 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMars-PO: Multi-Agent Reasoning System Preference Optimization
Nov 28, 2024



Mathematical reasoning is a fundamental capability for large language models (LLMs), yet achieving high performance in this domain remains a significant challenge. The auto-regressive generation process often makes LLMs susceptible to errors, hallucinations, and inconsistencies, particularly during multi-step reasoning. In this paper, we propose Mars-PO, a novel framework to improve the mathematical reasoning capabilities of LLMs through a multi-agent system. It combines high-quality outputs from multiple agents into a hybrid positive sample set and pairs them with agent-specific negative samples to construct robust preference pairs for training. By aligning agents with shared positive samples while addressing individual weaknesses, Mars-PO achieves substantial performance improvements on mathematical reasoning benchmarks. For example, it increases the accuracy on the MATH benchmark of the state-of-the-art instruction-tuned LLM, Llama3.1-8B-Instruct, from 50.38% to 57.82%. Experimental results further demonstrate that our method consistently outperforms other baselines, such as supervised fine-tuning, vanilla DPO, and its enhanced versions, highlighting the effectiveness of our approach.
Mercury: An Automated Remote Side-channel Attack to Nvidia Deep Learning Accelerator
Aug 02, 2023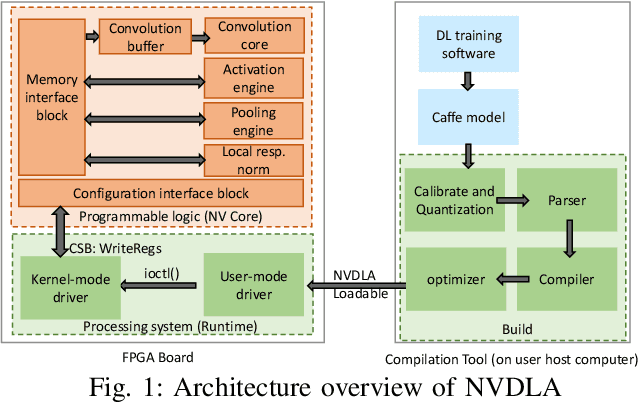
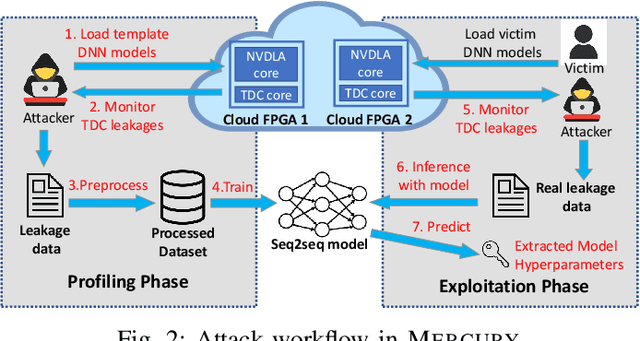
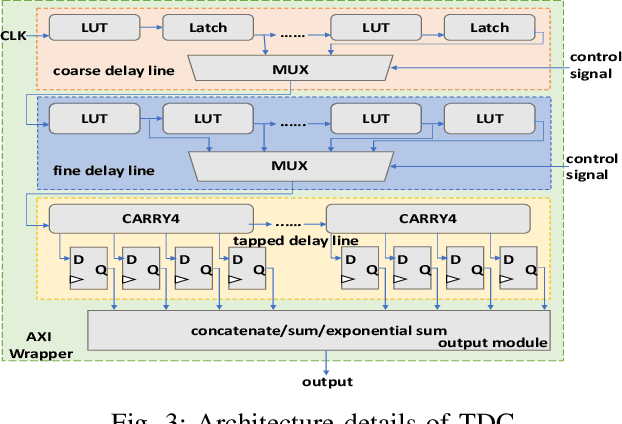
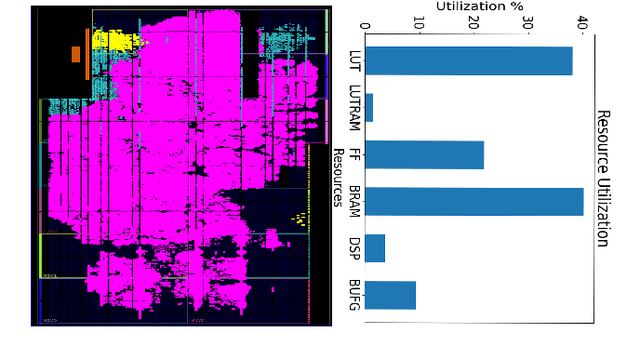
DNN accelerators have been widely deployed in many scenarios to speed up the inference process and reduce the energy consumption. One big concern about the usage of the accelerators is the confidentiality of the deployed models: model inference execution on the accelerators could leak side-channel information, which enables an adversary to preciously recover the model details. Such model extraction attacks can not only compromise the intellectual property of DNN models, but also facilitate some adversarial attacks. Although previous works have demonstrated a number of side-channel techniques to extract models from DNN accelerators, they are not practical for two reasons. (1) They only target simplified accelerator implementations, which have limited practicality in the real world. (2) They require heavy human analysis and domain knowledge. To overcome these limitations, this paper presents Mercury, the first automated remote side-channel attack against the off-the-shelf Nvidia DNN accelerator. The key insight of Mercury is to model the side-channel extraction process as a sequence-to-sequence problem. The adversary can leverage a time-to-digital converter (TDC) to remotely collect the power trace of the target model's inference. Then he uses a learning model to automatically recover the architecture details of the victim model from the power trace without any prior knowledge. The adversary can further use the attention mechanism to localize the leakage points that contribute most to the attack. Evaluation results indicate that Mercury can keep the error rate of model extraction below 1%.
