 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Breaking the Assistant Mold: Modeling Behavioral Variation in LLM Based Procedural Character Generation
Jan 06, 2026Procedural content generation has enabled vast virtual worlds through levels, maps, and quests, but large-scale character generation remains underexplored. We identify two alignment-induced biases in existing methods: a positive moral bias, where characters uniformly adopt agreeable stances (e.g. always saying lying is bad), and a helpful assistant bias, where characters invariably answer questions directly (e.g. never refusing or deflecting). While such tendencies suit instruction-following systems, they suppress dramatic tension and yield predictable characters, stemming from maximum likelihood training and assistant fine-tuning. To address this, we introduce PersonaWeaver, a framework that disentangles world-building (roles, demographics) from behavioral-building (moral stances, interactional styles), yielding characters with more diverse reactions and moral stances, as well as second-order diversity in stylistic markers like length, tone, and punctuation. Code: https://github.com/mqraitem/Persona-Weaver
Mull-Tokens: Modality-Agnostic Latent Thinking
Dec 11, 2025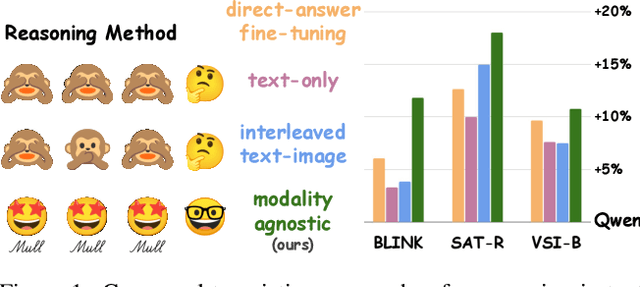
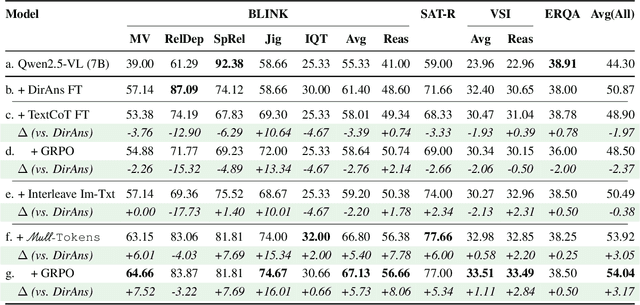
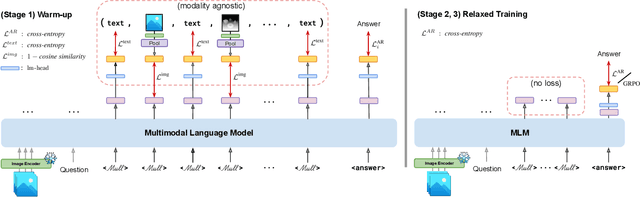
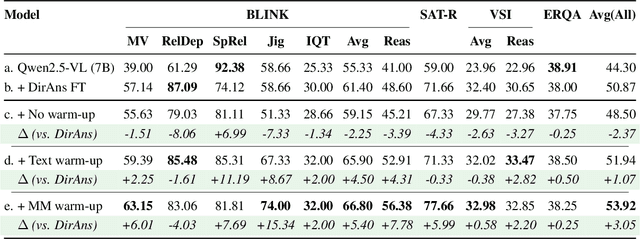
Reasoning goes beyond language; the real world requires reasoning about space, time, affordances, and much more that words alone cannot convey. Existing multimodal models exploring the potential of reasoning with images are brittle and do not scale. They rely on calling specialist tools, costly generation of images, or handcrafted reasoning data to switch between text and image thoughts. Instead, we offer a simpler alternative -- Mull-Tokens -- modality-agnostic latent tokens pre-trained to hold intermediate information in either image or text modalities to let the model think free-form towards the correct answer. We investigate best practices to train Mull-Tokens inspired by latent reasoning frameworks. We first train Mull-Tokens using supervision from interleaved text-image traces, and then fine-tune without any supervision by only using the final answers. Across four challenging spatial reasoning benchmarks involving tasks such as solving puzzles and taking different perspectives, we demonstrate that Mull-Tokens improve upon several baselines utilizing text-only reasoning or interleaved image-text reasoning, achieving a +3% average improvement and up to +16% on a puzzle solving reasoning-heavy split compared to our strongest baseline. Adding to conversations around challenges in grounding textual and visual reasoning, Mull-Tokens offers a simple solution to abstractly think in multiple modalities.
