 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Kernel Approach for Semi-implicit Variational Inference
Jan 17, 2026Semi-implicit variational inference (SIVI) enhances the expressiveness of variational families through hierarchical semi-implicit distributions, but the intractability of their densities makes standard ELBO-based optimization biased. Recent score-matching approaches to SIVI (SIVI-SM) address this issue via a minimax formulation, at the expense of an additional lower-level optimization problem. In this paper, we propose kernel semi-implicit variational inference (KSIVI), a principled and tractable alternative that eliminates the lower-level optimization by leveraging kernel methods. We show that when optimizing over a reproducing kernel Hilbert space, the lower-level problem admits an explicit solution, reducing the objective to the kernel Stein discrepancy (KSD). Exploiting the hierarchical structure of semi-implicit distributions, the resulting KSD objective can be efficiently optimized using stochastic gradient methods. We establish optimization guarantees via variance bounds on Monte Carlo gradient estimators and derive statistical generalization bounds of order $\tilde{\mathcal{O}}(1/\sqrt{n})$. We further introduce a multi-layer hierarchical extension that improves expressiveness while preserving tractability. Empirical results on synthetic and real-world Bayesian inference tasks demonstrate the effectiveness of KSIVI.
OVERT: A Benchmark for Over-Refusal Evaluation on Text-to-Image Models
May 28, 2025Text-to-Image (T2I) models have achieved remarkable success in generating visual content from text inputs. Although multiple safety alignment strategies have been proposed to prevent harmful outputs, they often lead to overly cautious behavior -- rejecting even benign prompts -- a phenomenon known as $\textit{over-refusal}$ that reduces the practical utility of T2I models. Despite over-refusal having been observed in practice, there is no large-scale benchmark that systematically evaluates this phenomenon for T2I models. In this paper, we present an automatic workflow to construct synthetic evaluation data, resulting in OVERT ($\textbf{OVE}$r-$\textbf{R}$efusal evaluation on $\textbf{T}$ext-to-image models), the first large-scale benchmark for assessing over-refusal behaviors in T2I models. OVERT includes 4,600 seemingly harmful but benign prompts across nine safety-related categories, along with 1,785 genuinely harmful prompts (OVERT-unsafe) to evaluate the safety-utility trade-off. Using OVERT, we evaluate several leading T2I models and find that over-refusal is a widespread issue across various categories (Figure 1), underscoring the need for further research to enhance the safety alignment of T2I models without compromising their functionality. As a preliminary attempt to reduce over-refusal, we explore prompt rewriting; however, we find it often compromises faithfulness to the meaning of the original prompts. Finally, we demonstrate the flexibility of our generation framework in accommodating diverse safety requirements by generating customized evaluation data adapting to user-defined policies.
Provable Sample-Efficient Transfer Learning Conditional Diffusion Models via Representation Learning
Feb 06, 2025While conditional diffusion models have achieved remarkable success in various applications, they require abundant data to train from scratch, which is often infeasible in practice. To address this issue, transfer learning has emerged as an essential paradigm in small data regimes. Despite its empirical success, the theoretical underpinnings of transfer learning conditional diffusion models remain unexplored. In this paper, we take the first step towards understanding the sample efficiency of transfer learning conditional diffusion models through the lens of representation learning. Inspired by practical training procedures, we assume that there exists a low-dimensional representation of conditions shared across all tasks. Our analysis shows that with a well-learned representation from source tasks, the samplecomplexity of target tasks can be reduced substantially. In addition, we investigate the practical implications of our theoretical results in several real-world applications of conditional diffusion models. Numerical experiments are also conducted to verify our results.
Functional Gradient Flows for Constrained Sampling
Oct 30, 2024Recently, through a unified gradient flow perspective of Markov chain Monte Carlo (MCMC) and variational inference (VI), particle-based variational inference methods (ParVIs) have been proposed that tend to combine the best of both worlds. While typical ParVIs such as Stein Variational Gradient Descent (SVGD) approximate the gradient flow within a reproducing kernel Hilbert space (RKHS), many attempts have been made recently to replace RKHS with more expressive function spaces, such as neural networks. While successful, these methods are mainly designed for sampling from unconstrained domains. In this paper, we offer a general solution to constrained sampling by introducing a boundary condition for the gradient flow which would confine the particles within the specific domain. This allows us to propose a new functional gradient ParVI method for constrained sampling, called constrained functional gradient flow (CFG), with provable continuous-time convergence in total variation (TV). We also present novel numerical strategies to handle the boundary integral term arising from the domain constraints. Our theory and experiments demonstrate the effectiveness of the proposed framework.
