 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Criticality in Large Language Model Temperature Scaling
Jun 04, 2026We propose a statistical-field framework for text generated by large language models (LLMs), treating token embeddings as continuous spin variables on a one-dimensional chain. Defining a susceptibility from the connected two-point correlator and an order parameter from the ensemble-averaged embedding field, we vary the \texttt{softmax} temperature $T$ and observe a sharp susceptibility peak near a characteristic $T_c$ with power-law-like scaling, a concurrent rapid change in the order parameter, and a collapse onto a single semantic direction below $T_c$. The intrinsic dimension estimated by the two nearest neighbor (TwoNN) method independently corroborates these findings, reaching a minimum near $T_c$. Results are robust across model scales (Qwen3: 0.6B--32B) and prompt categories. While the phenomenology closely resembles a continuous phase transition, the non-equilibrium nature of autoregressive generation warrants further investigation. Our framework provides quantitative tools for probing the collective statistical structure of LLM outputs and suggests connections between decoding strategies and critical phenomena.
Generalizable Equivariant Diffusion Models for Non-Abelian Lattice Gauge Theory
Jan 27, 2026We demonstrate that gauge equivariant diffusion models can accurately model the physics of non-Abelian lattice gauge theory using the Metropolis-adjusted annealed Langevin algorithm (MAALA), as exemplified by computations in two-dimensional U(2) and SU(2) gauge theories. Our network architecture is based on lattice gauge equivariant convolutional neural networks (L-CNNs), which respect local and global symmetries on the lattice. Models are trained on a single ensemble generated using a traditional Monte Carlo method. By studying Wilson loops of various size as well as the topological susceptibility, we find that the diffusion approach generalizes remarkably well to larger inverse couplings and lattice sizes with negligible loss of accuracy while retaining moderately high acceptance rates.
Personalized Federated Training of Diffusion Models with Privacy Guarantees
Apr 01, 2025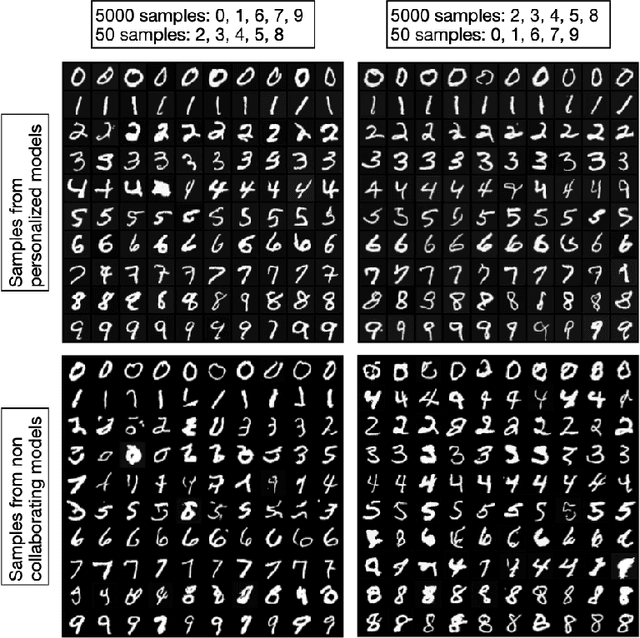
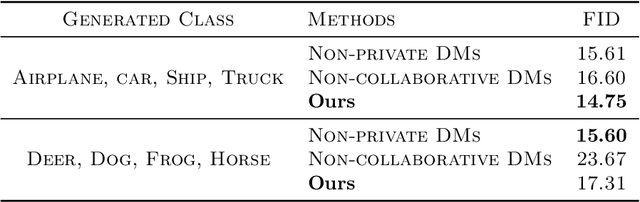


The scarcity of accessible, compliant, and ethically sourced data presents a considerable challenge to the adoption of artificial intelligence (AI) in sensitive fields like healthcare, finance, and biomedical research. Furthermore, access to unrestricted public datasets is increasingly constrained due to rising concerns over privacy, copyright, and competition. Synthetic data has emerged as a promising alternative, and diffusion models -- a cutting-edge generative AI technology -- provide an effective solution for generating high-quality and diverse synthetic data. In this paper, we introduce a novel federated learning framework for training diffusion models on decentralized private datasets. Our framework leverages personalization and the inherent noise in the forward diffusion process to produce high-quality samples while ensuring robust differential privacy guarantees. Our experiments show that our framework outperforms non-collaborative training methods, particularly in settings with high data heterogeneity, and effectively reduces biases and imbalances in synthetic data, resulting in fairer downstream models.
Physics-Conditioned Diffusion Models for Lattice Gauge Theory
Feb 08, 2025



