 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePermissioned LLMs: Enforcing Access Control in Large Language Models
May 28, 2025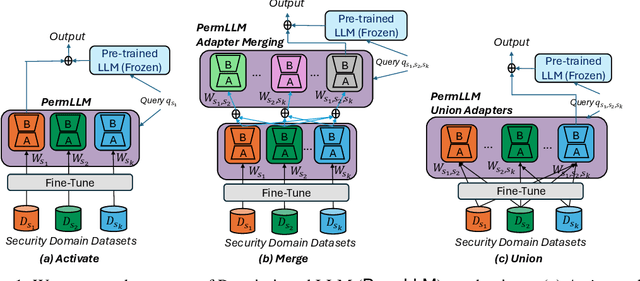

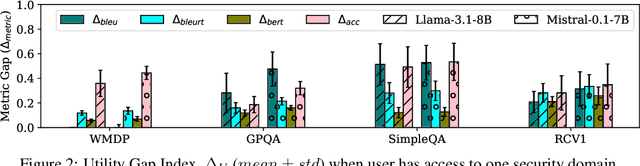
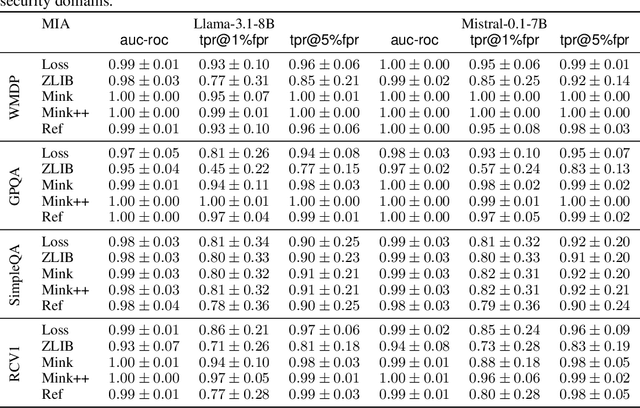
In enterprise settings, organizational data is segregated, siloed and carefully protected by elaborate access control frameworks. These access control structures can completely break down if an LLM fine-tuned on the siloed data serves requests, for downstream tasks, from individuals with disparate access privileges. We propose Permissioned LLMs (PermLLM), a new class of LLMs that superimpose the organizational data access control structures on query responses they generate. We formalize abstractions underpinning the means to determine whether access control enforcement happens correctly over LLM query responses. Our formalism introduces the notion of a relevant response that can be used to prove whether a PermLLM mechanism has been implemented correctly. We also introduce a novel metric, called access advantage, to empirically evaluate the efficacy of a PermLLM mechanism. We introduce three novel PermLLM mechanisms that build on Parameter Efficient Fine-Tuning to achieve the desired access control. We furthermore present two instantiations of access advantage--(i) Domain Distinguishability Index (DDI) based on Membership Inference Attacks, and (ii) Utility Gap Index (UGI) based on LLM utility evaluation. We demonstrate the efficacy of our PermLLM mechanisms through extensive experiments on four public datasets (GPQA, RCV1, SimpleQA, and WMDP), in addition to evaluating the validity of DDI and UGI metrics themselves for quantifying access control in LLMs.
Measuring Déjà vu Memorization Efficiently
Apr 08, 2025



Recent research has shown that representation learning models may accidentally memorize their training data. For example, the d\'ej\`a vu method shows that for certain representation learning models and training images, it is sometimes possible to correctly predict the foreground label given only the representation of the background - better than through dataset-level correlations. However, their measurement method requires training two models - one to estimate dataset-level correlations and the other to estimate memorization. This multiple model setup becomes infeasible for large open-source models. In this work, we propose alternative simple methods to estimate dataset-level correlations, and show that these can be used to approximate an off-the-shelf model's memorization ability without any retraining. This enables, for the first time, the measurement of memorization in pre-trained open-source image representation and vision-language representation models. Our results show that different ways of measuring memorization yield very similar aggregate results. We also find that open-source models typically have lower aggregate memorization than similar models trained on a subset of the data. The code is available both for vision and vision language models.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
Déjà Vu Memorization in Vision-Language Models
Feb 03, 2024



Vision-Language Models (VLMs) have emerged as the state-of-the-art representation learning solution, with myriads of downstream applications such as image classification, retrieval and generation. A natural question is whether these models memorize their training data, which also has implications for generalization. We propose a new method for measuring memorization in VLMs, which we call d\'ej\`a vu memorization. For VLMs trained on image-caption pairs, we show that the model indeed retains information about individual objects in the training images beyond what can be inferred from correlations or the image caption. We evaluate d\'ej\`a vu memorization at both sample and population level, and show that it is significant for OpenCLIP trained on as many as 50M image-caption pairs. Finally, we show that text randomization considerably mitigates memorization while only moderately impacting the model's downstream task performance.
