 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyReels-V4: Multi-modal Video-Audio Generation, Inpainting and Editing model
Feb 26, 2026SkyReels V4 is a unified multi modal video foundation model for joint video audio generation, inpainting, and editing. The model adopts a dual stream Multimodal Diffusion Transformer (MMDiT) architecture, where one branch synthesizes video and the other generates temporally aligned audio, while sharing a powerful text encoder based on the Multimodal Large Language Models (MMLM). SkyReels V4 accepts rich multi modal instructions, including text, images, video clips, masks, and audio references. By combining the MMLMs multi modal instruction following capability with in context learning in the video branch MMDiT, the model can inject fine grained visual guidance under complex conditioning, while the audio branch MMDiT simultaneously leverages audio references to guide sound generation. On the video side, we adopt a channel concatenation formulation that unifies a wide range of inpainting style tasks, such as image to video, video extension, and video editing under a single interface, and naturally extends to vision referenced inpainting and editing via multi modal prompts. SkyReels V4 supports up to 1080p resolution, 32 FPS, and 15 second duration, enabling high fidelity, multi shot, cinema level video generation with synchronized audio. To make such high resolution, long-duration generation computationally feasible, we introduce an efficiency strategy: Joint generation of low resolution full sequences and high-resolution keyframes, followed by dedicated super-resolution and frame interpolation models. To our knowledge, SkyReels V4 is the first video foundation model that simultaneously supports multi-modal input, joint video audio generation, and a unified treatment of generation, inpainting, and editing, while maintaining strong efficiency and quality at cinematic resolutions and durations.
Skywork-Reward-V2: Scaling Preference Data Curation via Human-AI Synergy
Jul 02, 2025Despite the critical role of reward models (RMs) in reinforcement learning from human feedback (RLHF), current state-of-the-art open RMs perform poorly on most existing evaluation benchmarks, failing to capture the spectrum of nuanced and sophisticated human preferences. Even approaches that incorporate advanced training techniques have not yielded meaningful performance improvements. We hypothesize that this brittleness stems primarily from limitations in preference datasets, which are often narrowly scoped, synthetically labeled, or lack rigorous quality control. To address these challenges, we present a large-scale preference dataset comprising 40 million preference pairs, named SynPref-40M. To enable data curation at scale, we design a human-AI synergistic two-stage pipeline that leverages the complementary strengths of human annotation quality and AI scalability. In this pipeline, humans provide verified annotations, while large language models perform automatic curation based on human guidance. Training on this preference mixture, we introduce Skywork-Reward-V2, a suite of eight reward models ranging from 0.6B to 8B parameters, trained on a carefully curated subset of 26 million preference pairs from SynPref-40M. We demonstrate that Skywork-Reward-V2 is versatile across a wide range of capabilities, including alignment with human preferences, objective correctness, safety, resistance to stylistic biases, and best-of-N scaling, achieving state-of-the-art performance across seven major reward model benchmarks. Ablation studies confirm that the effectiveness of our approach stems not only from data scale but also from high-quality curation. The Skywork-Reward-V2 series represents substantial progress in open reward models, highlighting the untapped potential of existing preference datasets and demonstrating how human-AI curation synergy can unlock significantly higher data quality.
Skywork Open Reasoner 1 Technical Report
May 29, 2025The success of DeepSeek-R1 underscores the significant role of reinforcement learning (RL) in enhancing the reasoning capabilities of large language models (LLMs). In this work, we present Skywork-OR1, an effective and scalable RL implementation for long Chain-of-Thought (CoT) models. Building on the DeepSeek-R1-Distill model series, our RL approach achieves notable performance gains, increasing average accuracy across AIME24, AIME25, and LiveCodeBench from 57.8% to 72.8% (+15.0%) for the 32B model and from 43.6% to 57.5% (+13.9%) for the 7B model. Our Skywork-OR1-32B model surpasses both DeepSeek-R1 and Qwen3-32B on the AIME24 and AIME25 benchmarks, while achieving comparable results on LiveCodeBench. The Skywork-OR1-7B and Skywork-OR1-Math-7B models demonstrate competitive reasoning capabilities among models of similar size. We perform comprehensive ablation studies on the core components of our training pipeline to validate their effectiveness. Additionally, we thoroughly investigate the phenomenon of entropy collapse, identify key factors affecting entropy dynamics, and demonstrate that mitigating premature entropy collapse is critical for improved test performance. To support community research, we fully open-source our model weights, training code, and training datasets.
Improving Multi-Step Reasoning Abilities of Large Language Models with Direct Advantage Policy Optimization
Dec 24, 2024