We develop diffusion models for simulating lattice gauge theories, where stochastic quantization is explicitly incorporated as a physical condition for sampling. We demonstrate the applicability of this novel sampler to U(1) gauge theory in two spacetime dimensions and find that a model trained at a small inverse coupling constant can be extrapolated to larger inverse coupling regions without encountering the topological freezing problem. Additionally, the trained model can be employed to sample configurations on different lattice sizes without requiring further training. The exactness of the generated samples is ensured by incorporating Metropolis-adjusted Langevin dynamics into the generation process. Furthermore, we demonstrate that this approach enables more efficient sampling of topological quantities compared to traditional algorithms such as Hybrid Monte Carlo and Langevin simulations.
Physics-Driven Learning for Inverse Problems in Quantum Chromodynamics
Jan 09, 2025The integration of deep learning techniques and physics-driven designs is reforming the way we address inverse problems, in which accurate physical properties are extracted from complex data sets. This is particularly relevant for quantum chromodynamics (QCD), the theory of strong interactions, with its inherent limitations in observational data and demanding computational approaches. This perspective highlights advances and potential of physics-driven learning methods, focusing on predictions of physical quantities towards QCD physics, and drawing connections to machine learning(ML). It is shown that the fusion of ML and physics can lead to more efficient and reliable problem-solving strategies. Key ideas of ML, methodology of embedding physics priors, and generative models as inverse modelling of physical probability distributions are introduced. Specific applications cover first-principle lattice calculations, and QCD physics of hadrons, neutron stars, and heavy-ion collisions. These examples provide a structured and concise overview of how incorporating prior knowledge such as symmetry, continuity and equations into deep learning designs can address diverse inverse problems across different physical sciences.
* 14 pages, 5 figures, submitted version to Nat Rev Phys
Diffusion models learn distributions generated by complex Langevin dynamics
Dec 02, 2024



The probability distribution effectively sampled by a complex Langevin process for theories with a sign problem is not known a priori and notoriously hard to understand. Diffusion models, a class of generative AI, can learn distributions from data. In this contribution, we explore the ability of diffusion models to learn the distributions created by a complex Langevin process.
On learning higher-order cumulants in diffusion models
Oct 28, 2024



To analyse how diffusion models learn correlations beyond Gaussian ones, we study the behaviour of higher-order cumulants, or connected n-point functions, under both the forward and backward process. We derive explicit expressions for the moment- and cumulant-generating functionals, in terms of the distribution of the initial data and properties of forward process. It is shown analytically that during the forward process higher-order cumulants are conserved in models without a drift, such as the variance-expanding scheme, and that therefore the endpoint of the forward process maintains nontrivial correlations. We demonstrate that since these correlations are encoded in the score function, higher-order cumulants are learnt in the backward process, also when starting from a normal prior. We confirm our analytical results in an exactly solvable toy model with nonzero cumulants and in scalar lattice field theory.
The Limits and Potentials of Local SGD for Distributed Heterogeneous Learning with Intermittent Communication
May 19, 2024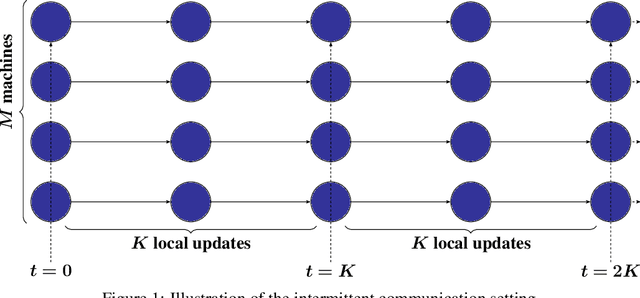