Are Attribute Inference Attacks Just Imputation?
Sep 02, 2022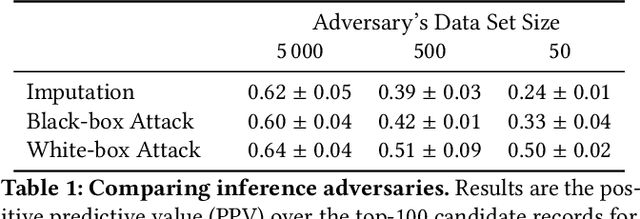
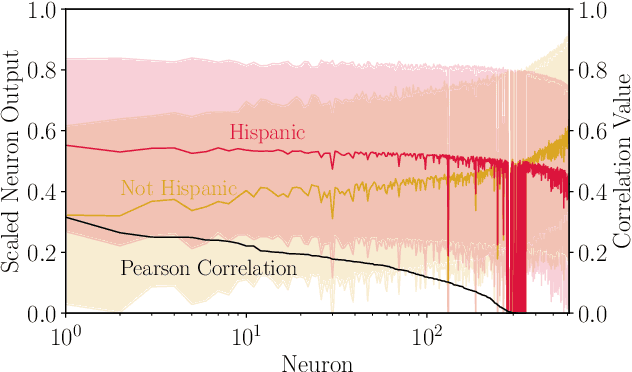
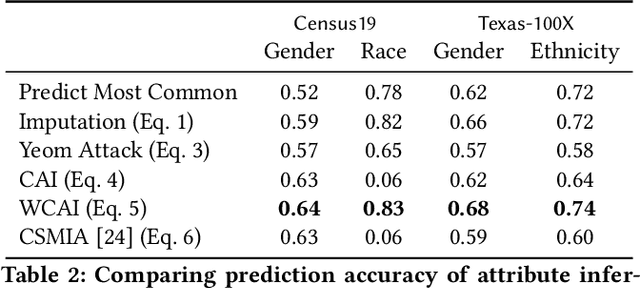
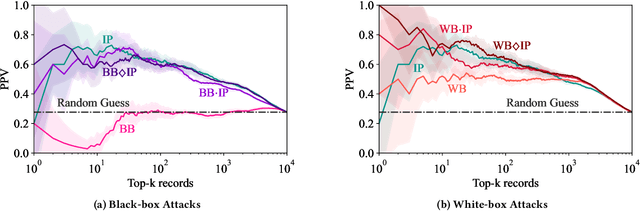
Models can expose sensitive information about their training data. In an attribute inference attack, an adversary has partial knowledge of some training records and access to a model trained on those records, and infers the unknown values of a sensitive feature of those records. We study a fine-grained variant of attribute inference we call \emph{sensitive value inference}, where the adversary's goal is to identify with high confidence some records from a candidate set where the unknown attribute has a particular sensitive value. We explicitly compare attribute inference with data imputation that captures the training distribution statistics, under various assumptions about the training data available to the adversary. Our main conclusions are: (1) previous attribute inference methods do not reveal more about the training data from the model than can be inferred by an adversary without access to the trained model, but with the same knowledge of the underlying distribution as needed to train the attribute inference attack; (2) black-box attribute inference attacks rarely learn anything that cannot be learned without the model; but (3) white-box attacks, which we introduce and evaluate in the paper, can reliably identify some records with the sensitive value attribute that would not be predicted without having access to the model. Furthermore, we show that proposed defenses such as differentially private training and removing vulnerable records from training do not mitigate this privacy risk. The code for our experiments is available at \url{https://github.com/bargavj/EvaluatingDPML}.
Active Data Pattern Extraction Attacks on Generative Language Models
Jul 14, 2022
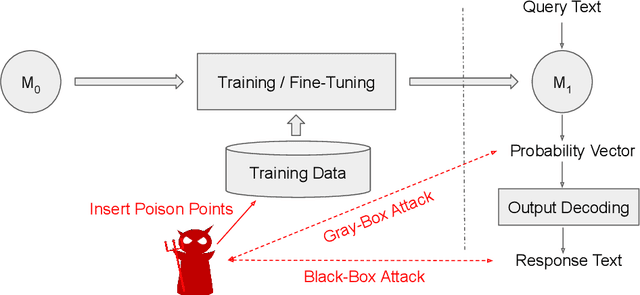

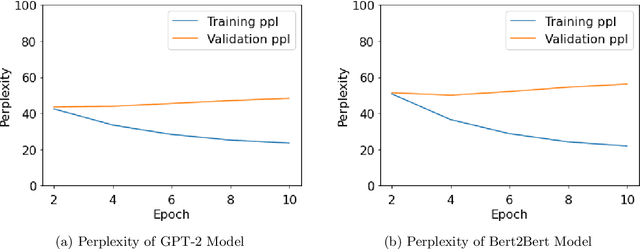
With the wide availability of large pre-trained language model checkpoints, such as GPT-2 and BERT, the recent trend has been to fine-tune them on a downstream task to achieve the state-of-the-art performance with a small computation overhead. One natural example is the Smart Reply application where a pre-trained model is fine-tuned for suggesting a number of responses given a query message. In this work, we set out to investigate potential information leakage vulnerabilities in a typical Smart Reply pipeline and show that it is possible for an adversary, having black-box or gray-box access to a Smart Reply model, to extract sensitive user information present in the training data. We further analyse the privacy impact of specific components, e.g. the decoding strategy, pertained to this application through our attack settings. We explore potential mitigation strategies and demonstrate how differential privacy can be a strong defense mechanism to such data extraction attacks.