BabyVLM-V2: Toward Developmentally Grounded Pretraining and Benchmarking of Vision Foundation Models
Dec 11, 2025Early children's developmental trajectories set up a natural goal for sample-efficient pretraining of vision foundation models. We introduce BabyVLM-V2, a developmentally grounded framework for infant-inspired vision-language modeling that extensively improves upon BabyVLM-V1 through a longitudinal, multifaceted pretraining set, a versatile model, and, most importantly, DevCV Toolbox for cognitive evaluation. The pretraining set maximizes coverage while minimizing curation of a longitudinal, infant-centric audiovisual corpus, yielding video-utterance, image-utterance, and multi-turn conversational data that mirror infant experiences. DevCV Toolbox adapts all vision-related measures of the recently released NIH Baby Toolbox into a benchmark suite of ten multimodal tasks, covering spatial reasoning, memory, and vocabulary understanding aligned with early children's capabilities. Experimental results show that a compact model pretrained from scratch can achieve competitive performance on DevCV Toolbox, outperforming GPT-4o on some tasks. We hope the principled, unified BabyVLM-V2 framework will accelerate research in developmentally plausible pretraining of vision foundation models.
The SA-FARI Dataset: Segment Anything in Footage of Animals for Recognition and Identification
Nov 19, 2025Automated video analysis is critical for wildlife conservation. A foundational task in this domain is multi-animal tracking (MAT), which underpins applications such as individual re-identification and behavior recognition. However, existing datasets are limited in scale, constrained to a few species, or lack sufficient temporal and geographical diversity - leaving no suitable benchmark for training general-purpose MAT models applicable across wild animal populations. To address this, we introduce SA-FARI, the largest open-source MAT dataset for wild animals. It comprises 11,609 camera trap videos collected over approximately 10 years (2014-2024) from 741 locations across 4 continents, spanning 99 species categories. Each video is exhaustively annotated culminating in ~46 hours of densely annotated footage containing 16,224 masklet identities and 942,702 individual bounding boxes, segmentation masks, and species labels. Alongside the task-specific annotations, we publish anonymized camera trap locations for each video. Finally, we present comprehensive benchmarks on SA-FARI using state-of-the-art vision-language models for detection and tracking, including SAM 3, evaluated with both species-specific and generic animal prompts. We also compare against vision-only methods developed specifically for wildlife analysis. SA-FARI is the first large-scale dataset to combine high species diversity, multi-region coverage, and high-quality spatio-temporal annotations, offering a new foundation for advancing generalizable multianimal tracking in the wild. The dataset is available at $\href{https://www.conservationxlabs.com/sa-fari}{\text{conservationxlabs.com/SA-FARI}}$.
Enhancing Compositional Reasoning in Vision-Language Models with Synthetic Preference Data
Apr 07, 2025



Compositionality, or correctly recognizing scenes as compositions of atomic visual concepts, remains difficult for multimodal large language models (MLLMs). Even state of the art MLLMs such as GPT-4o can make mistakes in distinguishing compositions like "dog chasing cat" vs "cat chasing dog". While on Winoground, a benchmark for measuring such reasoning, MLLMs have made significant progress, they are still far from a human's performance. We show that compositional reasoning in these models can be improved by elucidating such concepts via data, where a model is trained to prefer the correct caption for an image over a close but incorrect one. We introduce SCRAMBLe: Synthetic Compositional Reasoning Augmentation of MLLMs with Binary preference Learning, an approach for preference tuning open-weight MLLMs on synthetic preference data generated in a fully automated manner from existing image-caption data. SCRAMBLe holistically improves these MLLMs' compositional reasoning capabilities which we can see through significant improvements across multiple vision language compositionality benchmarks, as well as smaller but significant improvements on general question answering tasks. As a sneak peek, SCRAMBLe tuned Molmo-7B model improves on Winoground from 49.5% to 54.8% (best reported to date), while improving by ~1% on more general visual question answering tasks. Code for SCRAMBLe along with tuned models and our synthetic training dataset is available at https://github.com/samarth4149/SCRAMBLe.
