 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-VLA: Event-Augmented Vision-Language-Action Model for Dark and Blurred Scenes
Apr 06, 2026Robotic Vision-Language-Action (VLA) models generalize well for open-ended manipulation, but their perception is fragile under sensing-stage degradations such as extreme low light, motion blur, and black clipping. We present E-VLA, an event-augmented VLA framework that improves manipulation robustness when conventional frame-based vision becomes unreliable. Instead of reconstructing images from events, E-VLA directly leverages motion and structural cues in event streams to preserve semantic perception and perception-action consistency under adverse conditions. We build an open-source teleoperation platform with a DAVIS346 event camera and collect a real-world synchronized RGB-event-action manipulation dataset across diverse tasks and illumination settings. We also propose lightweight, pretrained-compatible event integration strategies and study event windowing and fusion for stable deployment. Experiments show that even a simple parameter-free fusion, i.e., overlaying accumulated event maps onto RGB images, could substantially improve robustness in dark and blur-heavy scenes: on Pick-Place at 20 lux, success increases from 0% (image-only) to 60% with overlay fusion and to 90% with our event adapter; under severe motion blur (1000 ms exposure), Pick-Place improves from 0% to 20-25%, and Sorting from 5% to 32.5%. Overall, E-VLA provides systematic evidence that event-driven perception can be effectively integrated into VLA models, pointing toward robust embodied intelligence beyond conventional frame-based imaging. Code and dataset will be available at https://github.com/JJayzee/E-VLA.
OneOcc: Semantic Occupancy Prediction for Legged Robots with a Single Panoramic Camera
Nov 05, 2025Robust 3D semantic occupancy is crucial for legged/humanoid robots, yet most semantic scene completion (SSC) systems target wheeled platforms with forward-facing sensors. We present OneOcc, a vision-only panoramic SSC framework designed for gait-introduced body jitter and 360{\deg} continuity. OneOcc combines: (i) Dual-Projection fusion (DP-ER) to exploit the annular panorama and its equirectangular unfolding, preserving 360{\deg} continuity and grid alignment; (ii) Bi-Grid Voxelization (BGV) to reason in Cartesian and cylindrical-polar spaces, reducing discretization bias and sharpening free/occupied boundaries; (iii) a lightweight decoder with Hierarchical AMoE-3D for dynamic multi-scale fusion and better long-range/occlusion reasoning; and (iv) plug-and-play Gait Displacement Compensation (GDC) learning feature-level motion correction without extra sensors. We also release two panoramic occupancy benchmarks: QuadOcc (real quadruped, first-person 360{\deg}) and Human360Occ (H3O) (CARLA human-ego 360{\deg} with RGB, Depth, semantic occupancy; standardized within-/cross-city splits). OneOcc sets new state-of-the-art (SOTA): on QuadOcc it beats strong vision baselines and popular LiDAR ones; on H3O it gains +3.83 mIoU (within-city) and +8.08 (cross-city). Modules are lightweight, enabling deployable full-surround perception for legged/humanoid robots. Datasets and code will be publicly available at https://github.com/MasterHow/OneOcc.
Disrupting Vision-Language Model-Driven Navigation Services via Adversarial Object Fusion
May 29, 2025We present Adversarial Object Fusion (AdvOF), a novel attack framework targeting vision-and-language navigation (VLN) agents in service-oriented environments by generating adversarial 3D objects. While foundational models like Large Language Models (LLMs) and Vision Language Models (VLMs) have enhanced service-oriented navigation systems through improved perception and decision-making, their integration introduces vulnerabilities in mission-critical service workflows. Existing adversarial attacks fail to address service computing contexts, where reliability and quality-of-service (QoS) are paramount. We utilize AdvOF to investigate and explore the impact of adversarial environments on the VLM-based perception module of VLN agents. In particular, AdvOF first precisely aggregates and aligns the victim object positions in both 2D and 3D space, defining and rendering adversarial objects. Then, we collaboratively optimize the adversarial object with regularization between the adversarial and victim object across physical properties and VLM perceptions. Through assigning importance weights to varying views, the optimization is processed stably and multi-viewedly by iterative fusions from local updates and justifications. Our extensive evaluations demonstrate AdvOF can effectively degrade agent performance under adversarial conditions while maintaining minimal interference with normal navigation tasks. This work advances the understanding of service security in VLM-powered navigation systems, providing computational foundations for robust service composition in physical-world deployments.
