera undergoing on-board jitter. While the event camera provides asynchronous, high temporal resolution star observations, systematic and repeatable jitter is introduced using a micrometer accurate piezoelectric actuator. Various jitter sources are simulated using distinct frequency bands and utilizing both axes of motion. Ground-truth jitter is captured in hardware from the piezoelectric actuator. The resulting dataset consists of 200 sequences and is made publicly available. This work highlights the dataset generation process, technical challenges and the resulting limitations. To serve as a baseline, we propose a high-frequency jitter estimation algorithm that operates directly on the event stream. The e-STURT dataset will enable the development of jitter aware algorithms for mission critical event-based space sensing applications.
Simultaneous Diffusion Sampling for Conditional LiDAR Generation
Oct 15, 2024

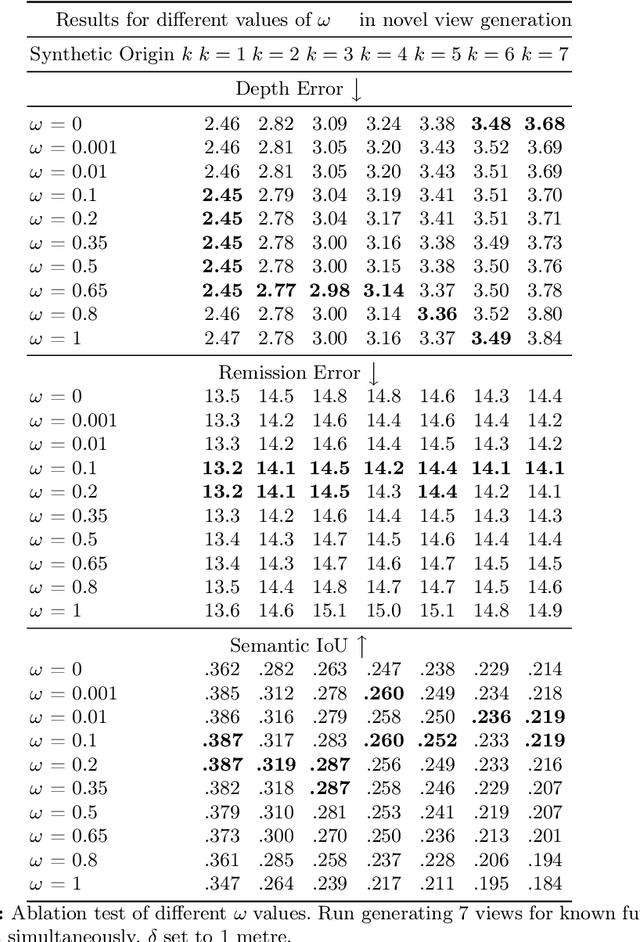
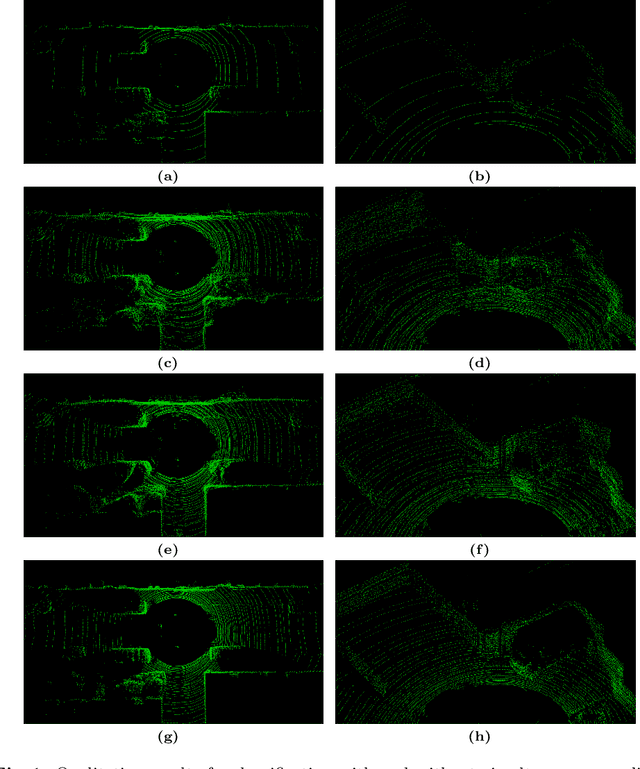
By enabling capturing of 3D point clouds that reflect the geometry of the immediate environment, LiDAR has emerged as a primary sensor for autonomous systems. If a LiDAR scan is too sparse, occluded by obstacles, or too small in range, enhancing the point cloud scan by while respecting the geometry of the scene is useful for downstream tasks. Motivated by the explosive growth of interest in generative methods in vision, conditional LiDAR generation is starting to take off. This paper proposes a novel simultaneous diffusion sampling methodology to generate point clouds conditioned on the 3D structure of the scene as seen from multiple views. The key idea is to impose multi-view geometric constraints on the generation process, exploiting mutual information for enhanced results. Our method begins by recasting the input scan to multiple new viewpoints around the scan, thus creating multiple synthetic LiDAR scans. Then, the synthetic and input LiDAR scans simultaneously undergo conditional generation according to our methodology. Results show that our method can produce accurate and geometrically consistent enhancements to point cloud scans, allowing it to outperform existing methods by a large margin in a variety of benchmarks.
Robust Scene Change Detection Using Visual Foundation Models and Cross-Attention Mechanisms
Sep 25, 2024



