 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBox Pose and Shape Estimation and Domain Adaptation for Large-Scale Warehouse Automation
Jul 01, 2025
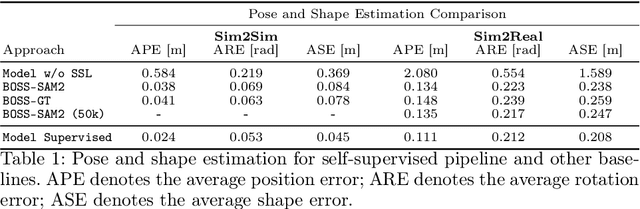
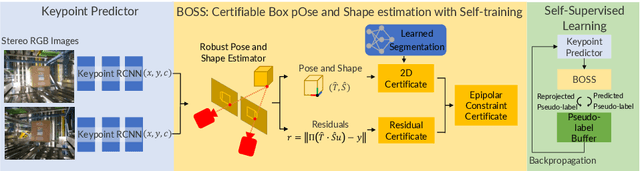
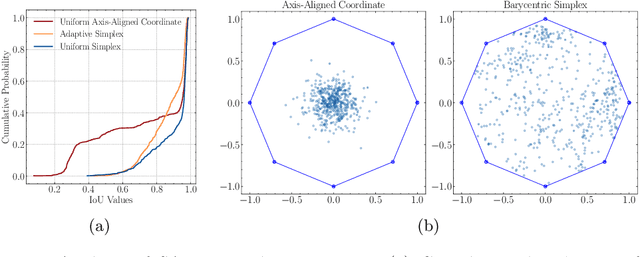
Modern warehouse automation systems rely on fleets of intelligent robots that generate vast amounts of data -- most of which remains unannotated. This paper develops a self-supervised domain adaptation pipeline that leverages real-world, unlabeled data to improve perception models without requiring manual annotations. Our work focuses specifically on estimating the pose and shape of boxes and presents a correct-and-certify pipeline for self-supervised box pose and shape estimation. We extensively evaluate our approach across a range of simulated and real industrial settings, including adaptation to a large-scale real-world dataset of 50,000 images. The self-supervised model significantly outperforms models trained solely in simulation and shows substantial improvements over a zero-shot 3D bounding box estimation baseline.
Learning visual servo policies via planner cloning
May 24, 2020



Learning control policies for visual servoing in novel environments is an important problem. However, standard model-free policy learning methods are slow. This paper explores planner cloning: using behavior cloning to learn policies that mimic the behavior of a full-state motion planner in simulation. We propose Penalized Q Cloning (PQC), a new behavior cloning algorithm. We show that it outperforms several baselines and ablations on some challenging problems involving visual servoing in novel environments while avoiding obstacles. Finally, we demonstrate that these policies can be transferred effectively onto a real robotic platform, achieving approximately an 87% success rate both in simulation and on a real robot.
Adapting control policies from simulation to reality using a pairwise loss
Oct 26, 2018
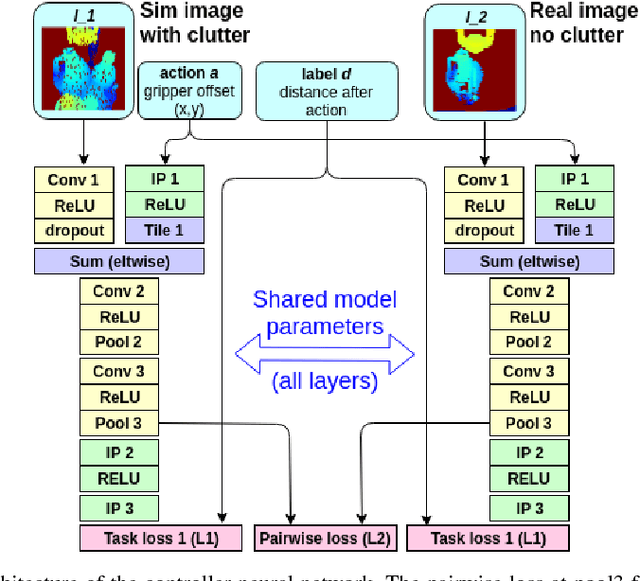


This paper proposes an approach to domain transfer based on a pairwise loss function that helps transfer control policies learned in simulation onto a real robot. We explore the idea in the context of a 'category level' manipulation task where a control policy is learned that enables a robot to perform a mating task involving novel objects. We explore the case where depth images are used as the main form of sensor input. Our experimental results demonstrate that proposed method consistently outperforms baseline methods that train only in simulation or that combine real and simulated data in a naive way.
Learning a visuomotor controller for real world robotic grasping using simulated depth images
Nov 17, 2017

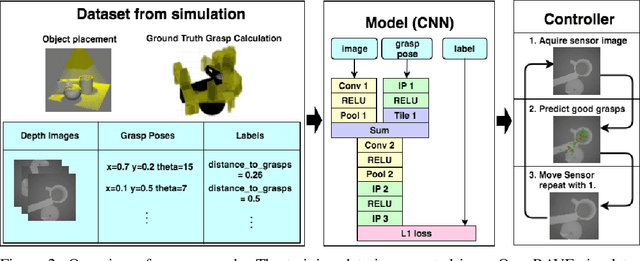
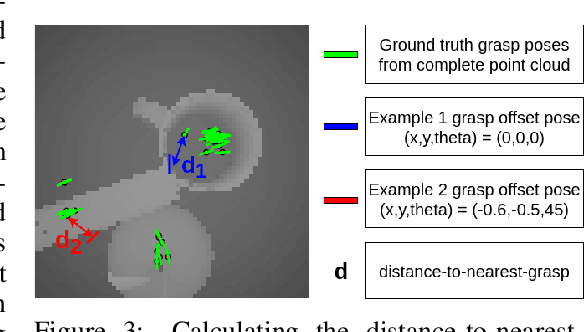
We want to build robots that are useful in unstructured real world applications, such as doing work in the household. Grasping in particular is an important skill in this domain, yet it remains a challenge. One of the key hurdles is handling unexpected changes or motion in the objects being grasped and kinematic noise or other errors in the robot. This paper proposes an approach to learning a closed-loop controller for robotic grasping that dynamically guides the gripper to the object. We use a wrist-mounted sensor to acquire depth images in front of the gripper and train a convolutional neural network to learn a distance function to true grasps for grasp configurations over an image. The training sensor data is generated in simulation, a major advantage over previous work that uses real robot experience, which is costly to obtain. Despite being trained in simulation, our approach works well on real noisy sensor images. We compare our controller in simulated and real robot experiments to a strong baseline for grasp pose detection, and find that our approach significantly outperforms the baseline in the presence of kinematic noise, perceptual errors and disturbances of the object during grasping.