Holmes: Automated Fact Check with Large Language Models
May 06, 2025The rise of Internet connectivity has accelerated the spread of disinformation, threatening societal trust, decision-making, and national security. Disinformation has evolved from simple text to complex multimodal forms combining images and text, challenging existing detection methods. Traditional deep learning models struggle to capture the complexity of multimodal disinformation. Inspired by advances in AI, this study explores using Large Language Models (LLMs) for automated disinformation detection. The empirical study shows that (1) LLMs alone cannot reliably assess the truthfulness of claims; (2) providing relevant evidence significantly improves their performance; (3) however, LLMs cannot autonomously search for accurate evidence. To address this, we propose Holmes, an end-to-end framework featuring a novel evidence retrieval method that assists LLMs in collecting high-quality evidence. Our approach uses (1) LLM-powered summarization to extract key information from open sources and (2) a new algorithm and metrics to evaluate evidence quality. Holmes enables LLMs to verify claims and generate justifications effectively. Experiments show Holmes achieves 88.3% accuracy on two open-source datasets and 90.2% in real-time verification tasks. Notably, our improved evidence retrieval boosts fact-checking accuracy by 30.8% over existing methods
Event-aided Semantic Scene Completion
Feb 04, 2025



Autonomous driving systems rely on robust 3D scene understanding. Recent advances in Semantic Scene Completion (SSC) for autonomous driving underscore the limitations of RGB-based approaches, which struggle under motion blur, poor lighting, and adverse weather. Event cameras, offering high dynamic range and low latency, address these challenges by providing asynchronous data that complements RGB inputs. We present DSEC-SSC, the first real-world benchmark specifically designed for event-aided SSC, which includes a novel 4D labeling pipeline for generating dense, visibility-aware labels that adapt dynamically to object motion. Our proposed RGB-Event fusion framework, EvSSC, introduces an Event-aided Lifting Module (ELM) that effectively bridges 2D RGB-Event features to 3D space, enhancing view transformation and the robustness of 3D volume construction across SSC models. Extensive experiments on DSEC-SSC and simulated SemanticKITTI-E demonstrate that EvSSC is adaptable to both transformer-based and LSS-based SSC architectures. Notably, evaluations on SemanticKITTI-C demonstrate that EvSSC achieves consistently improved prediction accuracy across five degradation modes and both In-domain and Out-of-domain settings, achieving up to a 52.5% relative improvement in mIoU when the image sensor partially fails. Additionally, we quantitatively and qualitatively validate the superiority of EvSSC under motion blur and extreme weather conditions, where autonomous driving is challenged. The established datasets and our codebase will be made publicly at https://github.com/Pandapan01/EvSSC.
Picky LLMs and Unreliable RMs: An Empirical Study on Safety Alignment after Instruction Tuning
Feb 03, 2025Large language models (LLMs) have emerged as powerful tools for addressing a wide range of general inquiries and tasks. Despite this, fine-tuning aligned LLMs on smaller, domain-specific datasets, critical to adapting them to specialized tasks, can inadvertently degrade their safety alignment, even when the datasets are benign. This phenomenon makes models more susceptible to providing inappropriate responses. In this study, we systematically examine the factors contributing to safety alignment degradation in benign fine-tuning scenarios. Our analysis identifies three critical factors affecting aligned LLMs: answer structure, identity calibration, and role-play. Additionally, we evaluate the reliability of state-of-the-art reward models (RMs), which are often used to guide alignment processes. Our findings reveal that these RMs frequently fail to accurately reflect human preferences regarding safety, underscoring their limitations in practical applications. By uncovering these challenges, our work highlights the complexities of maintaining safety alignment during fine-tuning and offers guidance to help developers balance utility and safety in LLMs. Datasets and fine-tuning code used in our experiments can be found in https://github.com/GuanlinLee/llm_instruction_tuning.
