 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaCo: Efficient Layer-wise Compression of Visual Tokens for Multimodal Large Language Models
Jul 03, 2025



Existing visual token compression methods for Multimodal Large Language Models (MLLMs) predominantly operate as post-encoder modules, limiting their potential for efficiency gains. To address this limitation, we propose LaCo (Layer-wise Visual Token Compression), a novel framework that enables effective token compression within the intermediate layers of the vision encoder. LaCo introduces two core components: 1) a layer-wise pixel-shuffle mechanism that systematically merges adjacent tokens through space-to-channel transformations, and 2) a residual learning architecture with non-parametric shortcuts that preserves critical visual information during compression. Extensive experiments indicate that our LaCo outperforms all existing methods when compressing tokens in the intermediate layers of the vision encoder, demonstrating superior effectiveness. In addition, compared to external compression, our method improves training efficiency beyond 20% and inference throughput over 15% while maintaining strong performance.
FastRef:Fast Prototype Refinement for Few-Shot Industrial Anomaly Detection
Jun 26, 2025Few-shot industrial anomaly detection (FS-IAD) presents a critical challenge for practical automated inspection systems operating in data-scarce environments. While existing approaches predominantly focus on deriving prototypes from limited normal samples, they typically neglect to systematically incorporate query image statistics to enhance prototype representativeness. To address this issue, we propose FastRef, a novel and efficient prototype refinement framework for FS-IAD. Our method operates through an iterative two-stage process: (1) characteristic transfer from query features to prototypes via an optimizable transformation matrix, and (2) anomaly suppression through prototype alignment. The characteristic transfer is achieved through linear reconstruction of query features from prototypes, while the anomaly suppression addresses a key observation in FS-IAD that unlike conventional IAD with abundant normal prototypes, the limited-sample setting makes anomaly reconstruction more probable. Therefore, we employ optimal transport (OT) for non-Gaussian sampled features to measure and minimize the gap between prototypes and their refined counterparts for anomaly suppression. For comprehensive evaluation, we integrate FastRef with three competitive prototype-based FS-IAD methods: PatchCore, FastRecon, WinCLIP, and AnomalyDINO. Extensive experiments across four benchmark datasets of MVTec, ViSA, MPDD and RealIAD demonstrate both the effectiveness and computational efficiency of our approach under 1/2/4-shots.
Duplex: Dual Prototype Learning for Compositional Zero-Shot Learning
Jan 13, 2025



Compositional Zero-Shot Learning (CZSL) aims to enable models to recognize novel compositions of visual states and objects that were absent during training. Existing methods predominantly focus on learning semantic representations of seen compositions but often fail to disentangle the independent features of states and objects in images, thereby limiting their ability to generalize to unseen compositions. To address this challenge, we propose Duplex, a novel dual-prototype learning method that integrates semantic and visual prototypes through a carefully designed dual-branch architecture, enabling effective representation learning for compositional tasks. Duplex utilizes a Graph Neural Network (GNN) to adaptively update visual prototypes, capturing complex interactions between states and objects. Additionally, it leverages the strong visual-semantic alignment of pre-trained Vision-Language Models (VLMs) and employs a multi-path architecture combined with prompt engineering to align image and text representations, ensuring robust generalization. Extensive experiments on three benchmark datasets demonstrate that Duplex outperforms state-of-the-art methods in both closed-world and open-world settings.
MaskMamba: A Hybrid Mamba-Transformer Model for Masked Image Generation
Sep 30, 2024



Image generation models have encountered challenges related to scalability and quadratic complexity, primarily due to the reliance on Transformer-based backbones. In this study, we introduce MaskMamba, a novel hybrid model that combines Mamba and Transformer architectures, utilizing Masked Image Modeling for non-autoregressive image synthesis. We meticulously redesign the bidirectional Mamba architecture by implementing two key modifications: (1) replacing causal convolutions with standard convolutions to better capture global context, and (2) utilizing concatenation instead of multiplication, which significantly boosts performance while accelerating inference speed. Additionally, we explore various hybrid schemes of MaskMamba, including both serial and grouped parallel arrangements. Furthermore, we incorporate an in-context condition that allows our model to perform both class-to-image and text-to-image generation tasks. Our MaskMamba outperforms Mamba-based and Transformer-based models in generation quality. Notably, it achieves a remarkable $54.44\%$ improvement in inference speed at a resolution of $2048\times 2048$ over Transformer.
