 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePicasso: Holistic Scene Reconstruction with Physics-Constrained Sampling
Feb 08, 2026In the presence of occlusions and measurement noise, geometrically accurate scene reconstructions -- which fit the sensor data -- can still be physically incorrect. For instance, when estimating the poses and shapes of objects in the scene and importing the resulting estimates into a simulator, small errors might translate to implausible configurations including object interpenetration or unstable equilibrium. This makes it difficult to predict the dynamic behavior of the scene using a digital twin, an important step in simulation-based planning and control of contact-rich behaviors. In this paper, we posit that object pose and shape estimation requires reasoning holistically over the scene (instead of reasoning about each object in isolation), accounting for object interactions and physical plausibility. Towards this goal, our first contribution is Picasso, a physics-constrained reconstruction pipeline that builds multi-object scene reconstructions by considering geometry, non-penetration, and physics. Picasso relies on a fast rejection sampling method that reasons over multi-object interactions, leveraging an inferred object contact graph to guide samples. Second, we propose the Picasso dataset, a collection of 10 contact-rich real-world scenes with ground truth annotations, as well as a metric to quantify physical plausibility, which we open-source as part of our benchmark. Finally, we provide an extensive evaluation of Picasso on our newly introduced dataset and on the YCB-V dataset, and show it largely outperforms the state of the art while providing reconstructions that are both physically plausible and more aligned with human intuition.
VGGT-SLAM 2.0: Real time Dense Feed-forward Scene Reconstruction
Jan 27, 2026We present VGGT-SLAM 2.0, a real time RGB feed-forward SLAM system which substantially improves upon VGGT-SLAM for incrementally aligning submaps created from VGGT. Firstly, we remove high-dimensional 15-degree-of-freedom drift and planar degeneracy from VGGT-SLAM by creating a new factor graph design while still addressing the reconstruction ambiguity of VGGT given unknown camera intrinsics. Secondly, by studying the attention layers of VGGT, we show that one of the layers is well suited to assist in image retrieval verification for free without additional training, which enables both rejecting false positive matches and allows for completing more loop closures. Finally, we conduct a suite of experiments which includes showing VGGT-SLAM 2.0 can easily be adapted for open-set object detection and demonstrating real time performance while running online onboard a ground robot using a Jetson Thor. We also test in environments ranging from cluttered indoor apartments and office scenes to a 4,200 square foot barn, and we also demonstrate VGGT-SLAM 2.0 achieves the highest accuracy on the TUM dataset with about 23 percent less pose error than VGGT-SLAM. Code will be released upon publication.
Towards Zero-Shot Point Cloud Registration Across Diverse Scales, Scenes, and Sensor Setups
Jan 06, 2026Some deep learning-based point cloud registration methods struggle with zero-shot generalization, often requiring dataset-specific hyperparameter tuning or retraining for new environments. We identify three critical limitations: (a) fixed user-defined parameters (e.g., voxel size, search radius) that fail to generalize across varying scales, (b) learned keypoint detectors exhibit poor cross-domain transferability, and (c) absolute coordinates amplify scale mismatches between datasets. To address these three issues, we present BUFFER-X, a training-free registration framework that achieves zero-shot generalization through: (a) geometric bootstrapping for automatic hyperparameter estimation, (b) distribution-aware farthest point sampling to replace learned detectors, and (c) patch-level coordinate normalization to ensure scale consistency. Our approach employs hierarchical multi-scale matching to extract correspondences across local, middle, and global receptive fields, enabling robust registration in diverse environments. For efficiency-critical applications, we introduce BUFFER-X-Lite, which reduces total computation time by 43% (relative to BUFFER-X) through early exit strategies and fast pose solvers while preserving accuracy. We evaluate on a comprehensive benchmark comprising 12 datasets spanning object-scale, indoor, and outdoor scenes, including cross-sensor registration between heterogeneous LiDAR configurations. Results demonstrate that our approach generalizes effectively without manual tuning or prior knowledge of test domains. Code: https://github.com/MIT-SPARK/BUFFER-X.