We present a novel method for scene change detection that leverages the robust feature extraction capabilities of a visual foundational model, DINOv2, and integrates full-image cross-attention to address key challenges such as varying lighting, seasonal variations, and viewpoint differences. In order to effectively learn correspondences and mis-correspondences between an image pair for the change detection task, we propose to a) ``freeze'' the backbone in order to retain the generality of dense foundation features, and b) employ ``full-image'' cross-attention to better tackle the viewpoint variations between the image pair. We evaluate our approach on two benchmark datasets, VL-CMU-CD and PSCD, along with their viewpoint-varied versions. Our experiments demonstrate significant improvements in F1-score, particularly in scenarios involving geometric changes between image pairs. The results indicate our method's superior generalization capabilities over existing state-of-the-art approaches, showing robustness against photometric and geometric variations as well as better overall generalization when fine-tuned to adapt to new environments. Detailed ablation studies further validate the contributions of each component in our architecture. Source code will be made publicly available upon acceptance.
Test-Time Certifiable Self-Supervision to Bridge the Sim2Real Gap in Event-Based Satellite Pose Estimation
Sep 10, 2024



Deep learning plays a critical role in vision-based satellite pose estimation. However, the scarcity of real data from the space environment means that deep models need to be trained using synthetic data, which raises the Sim2Real domain gap problem. A major cause of the Sim2Real gap are novel lighting conditions encountered during test time. Event sensors have been shown to provide some robustness against lighting variations in vision-based pose estimation. However, challenging lighting conditions due to strong directional light can still cause undesirable effects in the output of commercial off-the-shelf event sensors, such as noisy/spurious events and inhomogeneous event densities on the object. Such effects are non-trivial to simulate in software, thus leading to Sim2Real gap in the event domain. To close the Sim2Real gap in event-based satellite pose estimation, the paper proposes a test-time self-supervision scheme with a certifier module. Self-supervision is enabled by an optimisation routine that aligns a dense point cloud of the predicted satellite pose with the event data to attempt to rectify the inaccurately estimated pose. The certifier attempts to verify the corrected pose, and only certified test-time inputs are backpropagated via implicit differentiation to refine the predicted landmarks, thus improving the pose estimates and closing the Sim2Real gap. Results show that the our method outperforms established test-time adaptation schemes.
Robust Fitting on a Gate Quantum Computer
Sep 03, 2024


Gate quantum computers generate significant interest due to their potential to solve certain difficult problems such as prime factorization in polynomial time. Computer vision researchers have long been attracted to the power of quantum computers. Robust fitting, which is fundamentally important to many computer vision pipelines, has recently been shown to be amenable to gate quantum computing. The previous proposed solution was to compute Boolean influence as a measure of outlyingness using the Bernstein-Vazirani quantum circuit. However, the method assumed a quantum implementation of an $\ell_\infty$ feasibility test, which has not been demonstrated. In this paper, we take a big stride towards quantum robust fitting: we propose a quantum circuit to solve the $\ell_\infty$ feasibility test in the 1D case, which allows to demonstrate for the first time quantum robust fitting on a real gate quantum computer, the IonQ Aria. We also show how 1D Boolean influences can be accumulated to compute Boolean influences for higher-dimensional non-linear models, which we experimentally validate on real benchmark datasets.
Synthetic Lunar Terrain: A Multimodal Open Dataset for Training and Evaluating Neuromorphic Vision Algorithms
Aug 30, 2024Synthetic Lunar Terrain (SLT) is an open dataset collected from an analogue test site for lunar missions, featuring synthetic craters in a high-contrast lighting setup. It includes several side-by-side captures from event-based and conventional RGB cameras, supplemented with a high-resolution 3D laser scan for depth estimation. The event-stream recorded from the neuromorphic vision sensor of the event-based camera is of particular interest as this emerging technology provides several unique advantages, such as high data rates, low energy consumption and resilience towards scenes of high dynamic range. SLT provides a solid foundation to analyse the limits of RGB-cameras and potential advantages or synergies in utilizing neuromorphic visions with the goal of enabling and improving lunar specific applications like rover navigation, landing in cratered environments or similar.