Preventing Non-intrusive Load Monitoring Privacy Invasion: A Precise Adversarial Attack Scheme for Networked Smart Meters
Dec 22, 2024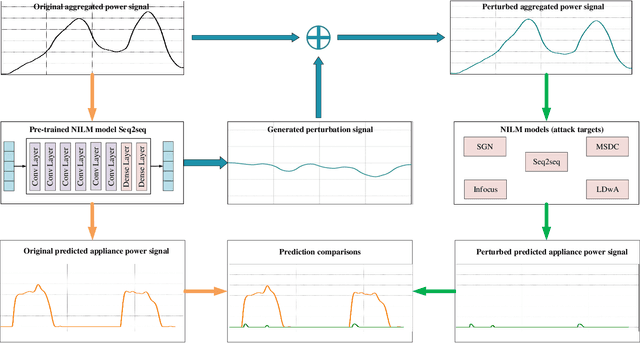

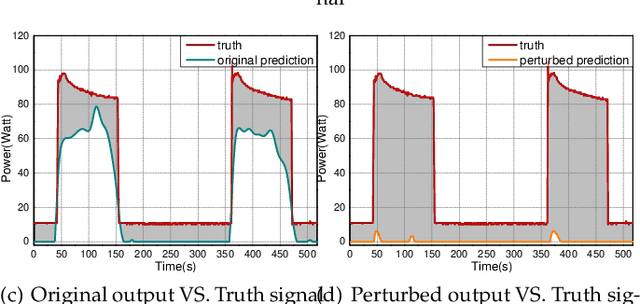
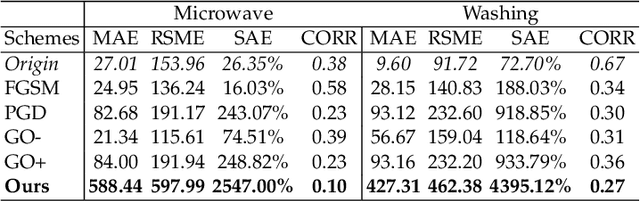
Smart grid, through networked smart meters employing the non-intrusive load monitoring (NILM) technique, can considerably discern the usage patterns of residential appliances. However, this technique also incurs privacy leakage. To address this issue, we propose an innovative scheme based on adversarial attack in this paper. The scheme effectively prevents NILM models from violating appliance-level privacy, while also ensuring accurate billing calculation for users. To achieve this objective, we overcome two primary challenges. First, as NILM models fall under the category of time-series regression models, direct application of traditional adversarial attacks designed for classification tasks is not feasible. To tackle this issue, we formulate a novel adversarial attack problem tailored specifically for NILM and providing a theoretical foundation for utilizing the Jacobian of the NILM model to generate imperceptible perturbations. Leveraging the Jacobian, our scheme can produce perturbations, which effectively misleads the signal prediction of NILM models to safeguard users' appliance-level privacy. The second challenge pertains to fundamental utility requirements, where existing adversarial attack schemes struggle to achieve accurate billing calculation for users. To handle this problem, we introduce an additional constraint, mandating that the sum of added perturbations within a billing period must be precisely zero. Experimental validation on real-world power datasets REDD and UK-DALE demonstrates the efficacy of our proposed solutions, which can significantly amplify the discrepancy between the output of the targeted NILM model and the actual power signal of appliances, and enable accurate billing at the same time. Additionally, our solutions exhibit transferability, making the generated perturbation signal from one target model applicable to other diverse NILM models.
TransTroj: Transferable Backdoor Attacks to Pre-trained Models via Embedding Indistinguishability
Jan 29, 2024Pre-trained models (PTMs) are extensively utilized in various downstream tasks. Adopting untrusted PTMs may suffer from backdoor attacks, where the adversary can compromise the downstream models by injecting backdoors into the PTM. However, existing backdoor attacks to PTMs can only achieve partially task-agnostic and the embedded backdoors are easily erased during the fine-tuning process. In this paper, we propose a novel transferable backdoor attack, TransTroj, to simultaneously meet functionality-preserving, durable, and task-agnostic. In particular, we first formalize transferable backdoor attacks as the indistinguishability problem between poisoned and clean samples in the embedding space. We decompose the embedding indistinguishability into pre- and post-indistinguishability, representing the similarity of the poisoned and reference embeddings before and after the attack. Then, we propose a two-stage optimization that separately optimizes triggers and victim PTMs to achieve embedding indistinguishability. We evaluate TransTroj on four PTMs and six downstream tasks. Experimental results show that TransTroj significantly outperforms SOTA task-agnostic backdoor attacks (18%$\sim$99%, 68% on average) and exhibits superior performance under various system settings. The code is available at https://github.com/haowang-cqu/TransTroj .
Rethinking Adversarial Training with Neural Tangent Kernel
Dec 04, 2023



Adversarial training (AT) is an important and attractive topic in deep learning security, exhibiting mysteries and odd properties. Recent studies of neural network training dynamics based on Neural Tangent Kernel (NTK) make it possible to reacquaint AT and deeply analyze its properties. In this paper, we perform an in-depth investigation of AT process and properties with NTK, such as NTK evolution. We uncover three new findings that are missed in previous works. First, we disclose the impact of data normalization on AT and the importance of unbiased estimators in batch normalization layers. Second, we experimentally explore the kernel dynamics and propose more time-saving AT methods. Third, we study the spectrum feature inside the kernel to address the catastrophic overfitting problem. To the best of our knowledge, it is the first work leveraging the observations of kernel dynamics to improve existing AT methods.