A Roadmap for Climate-Relevant Robotics Research
Jul 15, 2025



Climate change is one of the defining challenges of the 21st century, and many in the robotics community are looking for ways to contribute. This paper presents a roadmap for climate-relevant robotics research, identifying high-impact opportunities for collaboration between roboticists and experts across climate domains such as energy, the built environment, transportation, industry, land use, and Earth sciences. These applications include problems such as energy systems optimization, construction, precision agriculture, building envelope retrofits, autonomous trucking, and large-scale environmental monitoring. Critically, we include opportunities to apply not only physical robots but also the broader robotics toolkit - including planning, perception, control, and estimation algorithms - to climate-relevant problems. A central goal of this roadmap is to inspire new research directions and collaboration by highlighting specific, actionable problems at the intersection of robotics and climate. This work represents a collaboration between robotics researchers and domain experts in various climate disciplines, and it serves as an invitation to the robotics community to bring their expertise to bear on urgent climate priorities.
Box Pose and Shape Estimation and Domain Adaptation for Large-Scale Warehouse Automation
Jul 01, 2025
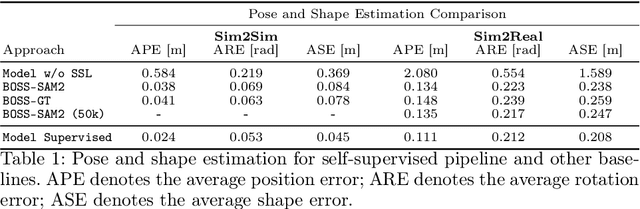
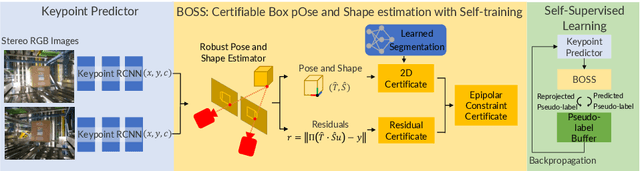
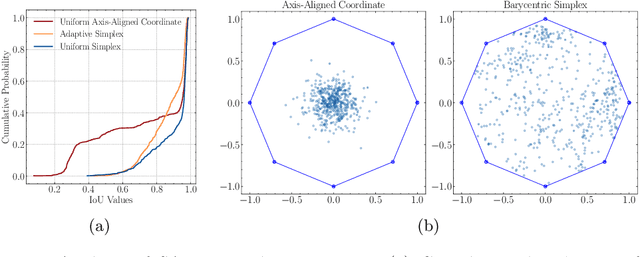
Modern warehouse automation systems rely on fleets of intelligent robots that generate vast amounts of data -- most of which remains unannotated. This paper develops a self-supervised domain adaptation pipeline that leverages real-world, unlabeled data to improve perception models without requiring manual annotations. Our work focuses specifically on estimating the pose and shape of boxes and presents a correct-and-certify pipeline for self-supervised box pose and shape estimation. We extensively evaluate our approach across a range of simulated and real industrial settings, including adaptation to a large-scale real-world dataset of 50,000 images. The self-supervised model significantly outperforms models trained solely in simulation and shows substantial improvements over a zero-shot 3D bounding box estimation baseline.
Language-Grounded Hierarchical Planning and Execution with Multi-Robot 3D Scene Graphs
Jun 09, 2025In this paper, we introduce a multi-robot system that integrates mapping, localization, and task and motion planning (TAMP) enabled by 3D scene graphs to execute complex instructions expressed in natural language. Our system builds a shared 3D scene graph incorporating an open-set object-based map, which is leveraged for multi-robot 3D scene graph fusion. This representation supports real-time, view-invariant relocalization (via the object-based map) and planning (via the 3D scene graph), allowing a team of robots to reason about their surroundings and execute complex tasks. Additionally, we introduce a planning approach that translates operator intent into Planning Domain Definition Language (PDDL) goals using a Large Language Model (LLM) by leveraging context from the shared 3D scene graph and robot capabilities. We provide an experimental assessment of the performance of our system on real-world tasks in large-scale, outdoor environments.
