 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuplex: Dual Prototype Learning for Compositional Zero-Shot Learning
Jan 13, 2025



Compositional Zero-Shot Learning (CZSL) aims to enable models to recognize novel compositions of visual states and objects that were absent during training. Existing methods predominantly focus on learning semantic representations of seen compositions but often fail to disentangle the independent features of states and objects in images, thereby limiting their ability to generalize to unseen compositions. To address this challenge, we propose Duplex, a novel dual-prototype learning method that integrates semantic and visual prototypes through a carefully designed dual-branch architecture, enabling effective representation learning for compositional tasks. Duplex utilizes a Graph Neural Network (GNN) to adaptively update visual prototypes, capturing complex interactions between states and objects. Additionally, it leverages the strong visual-semantic alignment of pre-trained Vision-Language Models (VLMs) and employs a multi-path architecture combined with prompt engineering to align image and text representations, ensuring robust generalization. Extensive experiments on three benchmark datasets demonstrate that Duplex outperforms state-of-the-art methods in both closed-world and open-world settings.
Recent Advances in Attack and Defense Approaches of Large Language Models
Sep 05, 2024Large Language Models (LLMs) have revolutionized artificial intelligence and machine learning through their advanced text processing and generating capabilities. However, their widespread deployment has raised significant safety and reliability concerns. Established vulnerabilities in deep neural networks, coupled with emerging threat models, may compromise security evaluations and create a false sense of security. Given the extensive research in the field of LLM security, we believe that summarizing the current state of affairs will help the research community better understand the present landscape and inform future developments. This paper reviews current research on LLM vulnerabilities and threats, and evaluates the effectiveness of contemporary defense mechanisms. We analyze recent studies on attack vectors and model weaknesses, providing insights into attack mechanisms and the evolving threat landscape. We also examine current defense strategies, highlighting their strengths and limitations. By contrasting advancements in attack and defense methodologies, we identify research gaps and propose future directions to enhance LLM security. Our goal is to advance the understanding of LLM safety challenges and guide the development of more robust security measures.
Bilingual Adaptation of Monolingual Foundation Models
Jul 13, 2024
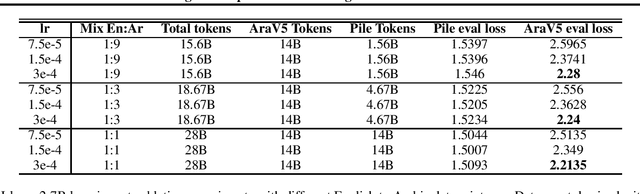


We present an efficient method for adapting a monolingual Large Language Model (LLM) to another language, addressing challenges of catastrophic forgetting and tokenizer limitations. We focus this study on adapting Llama 2 to Arabic. Our two-stage approach begins with expanding the vocabulary and training only the embeddings matrix, followed by full model continual pretraining on a bilingual corpus. By continually pretraining on a mix of Arabic and English corpora, the model retains its proficiency in English while acquiring capabilities in Arabic. Our approach results in significant improvements in Arabic and slight enhancements in English, demonstrating cost-effective cross-lingual transfer. We also perform extensive ablations on embedding initialization techniques, data mix ratios, and learning rates and release a detailed training recipe.
keqing: knowledge-based question answering is a nature chain-of-thought mentor of LLM
Dec 31, 2023



Large language models (LLMs) have exhibited remarkable performance on various natural language processing (NLP) tasks, especially for question answering. However, in the face of problems beyond the scope of knowledge, these LLMs tend to talk nonsense with a straight face, where the potential solution could be incorporating an Information Retrieval (IR) module and generating response based on these retrieved knowledge. In this paper, we present a novel framework to assist LLMs, such as ChatGPT, to retrieve question-related structured information on the knowledge graph, and demonstrate that Knowledge-based question answering (Keqing) could be a nature Chain-of-Thought (CoT) mentor to guide the LLM to sequentially find the answer entities of a complex question through interpretable logical chains. Specifically, the workflow of Keqing will execute decomposing a complex question according to predefined templates, retrieving candidate entities on knowledge graph, reasoning answers of sub-questions, and finally generating response with reasoning paths, which greatly improves the reliability of LLM's response. The experimental results on KBQA datasets show that Keqing can achieve competitive performance and illustrate the logic of answering each question.
Patch-Token Aligned Bayesian Prompt Learning for Vision-Language Models
Mar 16, 2023For downstream applications of vision-language pre-trained models, there has been significant interest in constructing effective prompts. Existing works on prompt engineering, which either require laborious manual designs or optimize the prompt tuning as a point estimation problem, may fail to describe diverse characteristics of categories and limit their applications. We introduce a Bayesian probabilistic resolution to prompt learning, where the label-specific stochastic prompts are generated hierarchically by first sampling a latent vector from an underlying distribution and then employing a lightweight generative model. Importantly, we semantically regularize prompt learning with the visual knowledge and view images and the corresponding prompts as patch and token sets under optimal transport, which pushes the prompt tokens to faithfully capture the label-specific visual concepts, instead of overfitting the training categories. Moreover, the proposed model can also be straightforwardly extended to the conditional case where the instance-conditional prompts are generated to improve the generalizability. Extensive experiments on 15 datasets show promising transferability and generalization performance of our proposed model.
HyperMiner: Topic Taxonomy Mining with Hyperbolic Embedding
Oct 16, 2022

