 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Fine-Grained Visual-Concept Relations by Disentangled Optimal Transport Concept Bottleneck Models
May 12, 2025



Concept Bottleneck Models (CBMs) try to make the decision-making process transparent by exploring an intermediate concept space between the input image and the output prediction. Existing CBMs just learn coarse-grained relations between the whole image and the concepts, less considering local image information, leading to two main drawbacks: i) they often produce spurious visual-concept relations, hence decreasing model reliability; and ii) though CBMs could explain the importance of every concept to the final prediction, it is still challenging to tell which visual region produces the prediction. To solve these problems, this paper proposes a Disentangled Optimal Transport CBM (DOT-CBM) framework to explore fine-grained visual-concept relations between local image patches and concepts. Specifically, we model the concept prediction process as a transportation problem between the patches and concepts, thereby achieving explicit fine-grained feature alignment. We also incorporate orthogonal projection losses within the modality to enhance local feature disentanglement. To further address the shortcut issues caused by statistical biases in the data, we utilize the visual saliency map and concept label statistics as transportation priors. Thus, DOT-CBM can visualize inversion heatmaps, provide more reliable concept predictions, and produce more accurate class predictions. Comprehensive experiments demonstrate that our proposed DOT-CBM achieves SOTA performance on several tasks, including image classification, local part detection and out-of-distribution generalization.
Beyond Matryoshka: Revisiting Sparse Coding for Adaptive Representation
Mar 05, 2025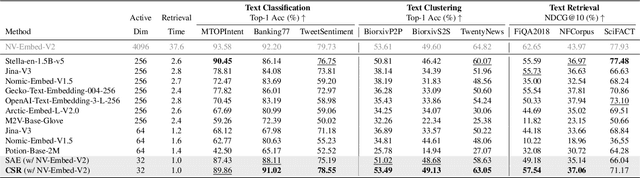
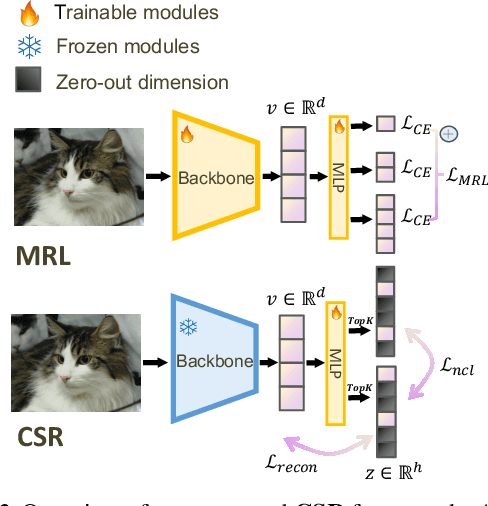
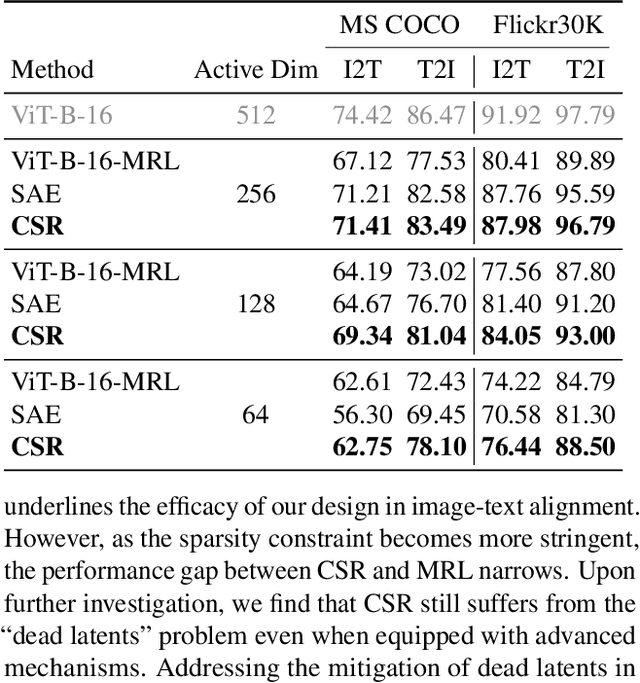
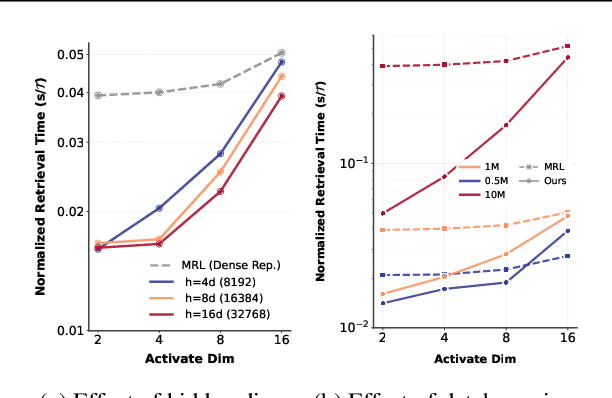
Many large-scale systems rely on high-quality deep representations (embeddings) to facilitate tasks like retrieval, search, and generative modeling. Matryoshka Representation Learning (MRL) recently emerged as a solution for adaptive embedding lengths, but it requires full model retraining and suffers from noticeable performance degradations at short lengths. In this paper, we show that sparse coding offers a compelling alternative for achieving adaptive representation with minimal overhead and higher fidelity. We propose Contrastive Sparse Representation (CSR), a method that sparsifies pre-trained embeddings into a high-dimensional but selectively activated feature space. By leveraging lightweight autoencoding and task-aware contrastive objectives, CSR preserves semantic quality while allowing flexible, cost-effective inference at different sparsity levels. Extensive experiments on image, text, and multimodal benchmarks demonstrate that CSR consistently outperforms MRL in terms of both accuracy and retrieval speed-often by large margins-while also cutting training time to a fraction of that required by MRL. Our results establish sparse coding as a powerful paradigm for adaptive representation learning in real-world applications where efficiency and fidelity are both paramount. Code is available at https://github.com/neilwen987/CSR_Adaptive_Rep
HICEScore: A Hierarchical Metric for Image Captioning Evaluation
Jul 26, 2024



Image captioning evaluation metrics can be divided into two categories, reference-based metrics and reference-free metrics. However, reference-based approaches may struggle to evaluate descriptive captions with abundant visual details produced by advanced multimodal large language models, due to their heavy reliance on limited human-annotated references. In contrast, previous reference-free metrics have been proven effective via CLIP cross-modality similarity. Nonetheless, CLIP-based metrics, constrained by their solution of global image-text compatibility, often have a deficiency in detecting local textual hallucinations and are insensitive to small visual objects. Besides, their single-scale designs are unable to provide an interpretable evaluation process such as pinpointing the position of caption mistakes and identifying visual regions that have not been described. To move forward, we propose a novel reference-free metric for image captioning evaluation, dubbed Hierarchical Image Captioning Evaluation Score (HICE-S). By detecting local visual regions and textual phrases, HICE-S builds an interpretable hierarchical scoring mechanism, breaking through the barriers of the single-scale structure of existing reference-free metrics. Comprehensive experiments indicate that our proposed metric achieves the SOTA performance on several benchmarks, outperforming existing reference-free metrics like CLIP-S and PAC-S, and reference-based metrics like METEOR and CIDEr. Moreover, several case studies reveal that the assessment process of HICE-S on detailed captions closely resembles interpretable human judgments.Our code is available at https://github.com/joeyz0z/HICE.
