 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePDR: A Plug-and-Play Positional Decay Framework for LLM Pre-training Data Detection
Jan 11, 2026Detecting pre-training data in Large Language Models (LLMs) is crucial for auditing data privacy and copyright compliance, yet it remains challenging in black-box, zero-shot settings where computational resources and training data are scarce. While existing likelihood-based methods have shown promise, they typically aggregate token-level scores using uniform weights, thereby neglecting the inherent information-theoretic dynamics of autoregressive generation. In this paper, we hypothesize and empirically validate that memorization signals are heavily skewed towards the high-entropy initial tokens, where model uncertainty is highest, and decay as context accumulates. To leverage this linguistic property, we introduce Positional Decay Reweighting (PDR), a training-free and plug-and-play framework. PDR explicitly reweights token-level scores to amplify distinct signals from early positions while suppressing noise from later ones. Extensive experiments show that PDR acts as a robust prior and can usually enhance a wide range of advanced methods across multiple benchmarks.
Latent Diffusion Prior Enhanced Deep Unfolding for Spectral Image Reconstruction
Nov 24, 2023Snapshot compressive spectral imaging reconstruction aims to reconstruct three-dimensional spatial-spectral images from a single-shot two-dimensional compressed measurement. Existing state-of-the-art methods are mostly based on deep unfolding structures but have intrinsic performance bottlenecks: $i$) the ill-posed problem of dealing with heavily degraded measurement, and $ii$) the regression loss-based reconstruction models being prone to recover images with few details. In this paper, we introduce a generative model, namely the latent diffusion model (LDM), to generate degradation-free prior to enhance the regression-based deep unfolding method. Furthermore, to overcome the large computational cost challenge in LDM, we propose a lightweight model to generate knowledge priors in deep unfolding denoiser, and integrate these priors to guide the reconstruction process for compensating high-quality spectral signal details. Numeric and visual comparisons on synthetic and real-world datasets illustrate the superiority of our proposed method in both reconstruction quality and computational efficiency. Code will be released.
Hierarchical Vector Quantized Transformer for Multi-class Unsupervised Anomaly Detection
Oct 22, 2023



Unsupervised image Anomaly Detection (UAD) aims to learn robust and discriminative representations of normal samples. While separate solutions per class endow expensive computation and limited generalizability, this paper focuses on building a unified framework for multiple classes. Under such a challenging setting, popular reconstruction-based networks with continuous latent representation assumption always suffer from the "identical shortcut" issue, where both normal and abnormal samples can be well recovered and difficult to distinguish. To address this pivotal issue, we propose a hierarchical vector quantized prototype-oriented Transformer under a probabilistic framework. First, instead of learning the continuous representations, we preserve the typical normal patterns as discrete iconic prototypes, and confirm the importance of Vector Quantization in preventing the model from falling into the shortcut. The vector quantized iconic prototype is integrated into the Transformer for reconstruction, such that the abnormal data point is flipped to a normal data point.Second, we investigate an exquisite hierarchical framework to relieve the codebook collapse issue and replenish frail normal patterns. Third, a prototype-oriented optimal transport method is proposed to better regulate the prototypes and hierarchically evaluate the abnormal score. By evaluating on MVTec-AD and VisA datasets, our model surpasses the state-of-the-art alternatives and possesses good interpretability. The code is available at https://github.com/RuiyingLu/HVQ-Trans.
PatchCT: Aligning Patch Set and Label Set with Conditional Transport for Multi-Label Image Classification
Jul 18, 2023



Multi-label image classification is a prediction task that aims to identify more than one label from a given image. This paper considers the semantic consistency of the latent space between the visual patch and linguistic label domains and introduces the conditional transport (CT) theory to bridge the acknowledged gap. While recent cross-modal attention-based studies have attempted to align such two representations and achieved impressive performance, they required carefully-designed alignment modules and extra complex operations in the attention computation. We find that by formulating the multi-label classification as a CT problem, we can exploit the interactions between the image and label efficiently by minimizing the bidirectional CT cost. Specifically, after feeding the images and textual labels into the modality-specific encoders, we view each image as a mixture of patch embeddings and a mixture of label embeddings, which capture the local region features and the class prototypes, respectively. CT is then employed to learn and align those two semantic sets by defining the forward and backward navigators. Importantly, the defined navigators in CT distance model the similarities between patches and labels, which provides an interpretable tool to visualize the learned prototypes. Extensive experiments on three public image benchmarks show that the proposed model consistently outperforms the previous methods. Our code is available at https://github.com/keepgoingjkg/PatchCT.
