 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Object Representation for Spatial Robot Perception: Points, Meshes, and Superquadrics
Jun 01, 2026Hierarchical 3D Scene Graphs (3DSG) have emerged as an actionable and scalable representation for long-term autonomy incorporating metric, semantic, and topological information in the scene. However, the question of geometric representation of objects in 3DSG has been overlooked as most methods use simplified geometric models such as partial point clouds or 3D bounding boxes. In this work, we introduce a hierarchical object representation that can be leveraged for high-fidelity object-level reconstruction, object-based robust re-localization or map alignment, and efficient and analytical collision checking for safe robot navigation planning in dense and cluttered environments. The representation is structurally organized into four distinct layers, progressively abstracting the scene from raw sensor data to dense 3D meshes to analytical primitives such as superquadrics, which provide a sparse and analytical representation for object geometry. We develop a pipeline that builds the hierarchical object representation from RGB-D image stream captured by a robot, and demonstrate its working in real-world open-set object scenes in both indoor and outdoor environments. Extensive experiments across diverse datasets including HOPE, ReplicaCAD, Kimera-Multi, and NUS Campus Dataset collected using Unitree B2 Robot validate our pipeline in both indoor and outdoor environments. We show that our superquadric-based map alignment method outperforms the current state-of-the-art object based map alignment method ROMAN. Our code can be found at https://github.com/perceptica-robotics/Hickory.
Object Pose and Shape Estimation for Grasping: Does it Work?
May 26, 2026The problem of object pose and shape estimation has seen key advancements lately. Encoder-decoder (e.g., SAM3D, LRM, CRISP) and diffusion-based models (e.g., InstantMesh, Zero123, SceneComplete) have shown category-agnostic shape encoding capacity and open-set generalizability. In this work, we ask the question: Are the object pose and shape estimation methods mature enough, such that when used with antipodal grasp sampling, can outperform the end-to-end grasp synthesis methods? We explore this question in detail by scoping our study to parallel jaw grippers, 7-DoF grasps, and single-view RGB(-D) image as input. We implement and compare a state-of-the-art, end-to-end grasp synthesis method and three modular methods, which first estimate the object pose and shape for all objects in the scene, and generate grasps using antipodal sampling. We observe that the modular methods outperform the end-to-end method in all our experiments. The modular methods are able to synthesize plenty of grasps, even for small objects, where the end-to-end methods fail. The effectiveness of the modular methods is contingent on the accuracy of the pose and shape estimation, and suffers partial degradation in cluttered scenes - a limitation of the existing pose and shape estimation methods. We also analyze the failure modes and run-times for the three modular methods, which use two different ways of object pose and shape estimation: one based on an encoder-decoder model, while another a diffusion model. Finally, we demonstrate that the single-view object pose and shape estimation methods can be augmented with vision-language models to yield language-conditioned grasps from just single-view RGB-D image as input. We notice comparable performance to the state-of-the-art LERF-TOGO baseline.
Picasso: Holistic Scene Reconstruction with Physics-Constrained Sampling
Feb 08, 2026In the presence of occlusions and measurement noise, geometrically accurate scene reconstructions -- which fit the sensor data -- can still be physically incorrect. For instance, when estimating the poses and shapes of objects in the scene and importing the resulting estimates into a simulator, small errors might translate to implausible configurations including object interpenetration or unstable equilibrium. This makes it difficult to predict the dynamic behavior of the scene using a digital twin, an important step in simulation-based planning and control of contact-rich behaviors. In this paper, we posit that object pose and shape estimation requires reasoning holistically over the scene (instead of reasoning about each object in isolation), accounting for object interactions and physical plausibility. Towards this goal, our first contribution is Picasso, a physics-constrained reconstruction pipeline that builds multi-object scene reconstructions by considering geometry, non-penetration, and physics. Picasso relies on a fast rejection sampling method that reasons over multi-object interactions, leveraging an inferred object contact graph to guide samples. Second, we propose the Picasso dataset, a collection of 10 contact-rich real-world scenes with ground truth annotations, as well as a metric to quantify physical plausibility, which we open-source as part of our benchmark. Finally, we provide an extensive evaluation of Picasso on our newly introduced dataset and on the YCB-V dataset, and show it largely outperforms the state of the art while providing reconstructions that are both physically plausible and more aligned with human intuition.