Treating Brain-inspired Memories as Priors for Diffusion Model to Forecast Multivariate Time Series
Sep 27, 2024Forecasting Multivariate Time Series (MTS) involves significant challenges in various application domains. One immediate challenge is modeling temporal patterns with the finite length of the input. These temporal patterns usually involve periodic and sudden events that recur across different channels. To better capture temporal patterns, we get inspiration from humans' memory mechanisms and propose a channel-shared, brain-inspired memory module for MTS. Specifically, brain-inspired memory comprises semantic and episodic memory, where the former is used to capture general patterns, such as periodic events, and the latter is employed to capture special patterns, such as sudden events, respectively. Meanwhile, we design corresponding recall and update mechanisms to better utilize these patterns. Furthermore, acknowledging the capacity of diffusion models to leverage memory as a prior, we present a brain-inspired memory-augmented diffusion model. This innovative model retrieves relevant memories for different channels, utilizing them as distinct priors for MTS predictions. This incorporation significantly enhances the accuracy and robustness of predictions. Experimental results on eight datasets consistently validate the superiority of our approach in capturing and leveraging diverse recurrent temporal patterns across different channels.
LVOS: A Benchmark for Large-scale Long-term Video Object Segmentation
May 01, 2024
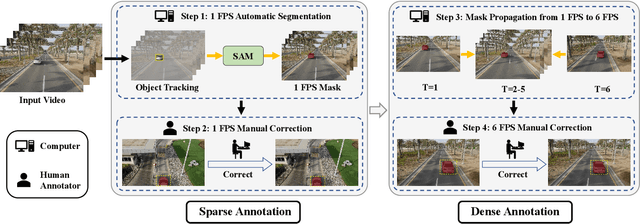
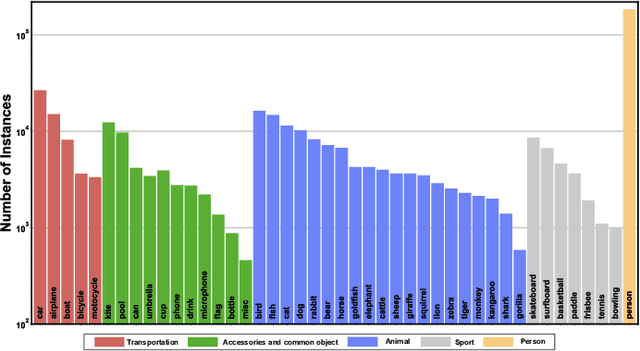

Video object segmentation (VOS) aims to distinguish and track target objects in a video. Despite the excellent performance achieved by off-the-shell VOS models, existing VOS benchmarks mainly focus on short-term videos lasting about 5 seconds, where objects remain visible most of the time. However, these benchmarks poorly represent practical applications, and the absence of long-term datasets restricts further investigation of VOS in realistic scenarios. Thus, we propose a novel benchmark named LVOS, comprising 720 videos with 296,401 frames and 407,945 high-quality annotations. Videos in LVOS last 1.14 minutes on average, approximately 5 times longer than videos in existing datasets. Each video includes various attributes, especially challenges deriving from the wild, such as long-term reappearing and cross-temporal similar objects. Compared to previous benchmarks, our LVOS better reflects VOS models' performance in real scenarios. Based on LVOS, we evaluate 20 existing VOS models under 4 different settings and conduct a comprehensive analysis. On LVOS, these models suffer a large performance drop, highlighting the challenge of achieving precise tracking and segmentation in real-world scenarios. Attribute-based analysis indicates that key factor to accuracy decline is the increased video length, emphasizing LVOS's crucial role. We hope our LVOS can advance development of VOS in real scenes. Data and code are available at https://lingyihongfd.github.io/lvos.github.io/.