MeaCap: Memory-Augmented Zero-shot Image Captioning
Mar 06, 2024
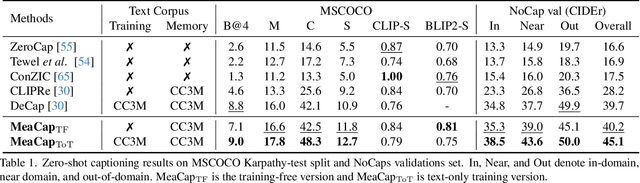
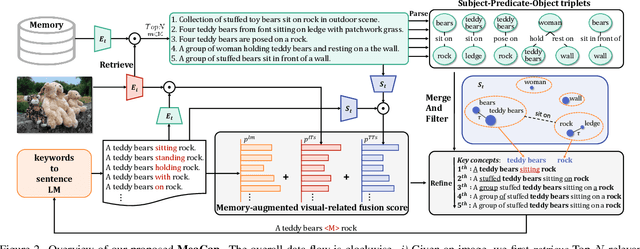

Zero-shot image captioning (IC) without well-paired image-text data can be divided into two categories, training-free and text-only-training. Generally, these two types of methods realize zero-shot IC by integrating pretrained vision-language models like CLIP for image-text similarity evaluation and a pre-trained language model (LM) for caption generation. The main difference between them is whether using a textual corpus to train the LM. Though achieving attractive performance w.r.t. some metrics, existing methods often exhibit some common drawbacks. Training-free methods tend to produce hallucinations, while text-only-training often lose generalization capability. To move forward, in this paper, we propose a novel Memory-Augmented zero-shot image Captioning framework (MeaCap). Specifically, equipped with a textual memory, we introduce a retrieve-then-filter module to get key concepts that are highly related to the image. By deploying our proposed memory-augmented visual-related fusion score in a keywords-to-sentence LM, MeaCap can generate concept-centered captions that keep high consistency with the image with fewer hallucinations and more world-knowledge. The framework of MeaCap achieves the state-of-the-art performance on a series of zero-shot IC settings. Our code is available at https://github.com/joeyz0z/MeaCap.
SnapCap: Efficient Snapshot Compressive Video Captioning
Jan 10, 2024Video Captioning (VC) is a challenging multi-modal task since it requires describing the scene in language by understanding various and complex videos. For machines, the traditional VC follows the "imaging-compression-decoding-and-then-captioning" pipeline, where compression is pivot for storage and transmission. However, in such a pipeline, some potential shortcomings are inevitable, i.e., information redundancy resulting in low efficiency and information loss during the sampling process for captioning. To address these problems, in this paper, we propose a novel VC pipeline to generate captions directly from the compressed measurement, which can be captured by a snapshot compressive sensing camera and we dub our model SnapCap. To be more specific, benefiting from the signal simulation, we have access to obtain abundant measurement-video-annotation data pairs for our model. Besides, to better extract language-related visual representations from the compressed measurement, we propose to distill the knowledge from videos via a pre-trained CLIP with plentiful language-vision associations to guide the learning of our SnapCap. To demonstrate the effectiveness of SnapCap, we conduct experiments on two widely-used VC datasets. Both the qualitative and quantitative results verify the superiority of our pipeline over conventional VC pipelines. In particular, compared to the "caption-after-reconstruction" methods, our SnapCap can run at least 3$\times$ faster, and achieve better caption results.
PatchCT: Aligning Patch Set and Label Set with Conditional Transport for Multi-Label Image Classification
Jul 18, 2023



Multi-label image classification is a prediction task that aims to identify more than one label from a given image. This paper considers the semantic consistency of the latent space between the visual patch and linguistic label domains and introduces the conditional transport (CT) theory to bridge the acknowledged gap. While recent cross-modal attention-based studies have attempted to align such two representations and achieved impressive performance, they required carefully-designed alignment modules and extra complex operations in the attention computation. We find that by formulating the multi-label classification as a CT problem, we can exploit the interactions between the image and label efficiently by minimizing the bidirectional CT cost. Specifically, after feeding the images and textual labels into the modality-specific encoders, we view each image as a mixture of patch embeddings and a mixture of label embeddings, which capture the local region features and the class prototypes, respectively. CT is then employed to learn and align those two semantic sets by defining the forward and backward navigators. Importantly, the defined navigators in CT distance model the similarities between patches and labels, which provides an interpretable tool to visualize the learned prototypes. Extensive experiments on three public image benchmarks show that the proposed model consistently outperforms the previous methods. Our code is available at https://github.com/keepgoingjkg/PatchCT.
