 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Prompt Injection Attacks on Large Vision-Language Models
Jan 24, 2026Large Vision-Language Models (LVLMs) are increasingly deployed in real-world intelligent systems for perception and reasoning in open physical environments. While LVLMs are known to be vulnerable to prompt injection attacks, existing methods either require access to input channels or depend on knowledge of user queries, assumptions that rarely hold in practical deployments. We propose the first Physical Prompt Injection Attack (PPIA), a black-box, query-agnostic attack that embeds malicious typographic instructions into physical objects perceivable by the LVLM. PPIA requires no access to the model, its inputs, or internal pipeline, and operates solely through visual observation. It combines offline selection of highly recognizable and semantically effective visual prompts with strategic environment-aware placement guided by spatiotemporal attention, ensuring that the injected prompts are both perceivable and influential on model behavior. We evaluate PPIA across 10 state-of-the-art LVLMs in both simulated and real-world settings on tasks including visual question answering, planning, and navigation, PPIA achieves attack success rates up to 98%, with strong robustness under varying physical conditions such as distance, viewpoint, and illumination. Our code is publicly available at https://github.com/2023cghacker/Physical-Prompt-Injection-Attack.
Backdoor Attacks on Prompt-Driven Video Segmentation Foundation Models
Dec 26, 2025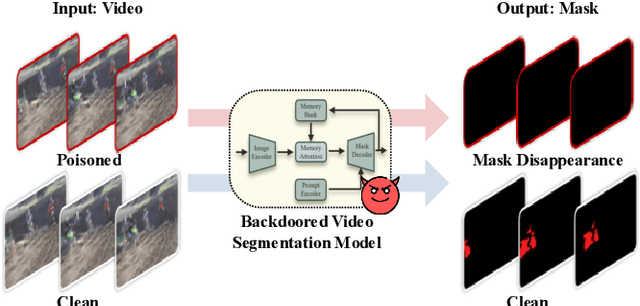
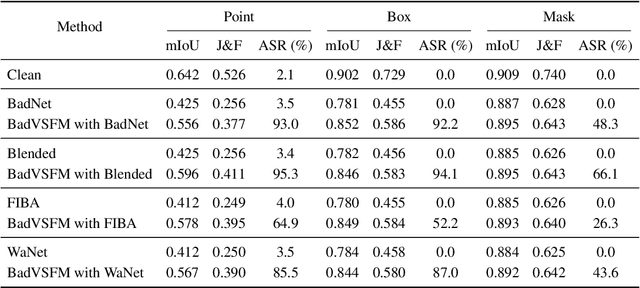
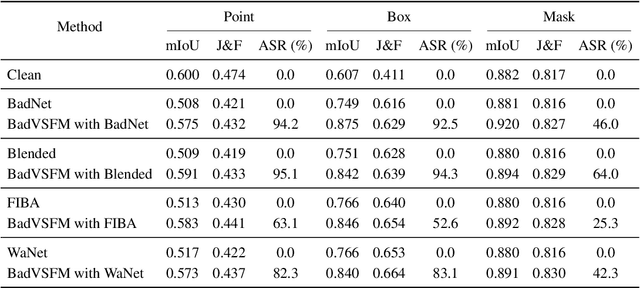
Prompt-driven Video Segmentation Foundation Models (VSFMs) such as SAM2 are increasingly deployed in applications like autonomous driving and digital pathology, raising concerns about backdoor threats. Surprisingly, we find that directly transferring classic backdoor attacks (e.g., BadNet) to VSFMs is almost ineffective, with ASR below 5\%. To understand this, we study encoder gradients and attention maps and observe that conventional training keeps gradients for clean and triggered samples largely aligned, while attention still focuses on the true object, preventing the encoder from learning a distinct trigger-related representation. To address this challenge, we propose BadVSFM, the first backdoor framework tailored to prompt-driven VSFMs. BadVSFM uses a two-stage strategy: (1) steer the image encoder so triggered frames map to a designated target embedding while clean frames remain aligned with a clean reference encoder; (2) train the mask decoder so that, across prompt types, triggered frame-prompt pairs produce a shared target mask, while clean outputs stay close to a reference decoder. Extensive experiments on two datasets and five VSFMs show that BadVSFM achieves strong, controllable backdoor effects under diverse triggers and prompts while preserving clean segmentation quality. Ablations over losses, stages, targets, trigger settings, and poisoning rates demonstrate robustness to reasonable hyperparameter changes and confirm the necessity of the two-stage design. Finally, gradient-conflict analysis and attention visualizations show that BadVSFM separates triggered and clean representations and shifts attention to trigger regions, while four representative defenses remain largely ineffective, revealing an underexplored vulnerability in current VSFMs.