Semi-Implicit Functional Gradient Flow
Oct 23, 2024


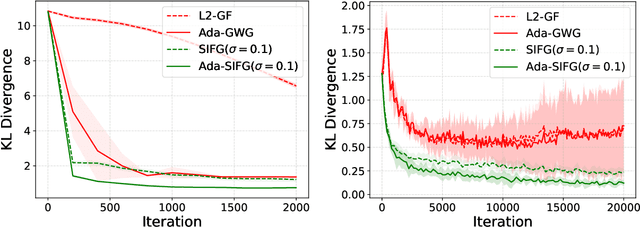
Particle-based variational inference methods (ParVIs) use non-parametric variational families represented by particles to approximate the target distribution according to the kernelized Wasserstein gradient flow for the Kullback-Leibler (KL) divergence. Recent works introduce functional gradient flows to substitute the kernel for better flexibility. However, the deterministic updating mechanism may suffer from limited exploration and require expensive repetitive runs for new samples. In this paper, we propose Semi-Implicit Functional Gradient flow (SIFG), a functional gradient ParVI method that uses perturbed particles as the approximation family. The corresponding functional gradient flow, which can be estimated via denoising score matching, exhibits strong theoretical convergence guarantee. We also present an adaptive version of our method to automatically choose the suitable noise magnitude. Extensive experiments demonstrate the effectiveness and efficiency of the proposed framework on both simulated and real data problems.
Kernel Semi-Implicit Variational Inference
May 29, 2024Semi-implicit variational inference (SIVI) extends traditional variational families with semi-implicit distributions defined in a hierarchical manner. Due to the intractable densities of semi-implicit distributions, classical SIVI often resorts to surrogates of evidence lower bound (ELBO) that would introduce biases for training. A recent advancement in SIVI, named SIVI-SM, utilizes an alternative score matching objective made tractable via a minimax formulation, albeit requiring an additional lower-level optimization. In this paper, we propose kernel SIVI (KSIVI), a variant of SIVI-SM that eliminates the need for lower-level optimization through kernel tricks. Specifically, we show that when optimizing over a reproducing kernel Hilbert space (RKHS), the lower-level problem has an explicit solution. This way, the upper-level objective becomes the kernel Stein discrepancy (KSD), which is readily computable for stochastic gradient descent due to the hierarchical structure of semi-implicit variational distributions. An upper bound for the variance of the Monte Carlo gradient estimators of the KSD objective is derived, which allows us to establish novel convergence guarantees of KSIVI. We demonstrate the effectiveness and efficiency of KSIVI on both synthetic distributions and a variety of real data Bayesian inference tasks.
Reflected Flow Matching
May 26, 2024Continuous normalizing flows (CNFs) learn an ordinary differential equation to transform prior samples into data. Flow matching (FM) has recently emerged as a simulation-free approach for training CNFs by regressing a velocity model towards the conditional velocity field. However, on constrained domains, the learned velocity model may lead to undesirable flows that result in highly unnatural samples, e.g., oversaturated images, due to both flow matching error and simulation error. To address this, we add a boundary constraint term to CNFs, which leads to reflected CNFs that keep trajectories within the constrained domains. We propose reflected flow matching (RFM) to train the velocity model in reflected CNFs by matching the conditional velocity fields in a simulation-free manner, similar to the vanilla FM. Moreover, the analytical form of conditional velocity fields in RFM avoids potentially biased approximations, making it superior to existing score-based generative models on constrained domains. We demonstrate that RFM achieves comparable or better results on standard image benchmarks and produces high-quality class-conditioned samples under high guidance weight.