ConZIC: Controllable Zero-shot Image Captioning by Sampling-Based Polishing
Mar 09, 2023

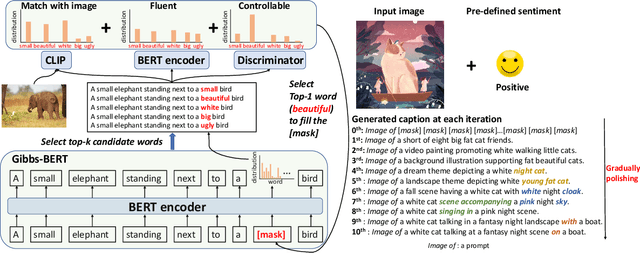

Zero-shot capability has been considered as a new revolution of deep learning, letting machines work on tasks without curated training data. As a good start and the only existing outcome of zero-shot image captioning (IC), ZeroCap abandons supervised training and sequentially searches every word in the caption using the knowledge of large-scale pretrained models. Though effective, its autoregressive generation and gradient-directed searching mechanism limit the diversity of captions and inference speed, respectively. Moreover, ZeroCap does not consider the controllability issue of zero-shot IC. To move forward, we propose a framework for Controllable Zero-shot IC, named ConZIC. The core of ConZIC is a novel sampling-based non-autoregressive language model named GibbsBERT, which can generate and continuously polish every word. Extensive quantitative and qualitative results demonstrate the superior performance of our proposed ConZIC for both zero-shot IC and controllable zero-shot IC. Especially, ConZIC achieves about 5x faster generation speed than ZeroCap, and about 1.5x higher diversity scores, with accurate generation given different control signals.
Matching Visual Features to Hierarchical Semantic Topics for Image Paragraph Captioning
May 10, 2021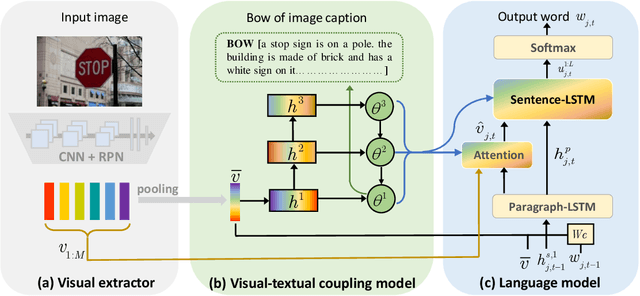
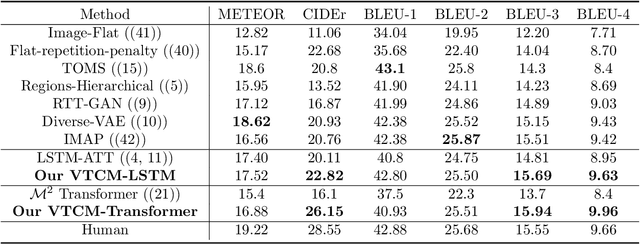
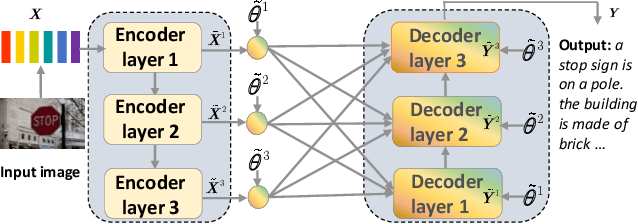
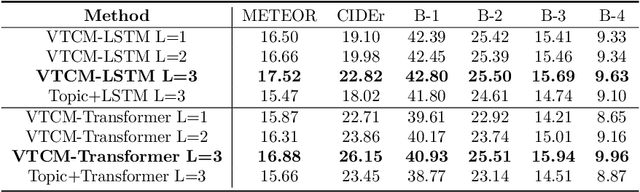
Observing a set of images and their corresponding paragraph-captions, a challenging task is to learn how to produce a semantically coherent paragraph to describe the visual content of an image. Inspired by recent successes in integrating semantic topics into this task, this paper develops a plug-and-play hierarchical-topic-guided image paragraph generation framework, which couples a visual extractor with a deep topic model to guide the learning of a language model. To capture the correlations between the image and text at multiple levels of abstraction and learn the semantic topics from images, we design a variational inference network to build the mapping from image features to textual captions. To guide the paragraph generation, the learned hierarchical topics and visual features are integrated into the language model, including Long Short-Term Memory (LSTM) and Transformer, and jointly optimized. Experiments on public dataset demonstrate that the proposed models, which are competitive with many state-of-the-art approaches in terms of standard evaluation metrics, can be used to both distill interpretable multi-layer topics and generate diverse and coherent captions.