Revisiting Membership Inference Under Realistic Assumptions
Jun 21, 2020
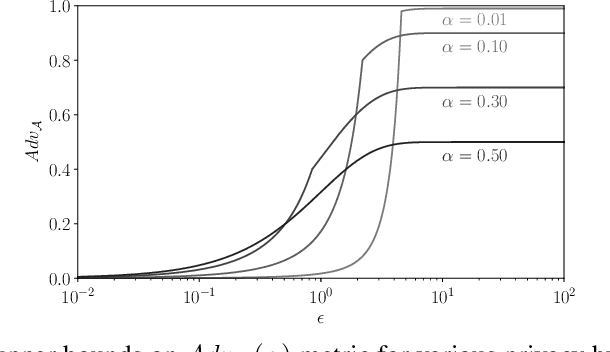
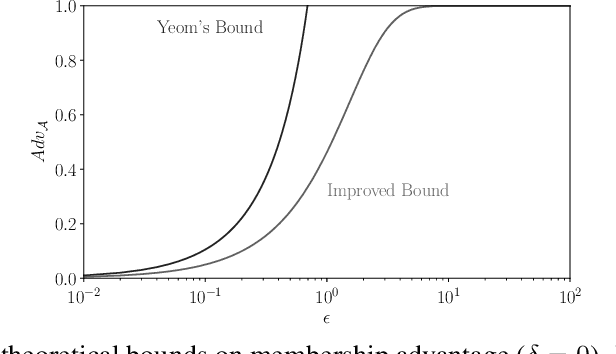

Membership inference attacks on models trained using machine learning have been shown to pose significant privacy risks. However, previous works on membership inference assume a balanced prior distribution where the adversary randomly chooses target records from a pool that has equal numbers of members and non-members. Such an assumption of balanced prior is unrealistic in practical scenarios. This paper studies membership inference attacks under more realistic assumptions. First, we consider skewed priors where a non-member is more likely to occur than a member record. For this, we use metric based on positive predictive value (PPV) in conjunction with membership advantage for privacy leakage evaluation, since PPV considers the prior. Second, we consider adversaries that can select inference thresholds according to their attack goals. For this, we develop a threshold selection procedure that improves inference attacks. We also propose a new membership inference attack called Merlin which outperforms previous attacks. Our experimental evaluation shows that while models trained without privacy mechanisms are vulnerable to membership inference attacks in balanced prior settings, there appears to be negligible privacy risk in the skewed prior setting. Code for our experiments can be found here: https://github.com/bargavj/EvaluatingDPML.