ConZIC: Controllable Zero-shot Image Captioning by Sampling-Based Polishing
Mar 09, 2023

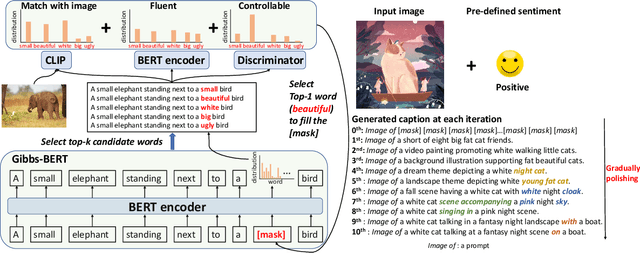

Zero-shot capability has been considered as a new revolution of deep learning, letting machines work on tasks without curated training data. As a good start and the only existing outcome of zero-shot image captioning (IC), ZeroCap abandons supervised training and sequentially searches every word in the caption using the knowledge of large-scale pretrained models. Though effective, its autoregressive generation and gradient-directed searching mechanism limit the diversity of captions and inference speed, respectively. Moreover, ZeroCap does not consider the controllability issue of zero-shot IC. To move forward, we propose a framework for Controllable Zero-shot IC, named ConZIC. The core of ConZIC is a novel sampling-based non-autoregressive language model named GibbsBERT, which can generate and continuously polish every word. Extensive quantitative and qualitative results demonstrate the superior performance of our proposed ConZIC for both zero-shot IC and controllable zero-shot IC. Especially, ConZIC achieves about 5x faster generation speed than ZeroCap, and about 1.5x higher diversity scores, with accurate generation given different control signals.
HyperMiner: Topic Taxonomy Mining with Hyperbolic Embedding
Oct 16, 2022
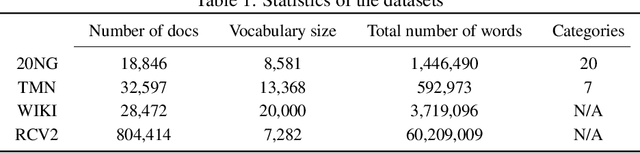

Embedded topic models are able to learn interpretable topics even with large and heavy-tailed vocabularies. However, they generally hold the Euclidean embedding space assumption, leading to a basic limitation in capturing hierarchical relations. To this end, we present a novel framework that introduces hyperbolic embeddings to represent words and topics. With the tree-likeness property of hyperbolic space, the underlying semantic hierarchy among words and topics can be better exploited to mine more interpretable topics. Furthermore, due to the superiority of hyperbolic geometry in representing hierarchical data, tree-structure knowledge can also be naturally injected to guide the learning of a topic hierarchy. Therefore, we further develop a regularization term based on the idea of contrastive learning to inject prior structural knowledge efficiently. Experiments on both topic taxonomy discovery and document representation demonstrate that the proposed framework achieves improved performance against existing embedded topic models.
