 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Attribute Inference Attacks Just Imputation?
Paper and Code
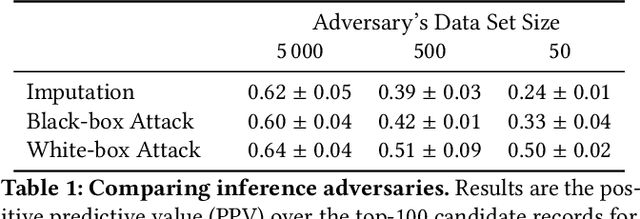
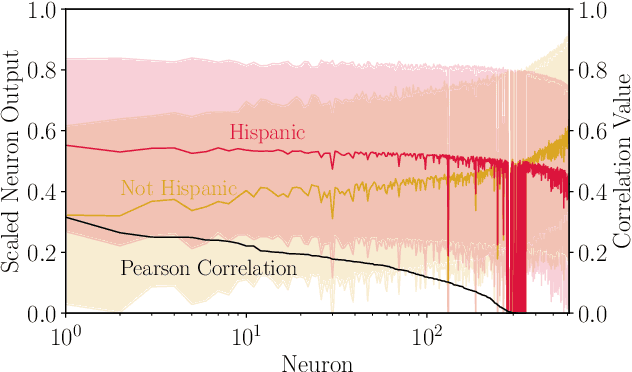
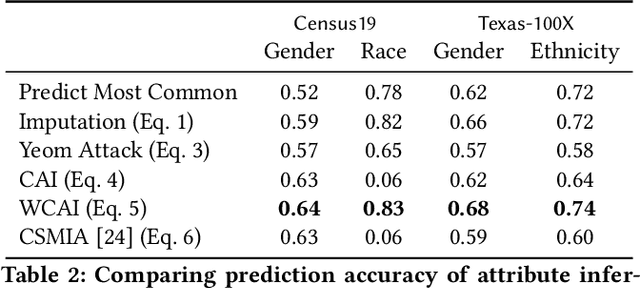
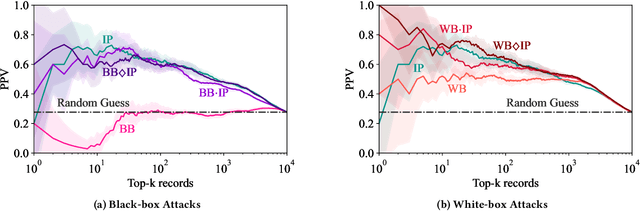
Models can expose sensitive information about their training data. In an attribute inference attack, an adversary has partial knowledge of some training records and access to a model trained on those records, and infers the unknown values of a sensitive feature of those records. We study a fine-grained variant of attribute inference we call \emph{sensitive value inference}, where the adversary's goal is to identify with high confidence some records from a candidate set where the unknown attribute has a particular sensitive value. We explicitly compare attribute inference with data imputation that captures the training distribution statistics, under various assumptions about the training data available to the adversary. Our main conclusions are: (1) previous attribute inference methods do not reveal more about the training data from the model than can be inferred by an adversary without access to the trained model, but with the same knowledge of the underlying distribution as needed to train the attribute inference attack; (2) black-box attribute inference attacks rarely learn anything that cannot be learned without the model; but (3) white-box attacks, which we introduce and evaluate in the paper, can reliably identify some records with the sensitive value attribute that would not be predicted without having access to the model. Furthermore, we show that proposed defenses such as differentially private training and removing vulnerable records from training do not mitigate this privacy risk. The code for our experiments is available at \url{https://github.com/bargavj/EvaluatingDPML}.