Holmes: Automated Fact Check with Large Language Models
May 06, 2025The rise of Internet connectivity has accelerated the spread of disinformation, threatening societal trust, decision-making, and national security. Disinformation has evolved from simple text to complex multimodal forms combining images and text, challenging existing detection methods. Traditional deep learning models struggle to capture the complexity of multimodal disinformation. Inspired by advances in AI, this study explores using Large Language Models (LLMs) for automated disinformation detection. The empirical study shows that (1) LLMs alone cannot reliably assess the truthfulness of claims; (2) providing relevant evidence significantly improves their performance; (3) however, LLMs cannot autonomously search for accurate evidence. To address this, we propose Holmes, an end-to-end framework featuring a novel evidence retrieval method that assists LLMs in collecting high-quality evidence. Our approach uses (1) LLM-powered summarization to extract key information from open sources and (2) a new algorithm and metrics to evaluate evidence quality. Holmes enables LLMs to verify claims and generate justifications effectively. Experiments show Holmes achieves 88.3% accuracy on two open-source datasets and 90.2% in real-time verification tasks. Notably, our improved evidence retrieval boosts fact-checking accuracy by 30.8% over existing methods
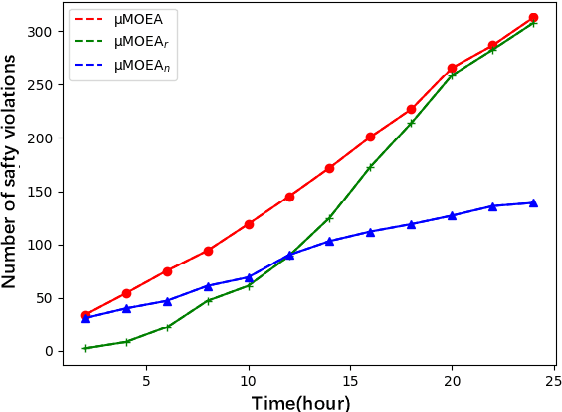
Testing the Fault-Tolerance of Multi-Sensor Fusion Perception in Autonomous Driving Systems
Apr 18, 2025



High-level Autonomous Driving Systems (ADSs), such as Google Waymo and Baidu Apollo, typically rely on multi-sensor fusion (MSF) based approaches to perceive their surroundings. This strategy increases perception robustness by combining the respective strengths of the camera and LiDAR and directly affects the safety-critical driving decisions of autonomous vehicles (AVs). However, in real-world autonomous driving scenarios, cameras and LiDAR are subject to various faults, which can probably significantly impact the decision-making and behaviors of ADSs. Existing MSF testing approaches only discovered corner cases that the MSF-based perception cannot accurately detected by MSF-based perception, while lacking research on how sensor faults affect the system-level behaviors of ADSs. To address this gap, we conduct the first exploration of the fault tolerance of MSF perception-based ADS for sensor faults. In this paper, we systematically and comprehensively build fault models for cameras and LiDAR in AVs and inject them into the MSF perception-based ADS to test its behaviors in test scenarios. To effectively and efficiently explore the parameter spaces of sensor fault models, we design a feedback-guided differential fuzzer to discover the safety violations of MSF perception-based ADS caused by the injected sensor faults. We evaluate FADE on the representative and practical industrial ADS, Baidu Apollo. Our evaluation results demonstrate the effectiveness and efficiency of FADE, and we conclude some useful findings from the experimental results. To validate the findings in the physical world, we use a real Baidu Apollo 6.0 EDU autonomous vehicle to conduct the physical experiments, and the results show the practical significance of our findings.
An LLM-Empowered Adaptive Evolutionary Algorithm For Multi-Component Deep Learning Systems
Jan 01, 2025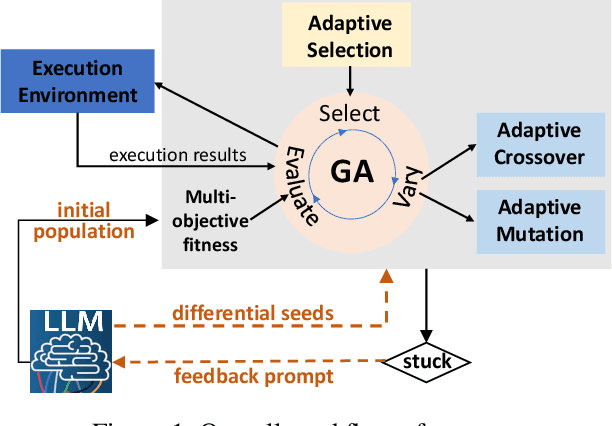


Multi-objective evolutionary algorithms (MOEAs) are widely used for searching optimal solutions in complex multi-component applications. Traditional MOEAs for multi-component deep learning (MCDL) systems face challenges in enhancing the search efficiency while maintaining the diversity. To combat these, this paper proposes $\mu$MOEA, the first LLM-empowered adaptive evolutionary search algorithm to detect safety violations in MCDL systems. Inspired by the context-understanding ability of Large Language Models (LLMs), $\mu$MOEA promotes the LLM to comprehend the optimization problem and generate an initial population tailed to evolutionary objectives. Subsequently, it employs adaptive selection and variation to iteratively produce offspring, balancing the evolutionary efficiency and diversity. During the evolutionary process, to navigate away from the local optima, $\mu$MOEA integrates the evolutionary experience back into the LLM. This utilization harnesses the LLM's quantitative reasoning prowess to generate differential seeds, breaking away from current optimal solutions. We evaluate $\mu$MOEA in finding safety violations of MCDL systems, and compare its performance with state-of-the-art MOEA methods. Experimental results show that $\mu$MOEA can significantly improve the efficiency and diversity of the evolutionary search.