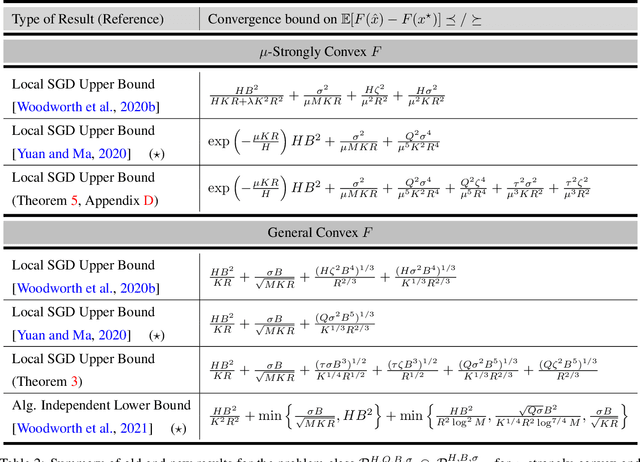
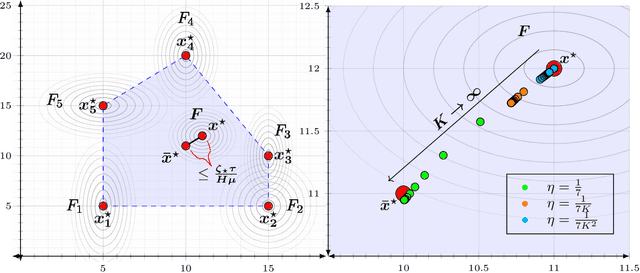
Local SGD is a popular optimization method in distributed learning, often outperforming other algorithms in practice, including mini-batch SGD. Despite this success, theoretically proving the dominance of local SGD in settings with reasonable data heterogeneity has been difficult, creating a significant gap between theory and practice. In this paper, we provide new lower bounds for local SGD under existing first-order data heterogeneity assumptions, showing that these assumptions are insufficient to prove the effectiveness of local update steps. Furthermore, under these same assumptions, we demonstrate the min-max optimality of accelerated mini-batch SGD, which fully resolves our understanding of distributed optimization for several problem classes. Our results emphasize the need for better models of data heterogeneity to understand the effectiveness of local SGD in practice. Towards this end, we consider higher-order smoothness and heterogeneity assumptions, providing new upper bounds that imply the dominance of local SGD over mini-batch SGD when data heterogeneity is low.
Pessimistic Value Iteration for Multi-Task Data Sharing in Offline Reinforcement Learning
Apr 30, 2024Offline Reinforcement Learning (RL) has shown promising results in learning a task-specific policy from a fixed dataset. However, successful offline RL often relies heavily on the coverage and quality of the given dataset. In scenarios where the dataset for a specific task is limited, a natural approach is to improve offline RL with datasets from other tasks, namely, to conduct Multi-Task Data Sharing (MTDS). Nevertheless, directly sharing datasets from other tasks exacerbates the distribution shift in offline RL. In this paper, we propose an uncertainty-based MTDS approach that shares the entire dataset without data selection. Given ensemble-based uncertainty quantification, we perform pessimistic value iteration on the shared offline dataset, which provides a unified framework for single- and multi-task offline RL. We further provide theoretical analysis, which shows that the optimality gap of our method is only related to the expected data coverage of the shared dataset, thus resolving the distribution shift issue in data sharing. Empirically, we release an MTDS benchmark and collect datasets from three challenging domains. The experimental results show our algorithm outperforms the previous state-of-the-art methods in challenging MTDS problems. See https://github.com/Baichenjia/UTDS for the datasets and code.
Federated Online and Bandit Convex Optimization
Nov 29, 2023We study the problems of distributed online and bandit convex optimization against an adaptive adversary. We aim to minimize the average regret on $M$ machines working in parallel over $T$ rounds with $R$ intermittent communications. Assuming the underlying cost functions are convex and can be generated adaptively, our results show that collaboration is not beneficial when the machines have access to the first-order gradient information at the queried points. This is in contrast to the case for stochastic functions, where each machine samples the cost functions from a fixed distribution. Furthermore, we delve into the more challenging setting of federated online optimization with bandit (zeroth-order) feedback, where the machines can only access values of the cost functions at the queried points. The key finding here is identifying the high-dimensional regime where collaboration is beneficial and may even lead to a linear speedup in the number of machines. We further illustrate our findings through federated adversarial linear bandits by developing novel distributed single and two-point feedback algorithms. Our work is the first attempt towards a systematic understanding of federated online optimization with limited feedback, and it attains tight regret bounds in the intermittent communication setting for both first and zeroth-order feedback. Our results thus bridge the gap between stochastic and adaptive settings in federated online optimization.