Mercury: An Automated Remote Side-channel Attack to Nvidia Deep Learning Accelerator
Aug 02, 2023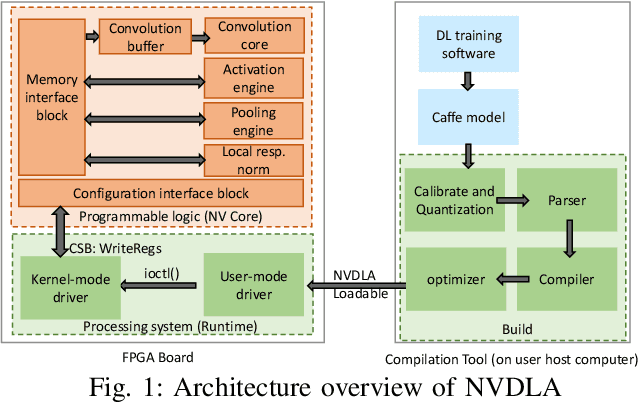
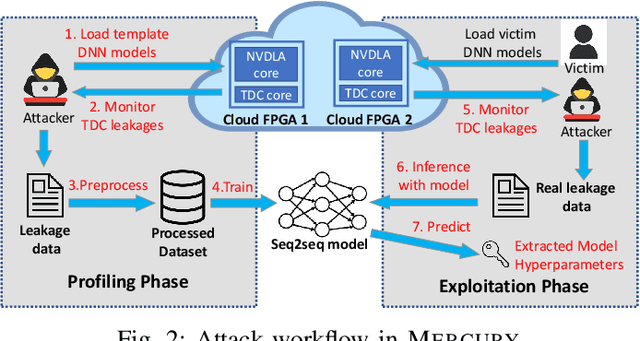
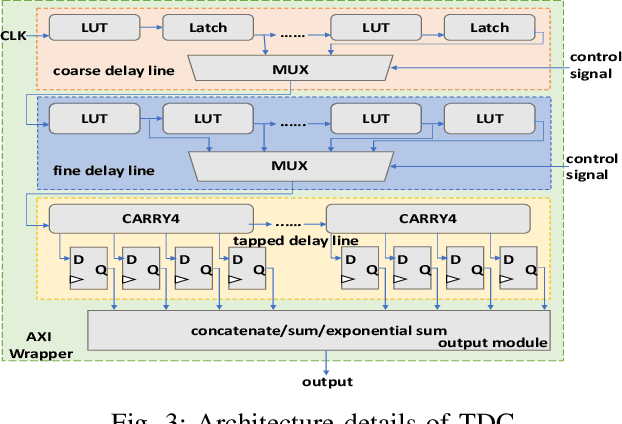
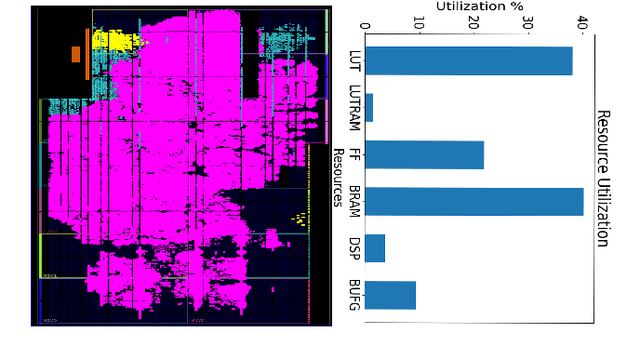
DNN accelerators have been widely deployed in many scenarios to speed up the inference process and reduce the energy consumption. One big concern about the usage of the accelerators is the confidentiality of the deployed models: model inference execution on the accelerators could leak side-channel information, which enables an adversary to preciously recover the model details. Such model extraction attacks can not only compromise the intellectual property of DNN models, but also facilitate some adversarial attacks. Although previous works have demonstrated a number of side-channel techniques to extract models from DNN accelerators, they are not practical for two reasons. (1) They only target simplified accelerator implementations, which have limited practicality in the real world. (2) They require heavy human analysis and domain knowledge. To overcome these limitations, this paper presents Mercury, the first automated remote side-channel attack against the off-the-shelf Nvidia DNN accelerator. The key insight of Mercury is to model the side-channel extraction process as a sequence-to-sequence problem. The adversary can leverage a time-to-digital converter (TDC) to remotely collect the power trace of the target model's inference. Then he uses a learning model to automatically recover the architecture details of the victim model from the power trace without any prior knowledge. The adversary can further use the attention mechanism to localize the leakage points that contribute most to the attack. Evaluation results indicate that Mercury can keep the error rate of model extraction below 1%.