Efficient Privacy-Preserving Nonconvex Optimization
Oct 30, 2019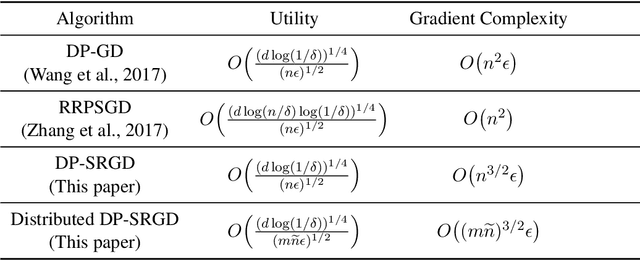
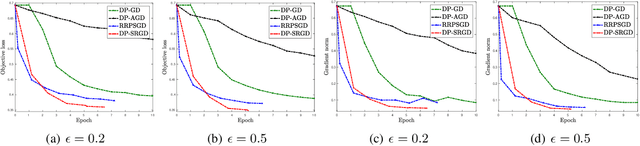
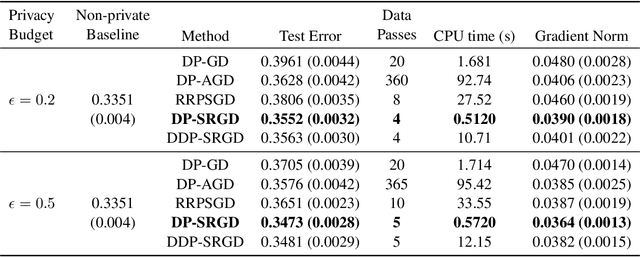
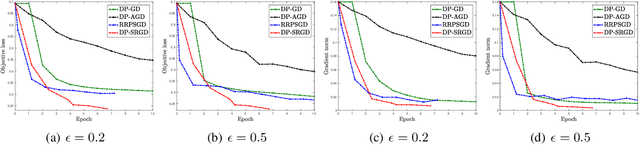
While many solutions for privacy-preserving convex empirical risk minimization (ERM) have been developed, privacy-preserving nonconvex ERM remains under challenging. In this paper, we study nonconvex ERM, which takes the form of minimizing a finite-sum of nonconvex loss functions over a training set. To achieve both efficiency and strong privacy guarantees with efficiency, we propose a differentially-private stochastic gradient descent algorithm for nonconvex ERM, and provide a tight analysis of its privacy and utility guarantees, as well as its gradient complexity. We show that our proposed algorithm can substantially reduce gradient complexity while matching the best-known utility guarantee obtained by Wang et al. (2017). We extend our algorithm to the distributed setting using secure multi-party computation, and show that it is possible for a distributed algorithm to match the privacy and utility guarantees of a centralized algorithm in this setting. Our experiments on benchmark nonconvex ERM problems and real datasets demonstrate superior performance in terms of both training time and utility gains compared with previous differentially-private methods using the same privacy budgets.
When Relaxations Go Bad: "Differentially-Private" Machine Learning
Mar 01, 2019
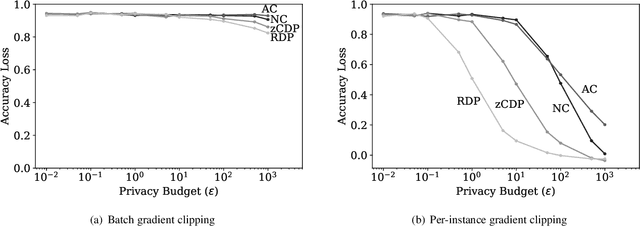
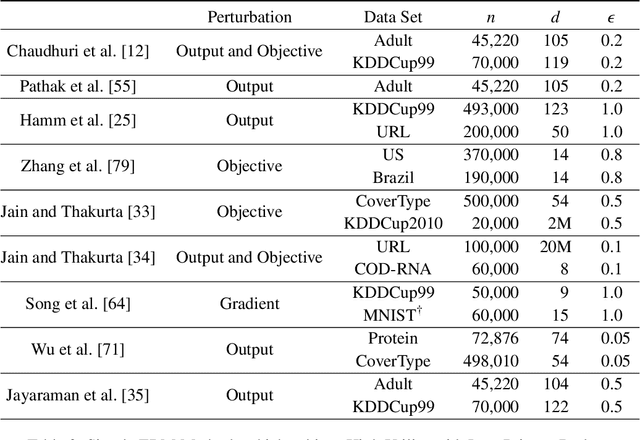
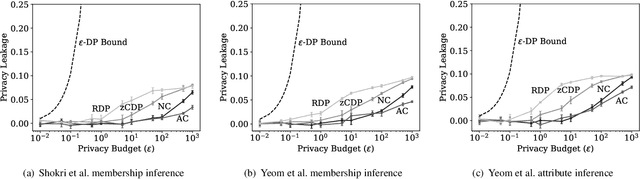
Differential privacy is becoming a standard notion for performing privacy-preserving machine learning over sensitive data. It provides formal guarantees, in terms of the privacy budget, $\epsilon$, on how much information about individual training records is leaked by the model. While the privacy budget is directly correlated to the privacy leakage, the calibration of the privacy budget is not well understood. As a result, many existing works on privacy-preserving machine learning select large values of $\epsilon$ in order to get acceptable utility of the model, with little understanding of the concrete impact of such choices on meaningful privacy. Moreover, in scenarios where iterative learning procedures are used which require privacy guarantees for each iteration, relaxed definitions of differential privacy are often used which further tradeoff privacy for better utility. In this paper, we evaluate the impacts of these choices on privacy in experiments with logistic regression and neural network models. We quantify the privacy leakage in terms of advantage of the adversary performing inference attacks and by analyzing the number of members at risk for exposure. Our main findings are that current mechanisms for differential privacy for machine learning rarely offer acceptable utility-privacy tradeoffs: settings that provide limited accuracy loss provide little effective privacy, and settings that provide strong privacy result in useless models. Open source code is available at https://github.com/bargavj/EvaluatingDPML.