Considering Nonstationary within Multivariate Time Series with Variational Hierarchical Transformer for Forecasting
Mar 08, 2024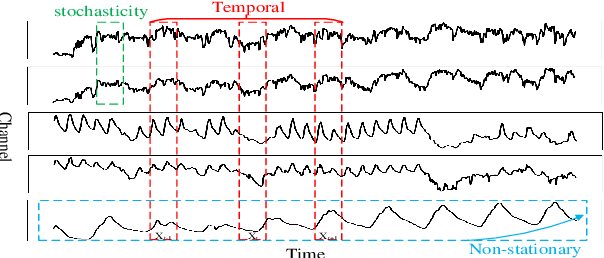
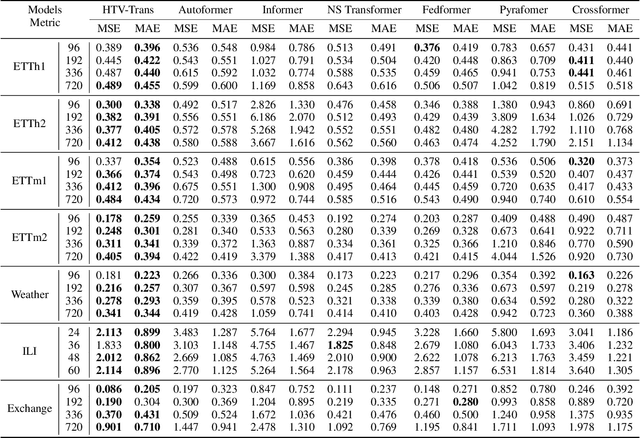
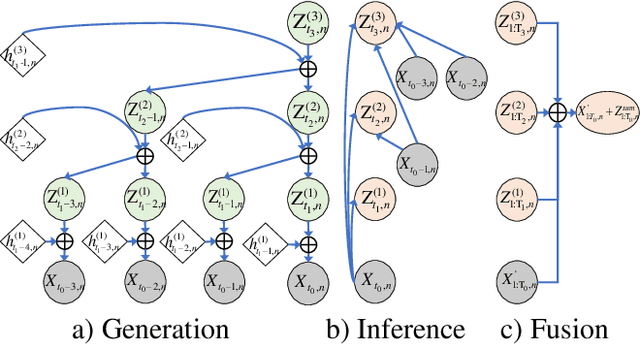
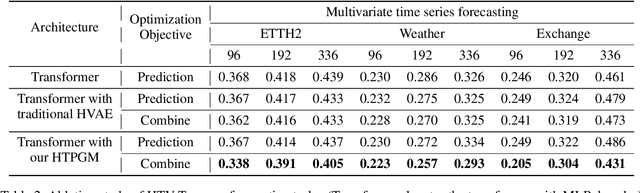
The forecasting of Multivariate Time Series (MTS) has long been an important but challenging task. Due to the non-stationary problem across long-distance time steps, previous studies primarily adopt stationarization method to attenuate the non-stationary problem of the original series for better predictability. However, existing methods always adopt the stationarized series, which ignores the inherent non-stationarity, and has difficulty in modeling MTS with complex distributions due to the lack of stochasticity. To tackle these problems, we first develop a powerful hierarchical probabilistic generative module to consider the non-stationarity and stochastic characteristics within MTS, and then combine it with transformer for a well-defined variational generative dynamic model named Hierarchical Time series Variational Transformer (HTV-Trans), which recovers the intrinsic non-stationary information into temporal dependencies. Being a powerful probabilistic model, HTV-Trans is utilized to learn expressive representations of MTS and applied to forecasting tasks. Extensive experiments on diverse datasets show the efficiency of HTV-Trans on MTS forecasting tasks
PanoVOS: Bridging Non-panoramic and Panoramic Views with Transformer for Video Segmentation
Sep 22, 2023Panoramic videos contain richer spatial information and have attracted tremendous amounts of attention due to their exceptional experience in some fields such as autonomous driving and virtual reality. However, existing datasets for video segmentation only focus on conventional planar images. To address the challenge, in this paper, we present a panoramic video dataset, PanoVOS. The dataset provides 150 videos with high video resolutions and diverse motions. To quantify the domain gap between 2D planar videos and panoramic videos, we evaluate 15 off-the-shelf video object segmentation (VOS) models on PanoVOS. Through error analysis, we found that all of them fail to tackle pixel-level content discontinues of panoramic videos. Thus, we present a Panoramic Space Consistency Transformer (PSCFormer), which can effectively utilize the semantic boundary information of the previous frame for pixel-level matching with the current frame. Extensive experiments demonstrate that compared with the previous SOTA models, our PSCFormer network exhibits a great advantage in terms of segmentation results under the panoramic setting. Our dataset poses new challenges in panoramic VOS and we hope that our PanoVOS can advance the development of panoramic segmentation/tracking.
Prototypes-oriented Transductive Few-shot Learning with Conditional Transport