Motion-aware Dynamic Graph Neural Network for Video Compressive Sensing
Mar 01, 2022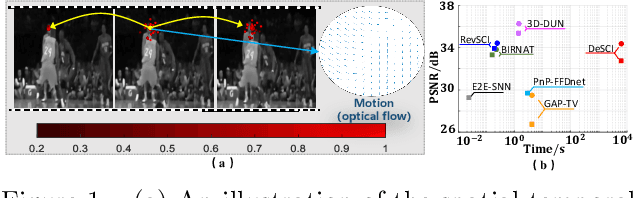
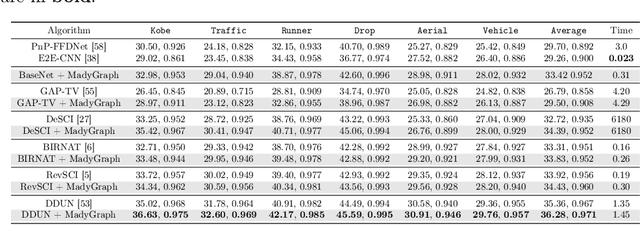
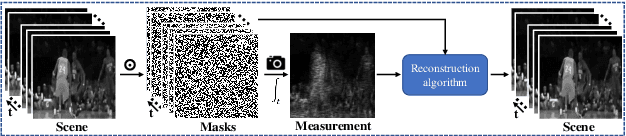
Video snapshot compressive imaging (SCI) utilizes a 2D detector to capture sequential video frames and compresses them into a single measurement. Various reconstruction methods have been developed to recover the high-speed video frames from the snapshot measurement. However, most existing reconstruction methods are incapable of capturing long-range spatial and temporal dependencies, which are critical for video processing. In this paper, we propose a flexible and robust approach based on graph neural network (GNN) to efficiently model non-local interactions between pixels in space as well as time regardless of the distance. Specifically, we develop a motion-aware dynamic GNN for better video representation, i.e., represent each pixel as the aggregation of relative nodes under the guidance of frame-by-frame motions, which consists of motion-aware dynamic sampling, cross-scale node sampling and graph aggregation. Extensive results on both simulation and real data demonstrate both the effectiveness and efficiency of the proposed approach, and the visualization clearly illustrates the intrinsic dynamic sampling operations of our proposed model for boosting the video SCI reconstruction results. The code and models will be released to the public.
Dual-view Snapshot Compressive Imaging via Optical Flow Aided Recurrent Neural Network
Sep 11, 2021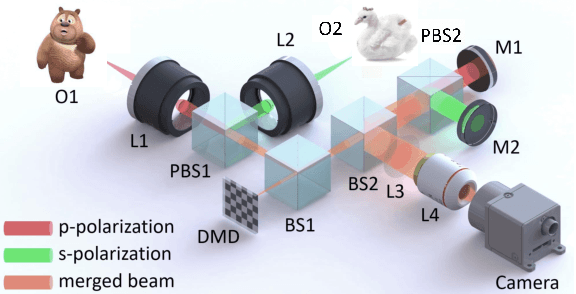
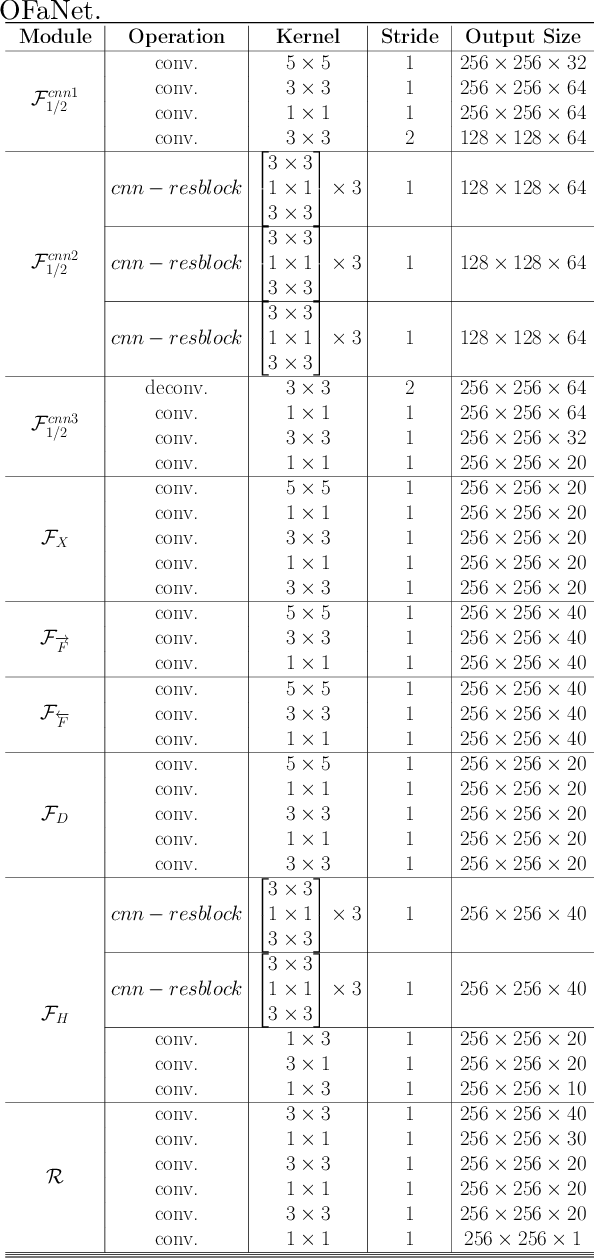

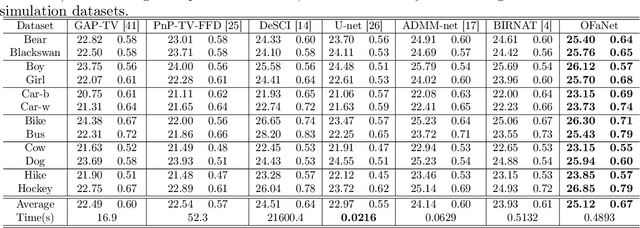
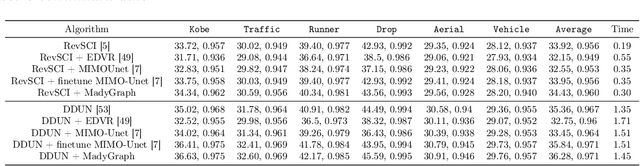