The role of reinforcement learning (RL) in enhancing the reasoning of large language models (LLMs) is becoming increasingly significant. Despite the success of RL in many scenarios, there are still many challenges in improving the reasoning of LLMs. One challenge is the sparse reward, which makes optimization difficult for RL and necessitates a large amount of data samples. Another challenge stems from the inherent instability of RL, particularly when using Actor-Critic (AC) methods to derive optimal policies, which often leads to unstable training processes. To address these issues, we introduce Direct Advantage Policy Optimization (DAPO), an novel step-level offline RL algorithm. Unlike standard alignment that rely solely outcome rewards to optimize policies (such as DPO), DAPO employs a critic function to predict the reasoning accuracy at each step, thereby generating dense signals to refine the generation strategy. Additionally, the Actor and Critic components in DAPO are trained independently, avoiding the co-training instability observed in standard AC algorithms like PPO. We train DAPO on mathematical and code query datasets and then evaluate its performance on multiple benchmarks. Our results show that DAPO can effectively enhance the mathematical and code capabilities on both SFT models and RL models, demonstrating the effectiveness of DAPO.
Mars-PO: Multi-Agent Reasoning System Preference Optimization
Nov 28, 2024



Mathematical reasoning is a fundamental capability for large language models (LLMs), yet achieving high performance in this domain remains a significant challenge. The auto-regressive generation process often makes LLMs susceptible to errors, hallucinations, and inconsistencies, particularly during multi-step reasoning. In this paper, we propose Mars-PO, a novel framework to improve the mathematical reasoning capabilities of LLMs through a multi-agent system. It combines high-quality outputs from multiple agents into a hybrid positive sample set and pairs them with agent-specific negative samples to construct robust preference pairs for training. By aligning agents with shared positive samples while addressing individual weaknesses, Mars-PO achieves substantial performance improvements on mathematical reasoning benchmarks. For example, it increases the accuracy on the MATH benchmark of the state-of-the-art instruction-tuned LLM, Llama3.1-8B-Instruct, from 50.38% to 57.82%. Experimental results further demonstrate that our method consistently outperforms other baselines, such as supervised fine-tuning, vanilla DPO, and its enhanced versions, highlighting the effectiveness of our approach.
Skywork-Reward: Bag of Tricks for Reward Modeling in LLMs
Oct 24, 2024In this report, we introduce a collection of methods to enhance reward modeling for LLMs, focusing specifically on data-centric techniques. We propose effective data selection and filtering strategies for curating high-quality open-source preference datasets, culminating in the Skywork-Reward data collection, which contains only 80K preference pairs -- significantly smaller than existing datasets. Using this curated dataset, we developed the Skywork-Reward model series -- Skywork-Reward-Gemma-27B and Skywork-Reward-Llama-3.1-8B -- with the former currently holding the top position on the RewardBench leaderboard. Notably, our techniques and datasets have directly enhanced the performance of many top-ranked models on RewardBench, highlighting the practical impact of our contributions in real-world preference learning applications.
Scalable Weibull Graph Attention Autoencoder for Modeling Document Networks
Oct 13, 2024



Although existing variational graph autoencoders (VGAEs) have been widely used for modeling and generating graph-structured data, most of them are still not flexible enough to approximate the sparse and skewed latent node representations, especially those of document relational networks (DRNs) with discrete observations. To analyze a collection of interconnected documents, a typical branch of Bayesian models, specifically relational topic models (RTMs), has proven their efficacy in describing both link structures and document contents of DRNs, which motives us to incorporate RTMs with existing VGAEs to alleviate their potential issues when modeling the generation of DRNs. In this paper, moving beyond the sophisticated approximate assumptions of traditional RTMs, we develop a graph Poisson factor analysis (GPFA), which provides analytic conditional posteriors to improve the inference accuracy, and extend GPFA to a multi-stochastic-layer version named graph Poisson gamma belief network (GPGBN) to capture the hierarchical document relationships at multiple semantic levels. Then, taking GPGBN as the decoder, we combine it with various Weibull-based graph inference networks, resulting in two variants of Weibull graph auto-encoder (WGAE), equipped with model inference algorithms. Experimental results demonstrate that our models can extract high-quality hierarchical latent document representations and achieve promising performance on various graph analytic tasks.
Resultant: Incremental Effectiveness on Likelihood for Unsupervised Out-of-Distribution Detection
Sep 05, 2024



Unsupervised out-of-distribution (U-OOD) detection is to identify OOD data samples with a detector trained solely on unlabeled in-distribution (ID) data. The likelihood function estimated by a deep generative model (DGM) could be a natural detector, but its performance is limited in some popular "hard" benchmarks, such as FashionMNIST (ID) vs. MNIST (OOD). Recent studies have developed various detectors based on DGMs to move beyond likelihood. However, despite their success on "hard" benchmarks, most of them struggle to consistently surpass or match the performance of likelihood on some "non-hard" cases, such as SVHN (ID) vs. CIFAR10 (OOD) where likelihood could be a nearly perfect detector. Therefore, we appeal for more attention to incremental effectiveness on likelihood, i.e., whether a method could always surpass or at least match the performance of likelihood in U-OOD detection. We first investigate the likelihood of variational DGMs and find its detection performance could be improved in two directions: i) alleviating latent distribution mismatch, and ii) calibrating the dataset entropy-mutual integration. Then, we apply two techniques for each direction, specifically post-hoc prior and dataset entropy-mutual calibration. The final method, named Resultant, combines these two directions for better incremental effectiveness compared to either technique alone. Experimental results demonstrate that the Resultant could be a new state-of-the-art U-OOD detector while maintaining incremental effectiveness on likelihood in a wide range of tasks.
MacroHFT: Memory Augmented Context-aware Reinforcement Learning On High Frequency Trading
Jun 20, 2024