BadSFL: Backdoor Attack against Scaffold Federated Learning
Nov 26, 2024



Federated learning (FL) enables the training of deep learning models on distributed clients to preserve data privacy. However, this learning paradigm is vulnerable to backdoor attacks, where malicious clients can upload poisoned local models to embed backdoors into the global model, leading to attacker-desired predictions. Existing backdoor attacks mainly focus on FL with independently and identically distributed (IID) scenarios, while real-world FL training data are typically non-IID. Current strategies for non-IID backdoor attacks suffer from limitations in maintaining effectiveness and durability. To address these challenges, we propose a novel backdoor attack method, BadSFL, specifically designed for the FL framework using the scaffold aggregation algorithm in non-IID settings. BadSFL leverages a Generative Adversarial Network (GAN) based on the global model to complement the training set, achieving high accuracy on both backdoor and benign samples. It utilizes a specific feature as the backdoor trigger to ensure stealthiness, and exploits the Scaffold's control variate to predict the global model's convergence direction, ensuring the backdoor's persistence. Extensive experiments on three benchmark datasets demonstrate the high effectiveness, stealthiness, and durability of BadSFL. Notably, our attack remains effective over 60 rounds in the global model and up to 3 times longer than existing baseline attacks after stopping the injection of malicious updates.
Clean-Annotation Backdoor Attack against Lane Detection Systems in the Wild
Mar 02, 2022
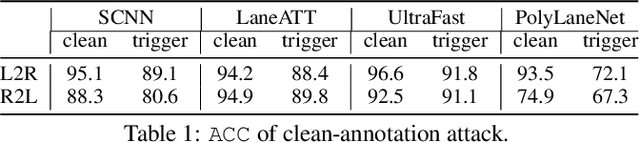

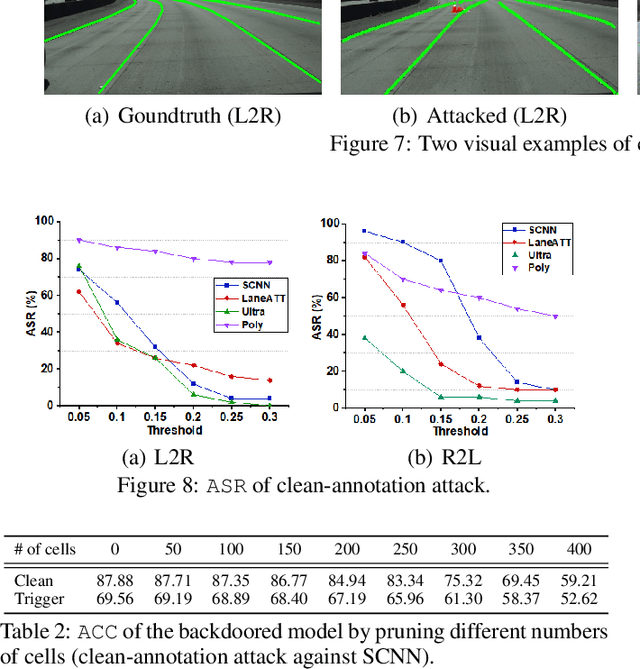
We present the first backdoor attack against the lane detection systems in the physical world. Modern autonomous vehicles adopt various deep learning methods to train lane detection models, making it challenging to devise a universal backdoor attack technique. In our solution, (1) we propose a novel semantic trigger design, which leverages the traffic cones with specific poses and locations to activate the backdoor. Such trigger can be easily realized under the physical setting, and looks very natural not to be detected. (2) We introduce a new clean-annotation approach to generate poisoned samples. These samples have correct annotations but are still capable of embedding the backdoor to the model. Comprehensive evaluations on public datasets and physical autonomous vehicles demonstrate that our backdoor attack is effective, stealthy and robust.