Dual-view snapshot compressive imaging (SCI) aims to capture videos from two field-of-views (FoVs) using a 2D sensor (detector) in a single snapshot, achieving joint FoV and temporal compressive sensing, and thus enjoying the advantages of low-bandwidth, low-power, and low-cost. However, it is challenging for existing model-based decoding algorithms to reconstruct each individual scene, which usually require exhaustive parameter tuning with extremely long running time for large scale data. In this paper, we propose an optical flow-aided recurrent neural network for dual video SCI systems, which provides high-quality decoding in seconds. Firstly, we develop a diversity amplification method to enlarge the differences between scenes of two FoVs, and design a deep convolutional neural network with dual branches to separate different scenes from the single measurement. Secondly, we integrate the bidirectional optical flow extracted from adjacent frames with the recurrent neural network to jointly reconstruct each video in a sequential manner. Extensive results on both simulation and real data demonstrate the superior performance of our proposed model in a short inference time. The code and data are available at https://github.com/RuiyingLu/OFaNet-for-Dual-view-SCI.
Matching Visual Features to Hierarchical Semantic Topics for Image Paragraph Captioning
May 10, 2021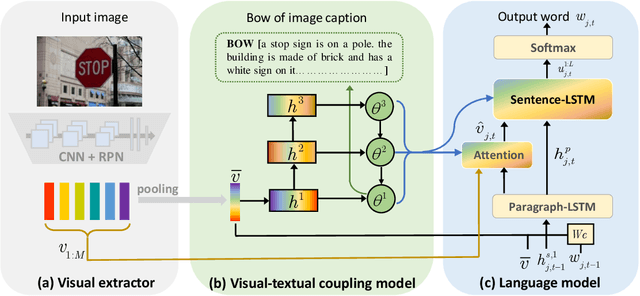
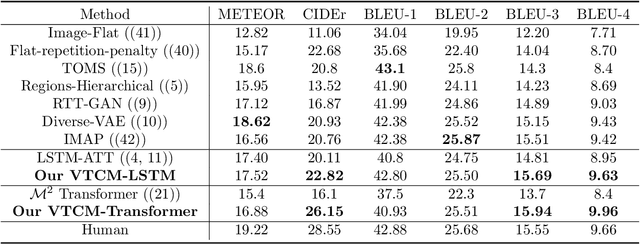
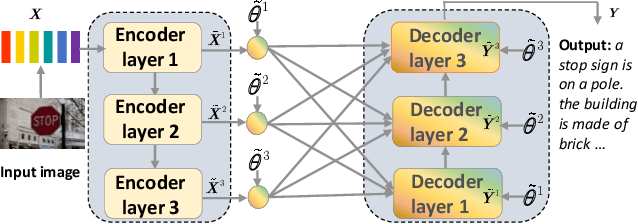
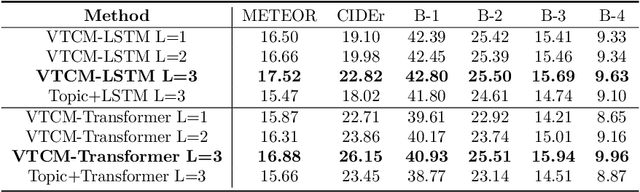
Observing a set of images and their corresponding paragraph-captions, a challenging task is to learn how to produce a semantically coherent paragraph to describe the visual content of an image. Inspired by recent successes in integrating semantic topics into this task, this paper develops a plug-and-play hierarchical-topic-guided image paragraph generation framework, which couples a visual extractor with a deep topic model to guide the learning of a language model. To capture the correlations between the image and text at multiple levels of abstraction and learn the semantic topics from images, we design a variational inference network to build the mapping