Box Pose and Shape Estimation and Domain Adaptation for Large-Scale Warehouse Automation
Jul 01, 2025
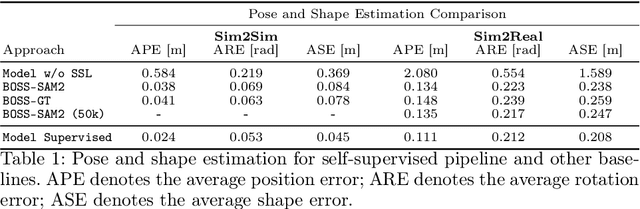
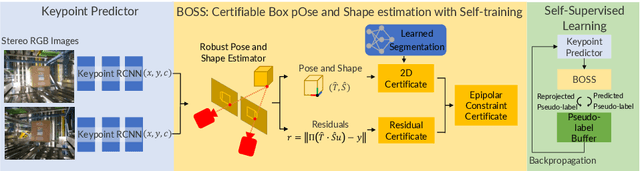
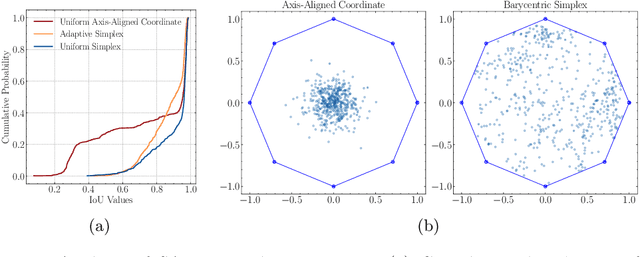
Modern warehouse automation systems rely on fleets of intelligent robots that generate vast amounts of data -- most of which remains unannotated. This paper develops a self-supervised domain adaptation pipeline that leverages real-world, unlabeled data to improve perception models without requiring manual annotations. Our work focuses specifically on estimating the pose and shape of boxes and presents a correct-and-certify pipeline for self-supervised box pose and shape estimation. We extensively evaluate our approach across a range of simulated and real industrial settings, including adaptation to a large-scale real-world dataset of 50,000 images. The self-supervised model significantly outperforms models trained solely in simulation and shows substantial improvements over a zero-shot 3D bounding box estimation baseline.
Language-Grounded Hierarchical Planning and Execution with Multi-Robot 3D Scene Graphs
Jun 09, 2025In this paper, we introduce a multi-robot system that integrates mapping, localization, and task and motion planning (TAMP) enabled by 3D scene graphs to execute complex instructions expressed in natural language. Our system builds a shared 3D scene graph incorporating an open-set object-based map, which is leveraged for multi-robot 3D scene graph fusion. This representation supports real-time, view-invariant relocalization (via the object-based map) and planning (via the 3D scene graph), allowing a team of robots to reason about their surroundings and execute complex tasks. Additionally, we introduce a planning approach that translates operator intent into Planning Domain Definition Language (PDDL) goals using a Large Language Model (LLM) by leveraging context from the shared 3D scene graph and robot capabilities. We provide an experimental assessment of the performance of our system on real-world tasks in large-scale, outdoor environments.
Outlier-Robust Training of Machine Learning Models
Dec 31, 2024Robust training of machine learning models in the presence of outliers has garnered attention across various domains. The use of robust losses is a popular approach and is known to mitigate the impact of outliers. We bring to light two literatures that have diverged in their ways of designing robust losses: one using M-estimation, which is popular in robotics and computer vision, and another using a risk-minimization framework, which is popular in deep learning. We first show that a simple modification of the Black-Rangarajan duality provides a unifying view. The modified duality brings out a definition of a robust loss kernel $\sigma$ that is satisfied by robust losses in both the literatures. Secondly, using the modified duality, we propose an Adaptive Alternation Algorithm (AAA) for training machine learning models with outliers. The algorithm iteratively trains the model by using a weighted version of the non-robust loss, while updating the weights at each iteration. The algorithm is augmented with a novel parameter update rule by interpreting the weights as inlier probabilities, and obviates the need for complex parameter tuning. Thirdly, we investigate convergence of the adaptive alternation algorithm to outlier-free optima. Considering arbitrary outliers (i.e., with no distributional assumption on the outliers), we show that the use of robust loss kernels {\sigma} increases the region of convergence. We experimentally show the efficacy of our algorithm on regression, classification, and neural scene reconstruction problems. We release our implementation code: https://github.com/MIT-SPARK/ORT.