The Limits and Potentials of Local SGD for Distributed Heterogeneous Learning with Intermittent Communication
May 19, 2024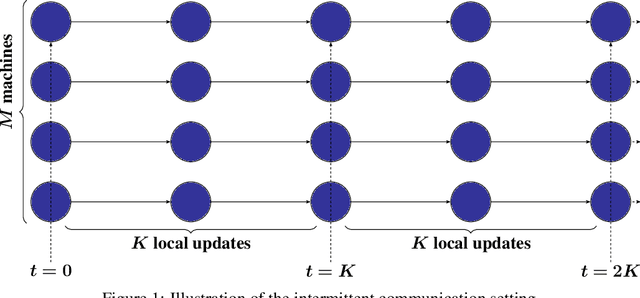

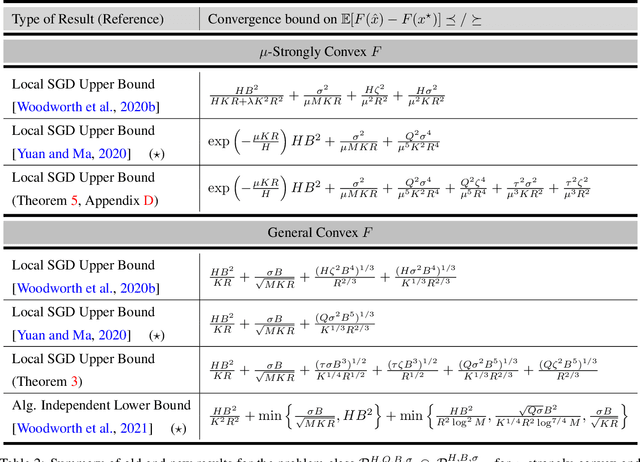
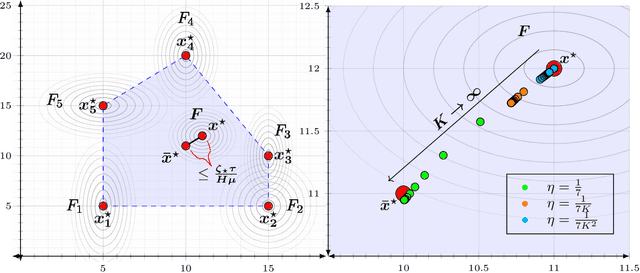
Local SGD is a popular optimization method in distributed learning, often outperforming other algorithms in practice, including mini-batch SGD. Despite this success, theoretically proving the dominance of local SGD in settings with reasonable data heterogeneity has been difficult, creating a significant gap between theory and practice. In this paper, we provide new lower bounds for local SGD under existing first-order data heterogeneity assumptions, showing that these assumptions are insufficient to prove the effectiveness of local update steps. Furthermore, under these same assumptions, we demonstrate the min-max optimality of accelerated mini-batch SGD, which fully resolves our understanding of distributed optimization for several problem classes. Our results emphasize the need for better models of data heterogeneity to understand the effectiveness of local SGD in practice. Towards this end, we consider higher-order smoothness and heterogeneity assumptions, providing new upper bounds that imply the dominance of local SGD over mini-batch SGD when data heterogeneity is low.
SnapCap: Efficient Snapshot Compressive Video Captioning
Jan 10, 2024Video Captioning (VC) is a challenging multi-modal task since it requires describing the scene in language by understanding various and complex videos. For machines, the traditional VC follows the "imaging-compression-decoding-and-then-captioning" pipeline, where compression is pivot for storage and transmission. However, in such a pipeline, some potential shortcomings are inevitable, i.e., information redundancy resulting in low efficiency and information loss during the sampling process for captioning. To address these problems, in this paper, we propose a novel VC pipeline to generate captions directly from the compressed measurement, which can be captured by a snapshot compressive sensing camera and we dub our model SnapCap. To be more specific, benefiting from the signal simulation, we have access to obtain abundant measurement-video-annotation data pairs for our model. Besides, to better extract language-related visual representations from the compressed measurement, we propose to distill the knowledge from videos via a pre-trained CLIP with plentiful language-vision associations to guide the learning of our SnapCap. To demonstrate the effectiveness of SnapCap, we conduct experiments on two widely-used VC datasets. Both the qualitative and quantitative results verify the superiority of our pipeline over conventional VC pipelines. In particular, compared to the "caption-after-reconstruction" methods, our SnapCap can run at least 3$\times$ faster, and achieve better caption results.
Particle-based Variational Inference with Generalized Wasserstein Gradient Flow
Oct 25, 2023Particle-based variational inference methods (ParVIs) such as Stein variational gradient descent (SVGD) update the particles based on the kernelized Wasserstein gradient flow for the Kullback-Leibler (KL) divergence. However, the design of kernels is often non-trivial and can be restrictive for the flexibility of the method. Recent works show that functional gradient flow approximations with quadratic form regularization terms can improve performance. In this paper, we propose a ParVI framework, called generalized Wasserstein gradient descent (GWG), based on a generalized Wasserstein gradient flow of the KL divergence, which can be viewed as a functional gradient method with a broader class of regularizers induced by convex functions. We show that GWG exhibits strong convergence guarantees. We also provide an adaptive version that automatically chooses Wasserstein metric to accelerate convergence. In experiments, we demonstrate the effectiveness and efficiency of the proposed framework on both simulated and real data problems.