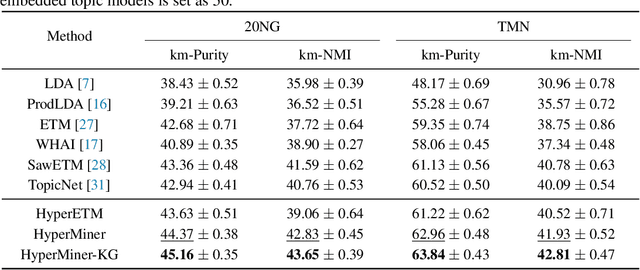
Embedded topic models are able to learn interpretable topics even with large and heavy-tailed vocabularies. However, they generally hold the Euclidean embedding space assumption, leading to a basic limitation in capturing hierarchical relations. To this end, we present a novel framework that introduces hyperbolic embeddings to represent words and topics. With the tree-likeness property of hyperbolic space, the underlying semantic hierarchy among words and topics can be better exploited to mine more interpretable topics. Furthermore, due to the superiority of hyperbolic geometry in representing hierarchical data, tree-structure knowledge can also be naturally injected to guide the learning of a topic hierarchy. Therefore, we further develop a regularization term based on the idea of contrastive learning to inject prior structural knowledge efficiently. Experiments on both topic taxonomy discovery and document representation demonstrate that the proposed framework achieves improved performance against existing embedded topic models.
Knowledge-Aware Bayesian Deep Topic Model
Sep 20, 2022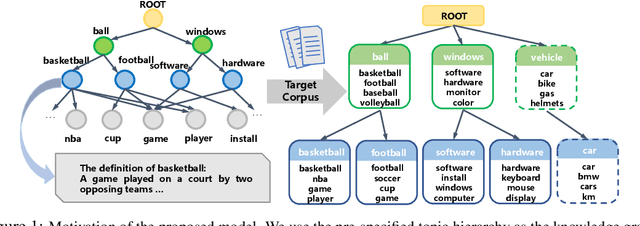
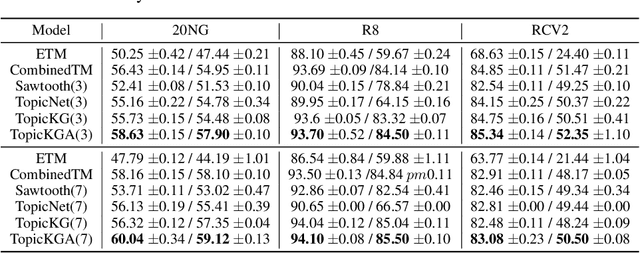
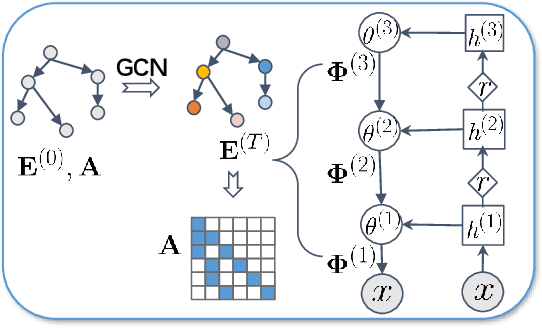