CRISP: Object Pose and Shape Estimation with Test-Time Adaptation
Dec 02, 2024

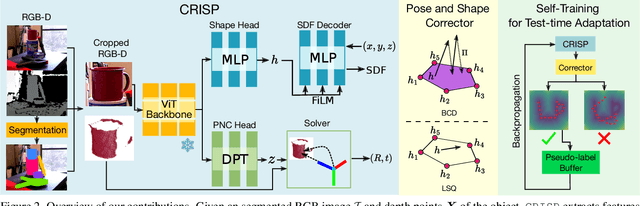

We consider the problem of estimating object pose and shape from an RGB-D image. Our first contribution is to introduce CRISP, a category-agnostic object pose and shape estimation pipeline. The pipeline implements an encoder-decoder model for shape estimation. It uses FiLM-conditioning for implicit shape reconstruction and a DPT-based network for estimating pose-normalized points for pose estimation. As a second contribution, we propose an optimization-based pose and shape corrector that can correct estimation errors caused by a domain gap. Observing that the shape decoder is well behaved in the convex hull of known shapes, we approximate the shape decoder with an active shape model, and show that this reduces the shape correction problem to a constrained linear least squares problem, which can be solved efficiently by an interior point algorithm. Third, we introduce a self-training pipeline to perform self-supervised domain adaptation of CRISP. The self-training is based on a correct-and-certify approach, which leverages the corrector to generate pseudo-labels at test time, and uses them to self-train CRISP. We demonstrate CRISP (and the self-training) on YCBV, SPE3R, and NOCS datasets. CRISP shows high performance on all the datasets. Moreover, our self-training is capable of bridging a large domain gap. Finally, CRISP also shows an ability to generalize to unseen objects. Code and pre-trained models will be available on https://web.mit.edu/sparklab/research/crisp_object_pose_shape/.
Test-Time Certifiable Self-Supervision to Bridge the Sim2Real Gap in Event-Based Satellite Pose Estimation
Sep 10, 2024



Deep learning plays a critical role in vision-based satellite pose estimation. However, the scarcity of real data from the space environment means that deep models need to be trained using synthetic data, which raises the Sim2Real domain gap problem. A major cause of the Sim2Real gap are novel lighting conditions encountered during test time. Event sensors have been shown to provide some robustness against lighting variations in vision-based pose estimation. However, challenging lighting conditions due to strong directional light can still cause undesirable effects in the output of commercial off-the-shelf event sensors, such as noisy/spurious events and inhomogeneous event densities on the object. Such effects are non-trivial to simulate in software, thus leading to Sim2Real gap in the event domain. To close the Sim2Real gap in event-based satellite pose estimation, the paper proposes a test-time self-supervision scheme with a certifier module. Self-supervision is enabled by an optimisation routine that aligns a dense point cloud of the predicted satellite pose with the event data to attempt to rectify the inaccurately estimated pose. The certifier attempts to verify the corrected pose, and only certified test-time inputs are backpropagated via implicit differentiation to refine the predicted landmarks, thus improving the pose estimates and closing the Sim2Real gap. Results show that the our method outperforms established test-time adaptation schemes.