Web Artifact Attacks Disrupt Vision Language Models
Mar 17, 2025Vision-language models (VLMs) (e.g., CLIP, LLaVA) are trained on large-scale, lightly curated web datasets, leading them to learn unintended correlations between semantic concepts and unrelated visual signals. These associations degrade model accuracy by causing predictions to rely on incidental patterns rather than genuine visual understanding. Prior work has weaponized these correlations as an attack vector to manipulate model predictions, such as inserting a deceiving class text onto the image in a typographic attack. These attacks succeed due to VLMs' text-heavy bias-a result of captions that echo visible words rather than describing content. However, this attack has focused solely on text that matches the target class exactly, overlooking a broader range of correlations, including non-matching text and graphical symbols, which arise from the abundance of branding content in web-scale data. To address this gap, we introduce artifact-based attacks: a novel class of manipulations that mislead models using both non-matching text and graphical elements. Unlike typographic attacks, these artifacts are not predefined, making them harder to defend against but also more challenging to find. We address this by framing artifact attacks as a search problem and demonstrate their effectiveness across five datasets, with some artifacts reinforcing each other to reach 100% attack success rates. These attacks transfer across models with up to 90% effectiveness, making it possible to attack unseen models. To defend against these attacks, we extend prior work's artifact aware prompting to the graphical setting. We see a moderate reduction of success rates of up to 15% relative to standard prompts, suggesting a promising direction for enhancing model robustness.
SPARC: Score Prompting and Adaptive Fusion for Zero-Shot Multi-Label Recognition in Vision-Language Models
Feb 24, 2025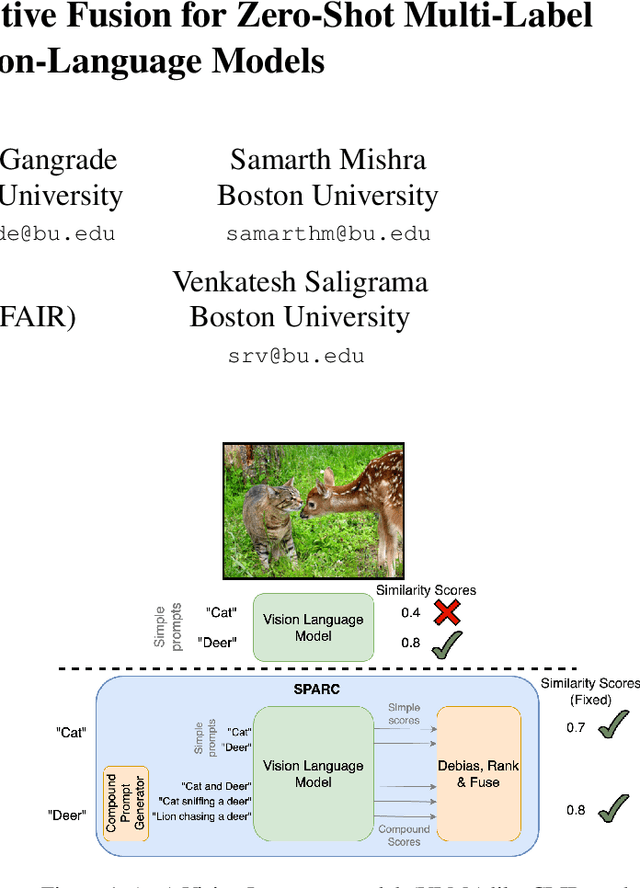
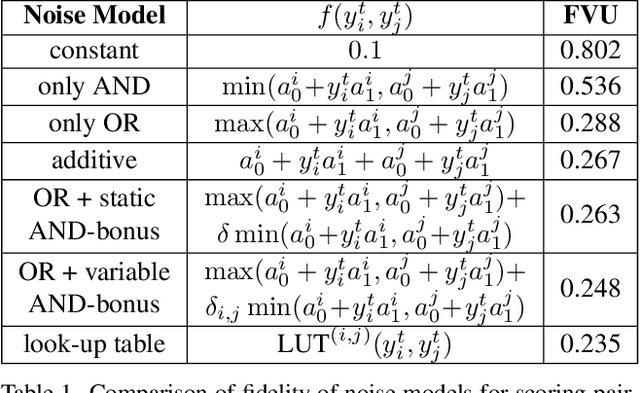
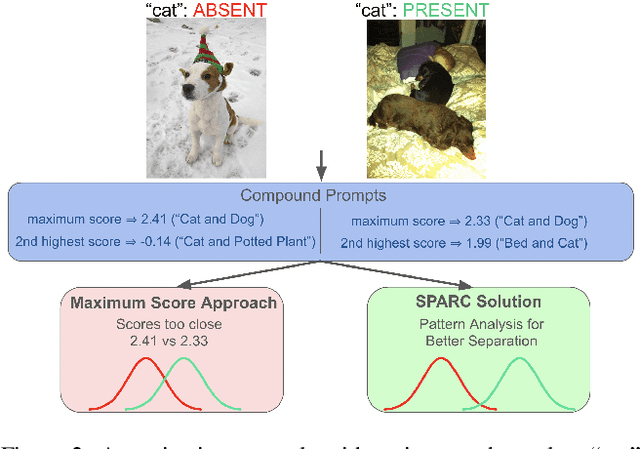
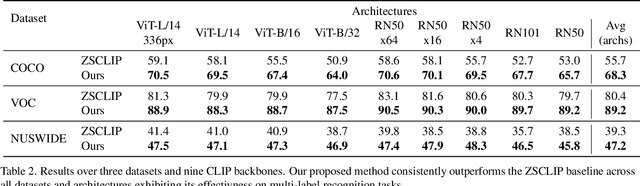
Zero-shot multi-label recognition (MLR) with Vision-Language Models (VLMs) faces significant challenges without training data, model tuning, or architectural modifications. Existing approaches require prompt tuning or architectural adaptations, limiting zero-shot applicability. Our work proposes a novel solution treating VLMs as black boxes, leveraging scores without training data or ground truth. Using large language model insights on object co-occurrence, we introduce compound prompts grounded in realistic object combinations. Analysis of these prompt scores reveals VLM biases and ``AND''/``OR'' signal ambiguities, notably that maximum compound scores are surprisingly suboptimal compared to second-highest scores. We address these through a debiasing and score-fusion algorithm that corrects image bias and clarifies VLM response behaviors. Our method enhances other zero-shot approaches, consistently improving their results. Experiments show superior mean Average Precision (mAP) compared to methods requiring training data, achieved through refined object ranking for robust zero-shot MLR.