from image features to textual captions. To guide the paragraph generation, the learned hierarchical topics and visual features are integrated into the language model, including Long Short-Term Memory (LSTM) and Transformer, and jointly optimized. Experiments on public dataset demonstrate that the proposed models, which are competitive with many state-of-the-art approaches in terms of standard evaluation metrics, can be used to both distill interpretable multi-layer topics and generate diverse and coherent captions.
Memory-Efficient Network for Large-scale Video Compressive Sensing
Mar 05, 2021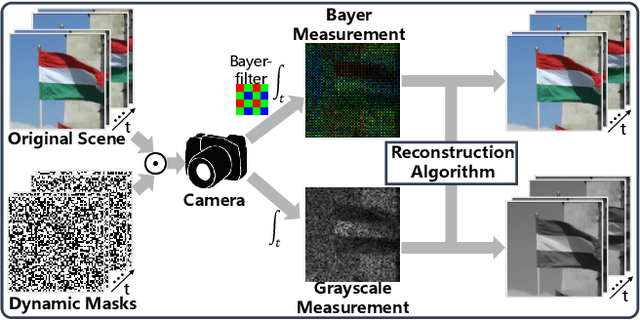
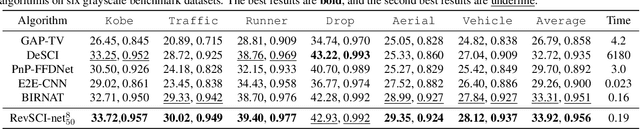

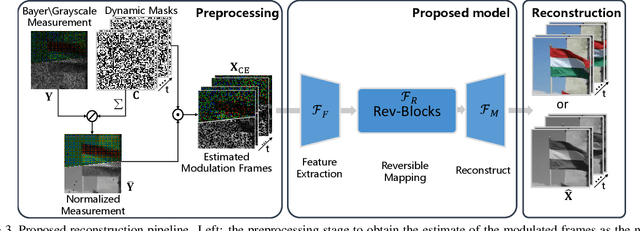
Video snapshot compressive imaging (SCI) captures a sequence of video frames in a single shot using a 2D detector. The underlying principle is that during one exposure time, different masks are imposed on the high-speed scene to form a compressed measurement. With the knowledge of masks, optimization algorithms or deep learning methods are employed to reconstruct the desired high-speed video frames from this snapshot measurement. Unfortunately, though these methods can achieve decent results, the long running time of optimization algorithms or huge training memory occupation of deep networks still preclude them in practical applications. In this paper, we develop a memory-efficient network for large-scale video SCI based on multi-group reversible 3D convolutional neural networks. In addition to the basic model for the grayscale SCI system, we take one step further to combine demosaicing and SCI reconstruction to directly recover color video from Bayer measurements. Extensive results on both simulation and real data captured by SCI cameras demonstrate that our proposed model outperforms previous state-of-the-art with less memory and thus can be used in large-scale problems. The code is at https://github.com/BoChenGroup/RevSCI-net.