Safe Distributed Control of Multi-Robot Systems with Communication Delays
Feb 14, 2024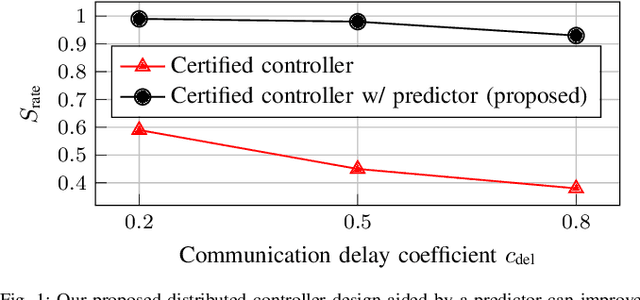
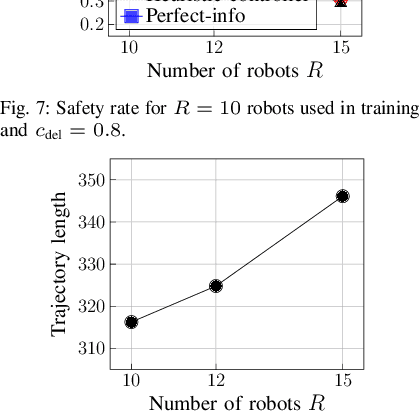
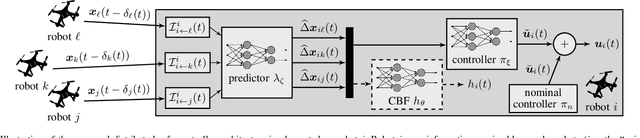
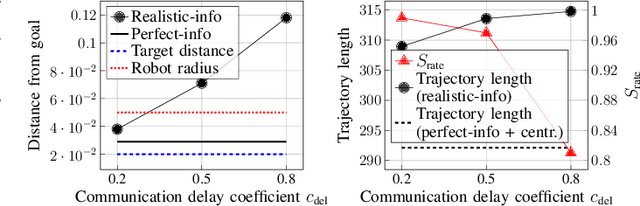
Safe operation of multi-robot systems is critical, especially in communication-degraded environments such as underwater for seabed mapping, underground caves for navigation, and in extraterrestrial missions for assembly and construction. We address safety of networked autonomous systems where the information exchanged between robots incurs communication delays. We formalize a notion of distributed control barrier function (CBF) for multi-robot systems, a safety certificate amenable to a distributed implementation, which provides formal ground to using graph neural networks to learn safe distributed controllers. Further, we observe that learning a distributed controller ignoring delays can severely degrade safety. Our main contribution is a predictor-based framework to train a safe distributed controller under communication delays, where the current state of nearby robots is predicted from received data and age-of-information. Numerical experiments on multi-robot collision avoidance show that our predictor-based approach can significantly improve the safety of a learned distributed controller under communication delays
Foundations of Spatial Perception for Robotics: Hierarchical Representations and Real-time Systems
May 11, 20233D spatial perception is the problem of building and maintaining an actionable and persistent representation of the environment in real-time using sensor data and prior knowledge. Despite the fast-paced progress in robot perception, most existing methods either build purely geometric maps (as in traditional SLAM) or flat metric-semantic maps that do not scale to large environments or large dictionaries of semantic labels. The first part of this paper is concerned with representations: we show that scalable representations for spatial perception need to be hierarchical in nature. Hierarchical representations are efficient to store, and lead to layered graphs with small treewidth, which enable provably efficient inference. We then introduce an example of hierarchical representation for indoor environments, namely a 3D scene graph, and discuss its structure and properties. The second part of the paper focuses on algorithms to incrementally construct a 3D scene graph as the robot explores the environment. Our algorithms combine 3D geometry, topology (to cluster the places into rooms), and geometric deep learning (e.g., to classify the type of rooms the robot is moving across). The third part of the paper focuses on algorithms to maintain and correct 3D scene graphs during long-term operation. We propose hierarchical descriptors for loop closure detection and describe how to correct a scene graph in response to loop closures, by solving a 3D scene graph optimization problem. We conclude the paper by combining the proposed perception algorithms into Hydra, a real-time spatial perception system that builds a 3D scene graph from visual-inertial data in real-time. We showcase Hydra's performance in photo-realistic simulations and real data collected by a Clearpath Jackal robots and a Unitree A1 robot. We release an open-source implementation of Hydra at https://github.com/MIT-SPARK/Hydra.