Gaussian Mapping for Evolving Scenes
Jun 07, 2025Mapping systems with novel view synthesis (NVS) capabilities are widely used in computer vision, with augmented reality, robotics, and autonomous driving applications. Most notably, 3D Gaussian Splatting-based systems show high NVS performance; however, many current approaches are limited to static scenes. While recent works have started addressing short-term dynamics (motion within the view of the camera), long-term dynamics (the scene evolving through changes out of view) remain less explored. To overcome this limitation, we introduce a dynamic scene adaptation mechanism that continuously updates the 3D representation to reflect the latest changes. In addition, since maintaining geometric and semantic consistency remains challenging due to stale observations disrupting the reconstruction process, we propose a novel keyframe management mechanism that discards outdated observations while preserving as much information as possible. We evaluate Gaussian Mapping for Evolving Scenes (GaME) on both synthetic and real-world datasets and find it to be more accurate than the state of the art.
VGGT-SLAM: Dense RGB SLAM Optimized on the SL(4) Manifold
May 18, 2025



We present VGGT-SLAM, a dense RGB SLAM system constructed by incrementally and globally aligning submaps created from the feed-forward scene reconstruction approach VGGT using only uncalibrated monocular cameras. While related works align submaps using similarity transforms (i.e., translation, rotation, and scale), we show that such approaches are inadequate in the case of uncalibrated cameras. In particular, we revisit the idea of reconstruction ambiguity, where given a set of uncalibrated cameras with no assumption on the camera motion or scene structure, the scene can only be reconstructed up to a 15-degrees-of-freedom projective transformation of the true geometry. This inspires us to recover a consistent scene reconstruction across submaps by optimizing over the SL(4) manifold, thus estimating 15-degrees-of-freedom homography transforms between sequential submaps while accounting for potential loop closure constraints. As verified by extensive experiments, we demonstrate that VGGT-SLAM achieves improved map quality using long video sequences that are infeasible for VGGT due to its high GPU requirements.
An Addendum to NeBula: Towards Extending TEAM CoSTAR's Solution to Larger Scale Environments
Apr 18, 2025This paper presents an appendix to the original NeBula autonomy solution developed by the TEAM CoSTAR (Collaborative SubTerranean Autonomous Robots), participating in the DARPA Subterranean Challenge. Specifically, this paper presents extensions to NeBula's hardware, software, and algorithmic components that focus on increasing the range and scale of the exploration environment. From the algorithmic perspective, we discuss the following extensions to the original NeBula framework: (i) large-scale geometric and semantic environment mapping; (ii) an adaptive positioning system; (iii) probabilistic traversability analysis and local planning; (iv) large-scale POMDP-based global motion planning and exploration behavior; (v) large-scale networking and decentralized reasoning; (vi) communication-aware mission planning; and (vii) multi-modal ground-aerial exploration solutions. We demonstrate the application and deployment of the presented systems and solutions in various large-scale underground environments, including limestone mine exploration scenarios as well as deployment in the DARPA Subterranean challenge.
ASHiTA: Automatic Scene-grounded HIerarchical Task Analysis
Apr 10, 2025While recent work in scene reconstruction and understanding has made strides in grounding natural language to physical 3D environments, it is still challenging to ground abstract, high-level instructions to a 3D scene. High-level instructions might not explicitly invoke semantic elements in the scene, and even the process of breaking a high-level task into a set of more concrete subtasks, a process called hierarchical task analysis, is environment-dependent. In this work, we propose ASHiTA, the first framework that generates a task hierarchy grounded to a 3D scene graph by breaking down high-level tasks into grounded subtasks. ASHiTA alternates LLM-assisted hierarchical task analysis, to generate the task breakdown, with task-driven 3D scene graph construction to generate a suitable representation of the environment. Our experiments show that ASHiTA performs significantly better than LLM baselines in breaking down high-level tasks into environment-dependent subtasks and is additionally able to achieve grounding performance comparable to state-of-the-art methods.