We propose a Bayesian generative model for incorporating prior domain knowledge into hierarchical topic modeling. Although embedded topic models (ETMs) and its variants have gained promising performance in text analysis, they mainly focus on mining word co-occurrence patterns, ignoring potentially easy-to-obtain prior topic hierarchies that could help enhance topic coherence. While several knowledge-based topic models have recently been proposed, they are either only applicable to shallow hierarchies or sensitive to the quality of the provided prior knowledge. To this end, we develop a novel deep ETM that jointly models the documents and the given prior knowledge by embedding the words and topics into the same space. Guided by the provided knowledge, the proposed model tends to discover topic hierarchies that are organized into interpretable taxonomies. Besides, with a technique for adapting a given graph, our extended version allows the provided prior topic structure to be finetuned to match the target corpus. Extensive experiments show that our proposed model efficiently integrates the prior knowledge and improves both hierarchical topic discovery and document representation.
TopicNet: Semantic Graph-Guided Topic Discovery
Oct 27, 2021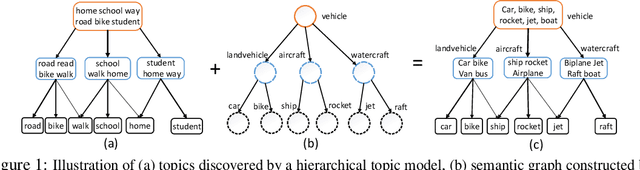

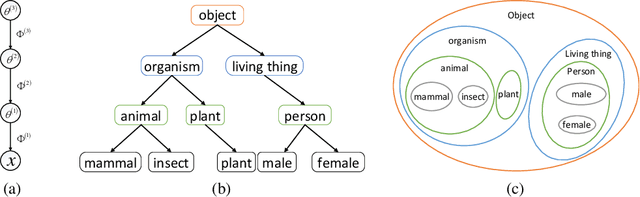
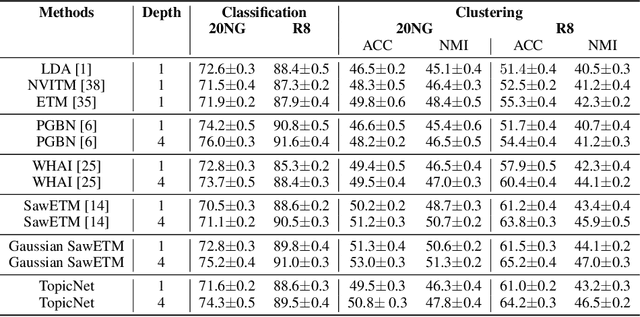
Existing deep hierarchical topic models are able to extract semantically meaningful topics from a text corpus in an unsupervised manner and automatically organize them into a topic hierarchy. However, it is unclear how to incorporate prior beliefs such as knowledge graph to guide the learning of the topic hierarchy. To address this issue, we introduce TopicNet as a deep hierarchical topic model that can inject prior structural knowledge as an inductive bias to influence learning. TopicNet represents each topic as a Gaussian-distributed embedding vector, projects the topics of all layers into a shared embedding space, and explores both the symmetric and asymmetric similarities between Gaussian embedding vectors to incorporate prior semantic hierarchies. With an auto-encoding variational inference network, the model parameters are optimized by minimizing the evidence lower bound and a regularization term via stochastic gradient descent. Experiments on widely used benchmarks show that TopicNet outperforms related deep topic models on discovering deeper interpretable topics and mining better document~representations.
TIE: A Framework for Embedding-based Incremental Temporal Knowledge Graph Completion
May 09, 2021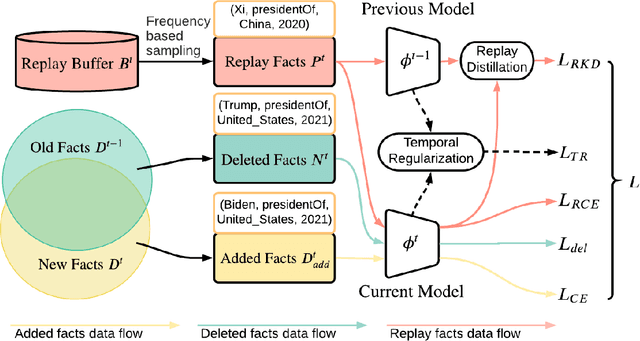