OP-LoRA: The Blessing of Dimensionality
Dec 13, 2024



Low-rank adapters enable fine-tuning of large models with only a small number of parameters, thus reducing storage costs and minimizing the risk of catastrophic forgetting. However, they often pose optimization challenges, with poor convergence. To overcome these challenges, we introduce an over-parameterized approach that accelerates training without increasing inference costs. This method reparameterizes low-rank adaptation by employing a separate MLP and learned embedding for each layer. The learned embedding is input to the MLP, which generates the adapter parameters. Such overparamaterization has been shown to implicitly function as an adaptive learning rate and momentum, accelerating optimization. At inference time, the MLP can be discarded, leaving behind a standard low-rank adapter. To study the effect of MLP overparameterization on a small yet difficult proxy task, we implement it for matrix factorization, and find it achieves faster convergence and lower final loss. Extending this approach to larger-scale tasks, we observe consistent performance gains across domains. We achieve improvements in vision-language tasks and especially notable increases in image generation, with CMMD scores improving by up to 15 points.
SAT: Spatial Aptitude Training for Multimodal Language Models
Dec 10, 2024



Spatial perception is a fundamental component of intelligence. While many studies highlight that large multimodal language models (MLMs) struggle to reason about space, they only test for static spatial reasoning, such as categorizing the relative positions of objects. Meanwhile, real-world deployment requires dynamic capabilities like perspective-taking and egocentric action recognition. As a roadmap to improving spatial intelligence, we introduce SAT, Spatial Aptitude Training, which goes beyond static relative object position questions to the more dynamic tasks. SAT contains 218K question-answer pairs for 22K synthetic scenes across a training and testing set. Generated using a photo-realistic physics engine, our dataset can be arbitrarily scaled and easily extended to new actions, scenes, and 3D assets. We find that even MLMs that perform relatively well on static questions struggle to accurately answer dynamic spatial questions. Further, we show that SAT instruction-tuning data improves not only dynamic spatial reasoning on SAT, but also zero-shot performance on existing real-image spatial benchmarks: $23\%$ on CVBench, $8\%$ on the harder BLINK benchmark, and $18\%$ on VSR. When instruction-tuned on SAT, our 13B model matches larger proprietary MLMs like GPT4-V and Gemini-3-1.0 in spatial reasoning. Our data/code is available at http://arijitray1993.github.io/SAT/ .