High-frequency trading (HFT) that executes algorithmic trading in short time scales, has recently occupied the majority of cryptocurrency market. Besides traditional quantitative trading methods, reinforcement learning (RL) has become another appealing approach for HFT due to its terrific ability of handling high-dimensional financial data and solving sophisticated sequential decision-making problems, \emph{e.g.,} hierarchical reinforcement learning (HRL) has shown its promising performance on second-level HFT by training a router to select only one sub-agent from the agent pool to execute the current transaction. However, existing RL methods for HFT still have some defects: 1) standard RL-based trading agents suffer from the overfitting issue, preventing them from making effective policy adjustments based on financial context; 2) due to the rapid changes in market conditions, investment decisions made by an individual agent are usually one-sided and highly biased, which might lead to significant loss in extreme markets. To tackle these problems, we propose a novel Memory Augmented Context-aware Reinforcement learning method On HFT, \emph{a.k.a.} MacroHFT, which consists of two training phases: 1) we first train multiple types of sub-agents with the market data decomposed according to various financial indicators, specifically market trend and volatility, where each agent owns a conditional adapter to adjust its trading policy according to market conditions; 2) then we train a hyper-agent to mix the decisions from these sub-agents and output a consistently profitable meta-policy to handle rapid market fluctuations, equipped with a memory mechanism to enhance the capability of decision-making. Extensive experiments on various cryptocurrency markets demonstrate that MacroHFT can achieve state-of-the-art performance on minute-level trading tasks.
Q*: Improving Multi-step Reasoning for LLMs with Deliberative Planning
Jun 20, 2024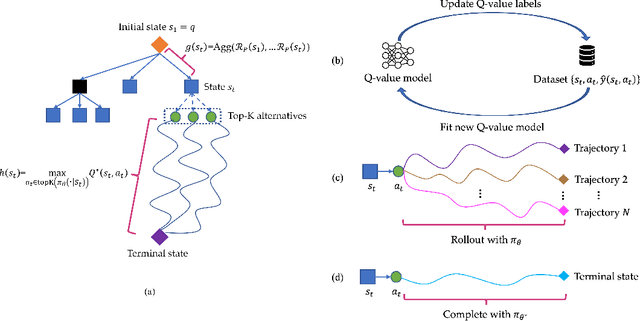
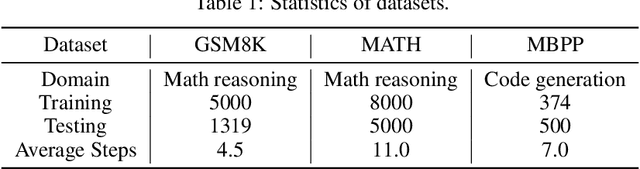
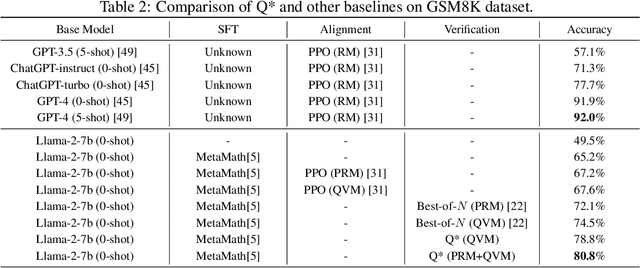
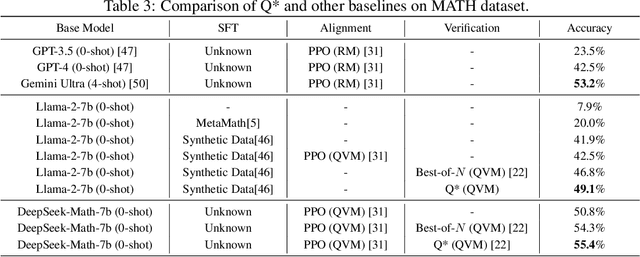
Large Language Models (LLMs) have demonstrated impressive capability in many nature language tasks. However, the auto-regressive generation process makes LLMs prone to produce errors, hallucinations and inconsistent statements when performing multi-step reasoning. In this paper, we aim to alleviate the pathology by introducing Q*, a general, versatile and agile framework for guiding LLMs decoding process with deliberative planning. By learning a plug-and-play Q-value model as heuristic function, our Q* can effectively guide LLMs to select the most promising next step without fine-tuning LLMs for each task, which avoids the significant computational overhead and potential risk of performance degeneration on other tasks. Extensive experiments on GSM8K, MATH and MBPP confirm the superiority of our method.