ShiftNAS: Towards Automatic Generation of Advanced Mulitplication-Less Neural Networks
Apr 07, 2022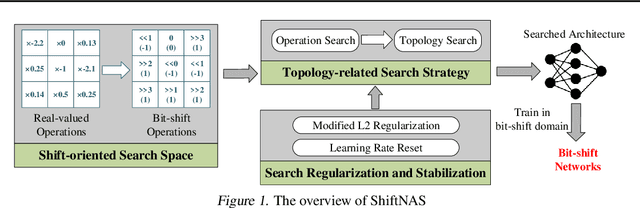
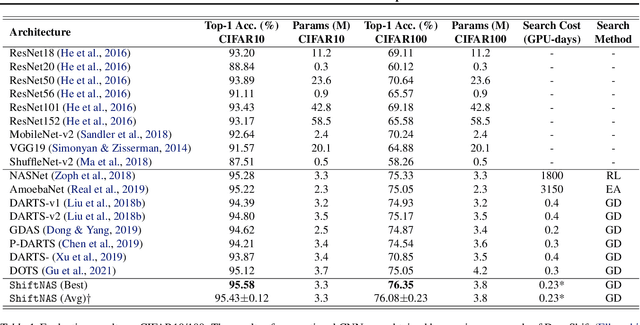
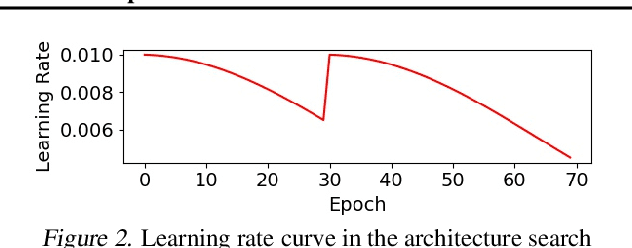
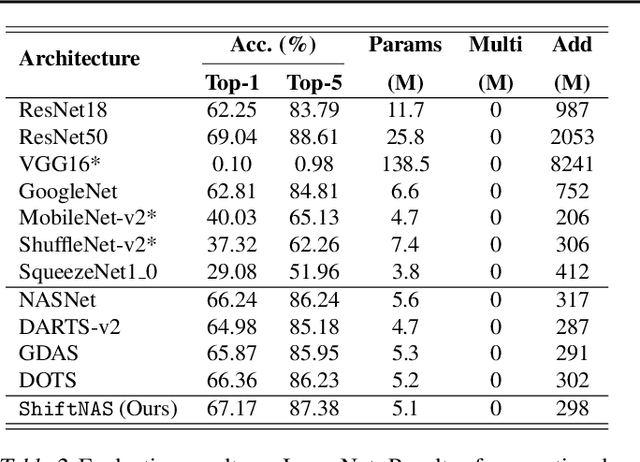
Multiplication-less neural networks significantly reduce the time and energy cost on the hardware platform, as the compute-intensive multiplications are replaced with lightweight bit-shift operations. However, existing bit-shift networks are all directly transferred from state-of-the-art convolutional neural networks (CNNs), which lead to non-negligible accuracy drop or even failure of model convergence. To combat this, we propose ShiftNAS, the first framework tailoring Neural Architecture Search (NAS) to substantially reduce the accuracy gap between bit-shift neural networks and their real-valued counterparts. Specifically, we pioneer dragging NAS into a shift-oriented search space and endow it with the robust topology-related search strategy and custom regularization and stabilization. As a result, our ShiftNAS breaks through the incompatibility of traditional NAS methods for bit-shift neural networks and achieves more desirable performance in terms of accuracy and convergence. Extensive experiments demonstrate that ShiftNAS sets a new state-of-the-art for bit-shift neural networks, where the accuracy increases (1.69-8.07)% on CIFAR10, (5.71-18.09)% on CIFAR100 and (4.36-67.07)% on ImageNet, especially when many conventional CNNs fail to converge on ImageNet with bit-shift weights.