Aug 06, 2023Transductive Few-Shot Learning (TFSL) has recently attracted increasing attention since it typically outperforms its inductive peer by leveraging statistics of query samples. However, previous TFSL methods usually encode uniform prior that all the classes within query samples are equally likely, which is biased in imbalanced TFSL and causes severe performance degradation. Given this pivotal issue, in this work, we propose a novel Conditional Transport (CT) based imbalanced TFSL model called {\textbf P}rototypes-oriented {\textbf U}nbiased {\textbf T}ransfer {\textbf M}odel (PUTM) to fully exploit unbiased statistics of imbalanced query samples, which employs forward and backward navigators as transport matrices to balance the prior of query samples per class between uniform and adaptive data-driven distributions. For efficiently transferring statistics learned by CT, we further derive a closed form solution to refine prototypes based on MAP given the learned navigators. The above two steps of discovering and transferring unbiased statistics follow an iterative manner, formulating our EM-based solver. Experimental results on four standard benchmarks including miniImageNet, tieredImageNet, CUB, and CIFAR-FS demonstrate superiority of our model in class-imbalanced generalization.
Referred by Multi-Modality: A Unified Temporal Transformer for Video Object Segmentation
May 25, 2023Recently, video object segmentation (VOS) referred by multi-modal signals, e.g., language and audio, has evoked increasing attention in both industry and academia. It is challenging for exploring the semantic alignment within modalities and the visual correspondence across frames. However, existing methods adopt separate network architectures for different modalities, and neglect the inter-frame temporal interaction with references. In this paper, we propose MUTR, a Multi-modal Unified Temporal transformer for Referring video object segmentation. With a unified framework for the first time, MUTR adopts a DETR-style transformer and is capable of segmenting video objects designated by either text or audio reference. Specifically, we introduce two strategies to fully explore the temporal relations between videos and multi-modal signals. Firstly, for low-level temporal aggregation before the transformer, we enable the multi-modal references to capture multi-scale visual cues from consecutive video frames. This effectively endows the text or audio signals with temporal knowledge and boosts the semantic alignment between modalities. Secondly, for high-level temporal interaction after the transformer, we conduct inter-frame feature communication for different object embeddings, contributing to better object-wise correspondence for tracking along the video. On Ref-YouTube-VOS and AVSBench datasets with respective text and audio references, MUTR achieves +4.2% and +4.2% J&F improvements to state-of-the-art methods, demonstrating our significance for unified multi-modal VOS. Code is released at https://github.com/OpenGVLab/MUTR.