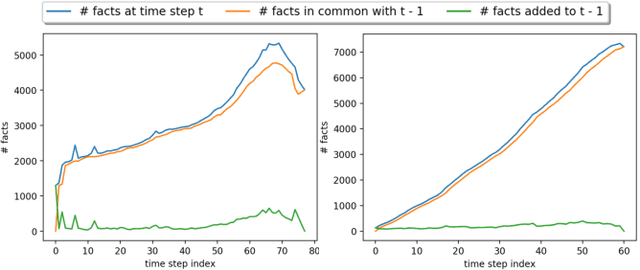
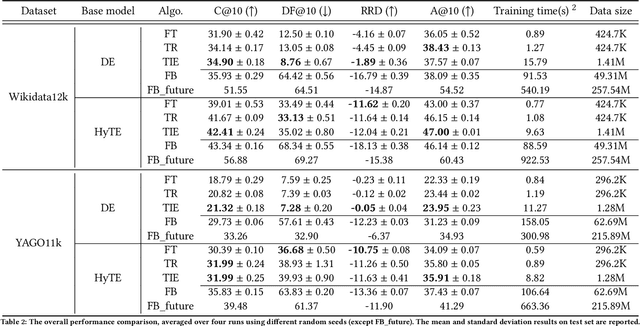
Reasoning in a temporal knowledge graph (TKG) is a critical task for information retrieval and semantic search. It is particularly challenging when the TKG is updated frequently. The model has to adapt to changes in the TKG for efficient training and inference while preserving its performance on historical knowledge. Recent work approaches TKG completion (TKGC) by augmenting the encoder-decoder framework with a time-aware encoding function. However, naively fine-tuning the model at every time step using these methods does not address the problems of 1) catastrophic forgetting, 2) the model's inability to identify the change of facts (e.g., the change of the political affiliation and end of a marriage), and 3) the lack of training efficiency. To address these challenges, we present the Time-aware Incremental Embedding (TIE) framework, which combines TKG representation learning, experience replay, and temporal regularization. We introduce a set of metrics that characterizes the intransigence of the model and propose a constraint that associates the deleted facts with negative labels. Experimental results on Wikidata12k and YAGO11k datasets demonstrate that the proposed TIE framework reduces training time by about ten times and improves on the proposed metrics compared to vanilla full-batch training. It comes without a significant loss in performance for any traditional measures. Extensive ablation studies reveal performance trade-offs among different evaluation metrics, which is essential for decision-making around real-world TKG applications.
GraphSAIL: Graph Structure Aware Incremental Learning for Recommender Systems
Sep 02, 2020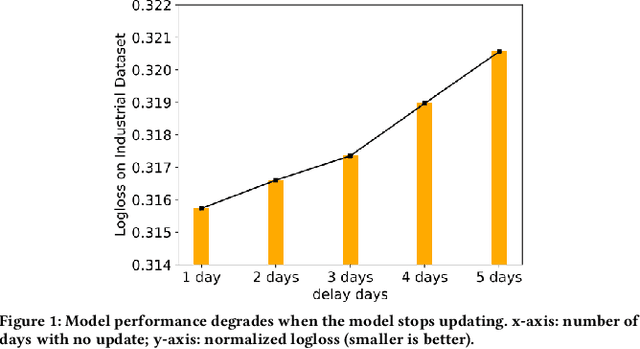

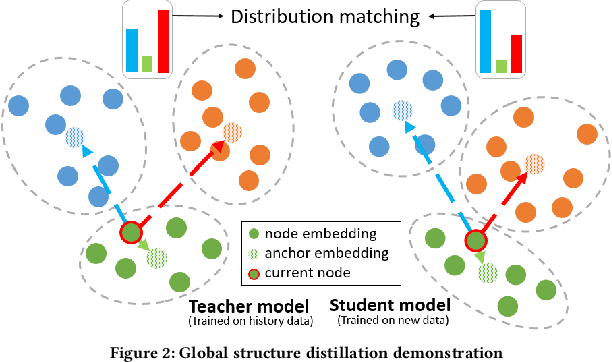
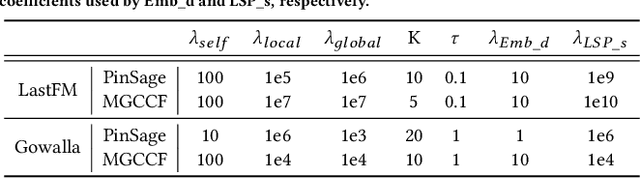
Given the convenience of collecting information through online services, recommender systems now consume large scale data and play a more important role in improving user experience. With the recent emergence of Graph Neural Networks (GNNs), GNN-based recommender models have shown the advantage of modeling the recommender system as a user-item bipartite graph to learn representations of users and items. However, such models are expensive to train and difficult to perform frequent updates to provide the most up-to-date recommendations. In this work, we propose to update GNN-based recommender models incrementally so that the computation time can be greatly reduced and models can be updated more frequently. We develop a Graph Structure Aware Incremental Learning framework, GraphSAIL, to address the commonly experienced catastrophic forgetting problem that occurs when training a model in an incremental fashion. Our approach preserves a user's long-term preference (or an item's long-term property) during incremental model updating. GraphSAIL implements a graph structure preservation strategy which explicitly preserves each node's local structure, global structure, and self-information, respectively. We argue that our incremental training framework is the first attempt tailored for GNN based recommender systems and demonstrate its improvement compared to other incremental learning techniques on two public datasets. We further verify the effectiveness of our framework on a large-scale industrial dataset.